| SOCR ≫ | DSPA ≫ | DSPA2 Topics ≫ |
DSPA2: Data Science and Predictive Analytics (UMich HS650)
Deep Learning, Neural Networks (Part 1)
Deep Learning, Neural Networks (Part 1)
SOCR/MIDAS (Ivo Dinov)
SOCR/MIDAS (Ivo Dinov)
May 2026
This DSPA2 module represents Part 1 of the DSPA2 Chapter 14 (Deep Learning, Neural Networks). Learners that complete this first part are encouraged to proceed to Part 2 of the DSPA2 Chapter 14 (Deep Learning, Neural Networks), which starts with transfer learning, and then continue with Part 3 of the DSPA2 Chapter 14 (Deep Learning, Neural Networks) and Part 4 of the DSPA2 Chapter 14 (Deep Learning, Neural Networks).
1 Deep Learning Neural Networks
Deep learning is a special branch of machine learning using a collage of algorithms to model high-level motifs in data. Deep learning resembles the biological communications between brain neurons in the central nervous system (CNS), where synthetic graphs represent the CNS network as nodes/states and connections/edges between them. For instance, in a simple synthetic network consisting of a pair of connected nodes, an output sent by one node is received by the other as an input signal. When more nodes are present in the network, they may be arranged in multiple levels (like a multiscale object) where the \(i^{th}\) layer output serves as the input of the next \((i+1)^{st}\) layer. The signal is manipulated at each layer and sent as a layer output downstream and interpreted as an input to the next, \((i+1)^{st}\) layer, and so forth. Deep learning relies on multiple layers of nodes and many edges linking the nodes forming input/output (I/O) layered grids representing a multiscale processing network. At each layer, linear and non-linear transformations are converting inputs into outputs.
In this chapter, we explore the R-based deep neural network learning and demonstrate state-of-the-art deep learning models utilizing CPU and GPU for fast training (learning) and testing (validation). Other powerful deep learning frameworks include TensorFlow, Theano, Caffe, Torch, CNTK and Keras.
Neural Networks vs. Deep Learning: Deep Learning is a machine learning strategy that learns a deep multi-level hierarchical representation of the affinities and motifs in the dataset. Machine learning Neural Nets tend to use shallower network models. Although there are no formal restrictions on the depth of the layers in a Neural Net, few layers are commonly utilized. Recent methodological, algorithmic, computational, infrastructure and service advances overcome previous limitations. In addition, the rise of Big Data accelerated the evolution of classical Neural Nets to Deep Neural Nets, which can now handle lots of layers and many hidden nodes per layer. The former is a precursor to the latter, however, there are also non-neural deep learning techniques. For example, syntactic pattern recognition methods and grammar induction discover hierarchies.
2 Deep Learning Training
Review Chapter 6 (Black Box Machine-Learning Methods: Neural Networks, Support Vector Machines, and Random Forests) prior to proceeding.
2.1 Perceptrons
A perceptron is an artificial analogue of a neuronal brain cell that calculates a weighted sum of the input values and outputs a thresholded version of that result. For a bivariate perceptron, \(P\), let’s denote the weights of the two inputs, \((X,Y)\) by \(A\) and \(B\), respectively. Then, the weighted sum could be represented as: \[W = A X + B Y.\]
At each layer \(l\), the weight matrix, \(W^{(l)}\), has the following properties:
- The number of rows of \(W^{(l)}\) equals the number of nodes/units in the previous \((l-1)^{st}\) layer, and
- The number of columns of \(W^{(l)}\) equals the number of units in the next \((l+1)^{st}\) layer.
Neuronal cells fire depending on the presynaptic inputs to the cell which causes constant fluctuations of the neuronal membrane - depolarizing or hyperpolarizing, i.e., the cell membrane potential rises or falls. Similarly, perceptrons rely on thresholding of the weight-averaged input signal, which for biological cells corresponds to voltage increases passing a critical threshold. Perceptrons output non-zero values only when the weighted sum exceeds a certain threshold \(C\). In terms of its input vector, \((X,Y)\), we can describe the output of each perceptron (\(P\)) by:
\[Output(P) = \left\{ \begin{array} {} 1, & if\ A X + B Y > C \\ 0, & if\ A X + B Y \leq C \end{array} \right. .\]
Feed-forward networks are constructed as layers of perceptrons where the first layer ingests the inputs and the last layer generates the network outputs. The intermediate (internal) layers are not directly connected to the external world, and are called hidden layers. In fully connected networks, each perceptron in one layer is connected to every perceptron on the next layer enabling information “fed forward” from one layer to the next. There are no connections between perceptrons in the same layer.
Multilayer perceptrons (fully-connected feed-forward neural networks)
consist of several fully-connected layers representing an
input matrix \(X_{n, m}\)
and a generated output matrix \(Y_{n, k}\). The input \(X_{n,m}\) is a matrix encoding the \(n\) cases and \(m\) features per case. The weight matrix
\(W_{m,k}^{(l)}\) for layer \(l\) has rows (\(i\)) corresponding to the weights leading
from all the units \(i\) in the
previous layer to all of the units \(j\) in the current layer.
The hidden size parameter \(k\), the weight matrix \(W_{m , k}\), and the bias vector \(b_{k}\) are used to compute the outputs at each layer:
\[Y_{n, k}^{(l)} =f_k^{(l)}\left ( X_{n, m}^{(l)} W_{m , k}^{(l)} +b_{k}^{(l)} \right ).\]
The role of the bias parameter is similar to the intercept term in
linear regression and helps improve the accuracy of prediction by
shifting the decision boundary along the \(Y\) axis. The outputs are fully-connected
layers that feed into an activation layer to perform
element-wise operations. Examples of activation
functions that transform real numbers to probability-like
values include:
- the sigmoid function, a special case of the logistic function, which converts real numbers to probabilities,
- the rectifier (
relu, Rectified Linear Unit) function, which outputs the \(\max(0, input)\), - the tanh (hyperbolic tangent function).
The final fully-connected layer may be hidden of a size equal to the
number of classes in the dataset and may be followed by a
softmax layer mapping the input into a probability score.
For example, if a size \({n\times m}\)
input is denoted by \(X_{n\times m}\),
then the probability scores may be obtained by the softmax
transformation function, which maps real valued vectors to vectors of
probabilities:
\[\left ( \frac{e^{x_{i,1}}}{\displaystyle\sum_{j=1}^m e^{x_{i,j}}},\ldots, \frac{e^{x_{i,m}}}{\displaystyle\sum_{j=1}^m e^{x_{i,j}}}\right ).\]
Below is a schematic of a fully-connected feed-forward neural network of nodes \[ \{ a_{j=node\ index, l=layer\ index} \}_{j=1, l=1}^{n_j, 4}.\]

The plot above illustrates the key elements in the calculations of the action potential, or activation function, and the corresponding training parameters:
\[{a}_{\textrm{node}=k,\textrm{layer}=l}=f\left(\sum \limits_i{w}_{k,i}^{(l)}\times {a}_i^{(l-1)}+{b}_k^{(l)}\right),\] where:
- \(f\) is the activation function, e.g., logistic function \(f(x) = \frac{1}{1+e^{-x}}\). It converts the aggregate weights at each node to probability values,
- \(w_{k,i}^l\) is the weight carried from the \(i^{th}\) element of the \((l-1)^{th}\) layer to the \(k^{th}\) element of the current \(l^{th}\) layer,
- \(b_{k}^l\) is the (residual) bias present in the \(k^{th}\) element in the \(l^{th}\) layer. This is the information not explained by the training model.
Using training data, these network parameters (weights) may be estimated using different techniques, e.g., using least squares, gradient descent methods, LASSO/Chapter 11, and many different numerical optimization schemes.
3 Biological Relevance
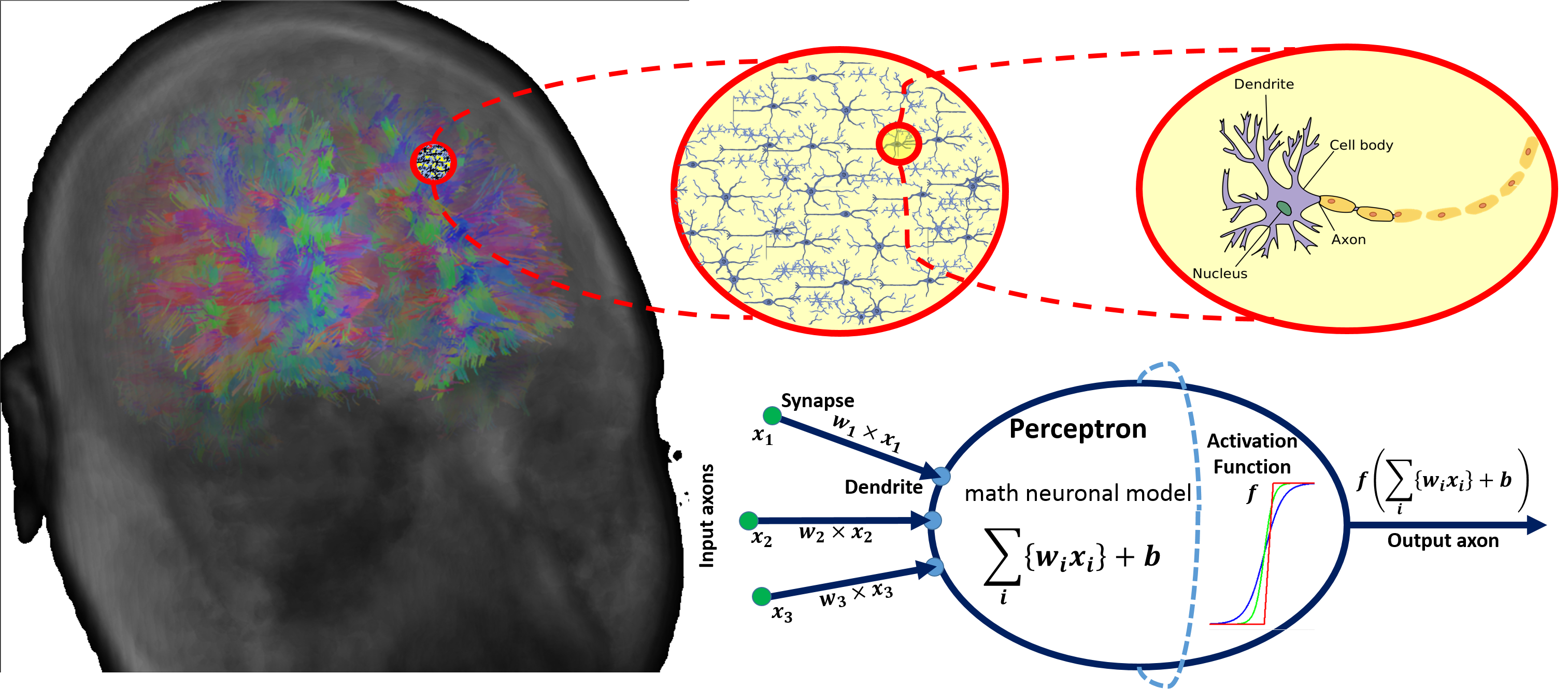
There are parallels between biology (neuronal cells) and the mathematical models (perceptrons) for neural network representation. The human brain contains about \(10^{11}\) neuronal cells connected by approximately \(10^{15}\) synapses forming the basis of our functional phenotypes. The schematic below illustrates some of the parallels between brain biology and the mathematical representation using synthetic neural nets. Every neuronal cell receives multi-channel (afferent) input from its dendrites, generates output signals and disseminates the results via its (efferent) axonal and synaptic connections to dendrites of other neurons.
The perceptron is a mathematical model of a neuronal cell that allows
us to explicitly determine algorithmic and computational protocols for
transforming input signals into output actions. For instance, a signal
arriving through an axon \(x_0\) is
modulated by some prior weight, e.g., synaptic strength, \(w_0\times x_0\). Internally, within the
neuronal cell, this input is aggregated (summed, or weight-averaged)
with inputs from all other axons. Brain plasticity suggests that
synaptic strengths (weight coefficients \(w\)) are enhanced by training and prior
experience. This learning process controls the direction and influence
of neurons on other neurons. Either excitatory (\(w>0\)) or inhibitory (\(w\leq 0\)) influences are possible.
Dendrites and axons carry signals to and from neurons, where the
aggregate responses are computed and transmitted downstream. Neuronal
cells only fire if action potentials exceed a certain threshold. In this
situation, a signal is transmitted downstream through its axons. The
neuron remains silent, if the summed signal is below the critical
threshold.
Timing of events is important in biological networks. In the computational perceptron model, a first order approximation may ignore the timing of neuronal firing (spike events) and only focus on the frequency of the firing. The firing rate of a neuron with an activation function \(f\) represents the frequency of the spikes along the axon. We saw some examples of activation functions earlier.
The diagram below illustrates the parallels between the brain network-synaptic organization and an artificial synthetic neural network.
4 Simple Neural Net Examples
Before we look at examples of deep learning algorithms applied to model observed natural phenomena, we will develop a couple of simple networks for computing fundamental Boolean operations.
4.1 Exclusive OR (XOR) Operator
The exclusive OR (XOR) operator works as a bivariate binary-outcome function, mapping pairs of false (0) and true (1) values to dichotomous false (0) and true (1) outcomes.
We can design a simple two-layer neural network that calculates
XOR. The values within each neuron represent its
explicit threshold, which can be normalized so that all neurons
utilize the same threshold, typically \(1\). The value labels associated
with network connections (edges) represent the weights of the
inputs. When the threshold is not reached, output is \(0\), and when the threshold is reached, the
output is \(1\).

Let’s work out manually the 4 possibilities:
| InputX | InputY | XOR Output(Z) |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
We can validate that this network indeed represents an XOR operator by plugging in all four possible input combinations and confirming the expected results at the end.

4.2 NAND Operator
Another binary operator is NAND (negative AND, Sheffer
stroke) that produces a false (0) output if and only if both of its
operands are true (1), and generates true (1), otherwise. Below is the
NAND input-output table.
| InputX | InputY | NAND Output(Z) |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Similar to the XOR operator, we can also design a
one-layer neural network that calculates NAND. The
values within each neurons represent its explicit
threshold, which can be normalized so that all neurons utilize
the same threshold, typically \(1\).
The value labels associated with network connections (edges)
represent the weights of the inputs. When the threshold is not
reached, the output is trivial (\(0\))
and when the threshold is reached, the output is correspondingly \(1\). Here is a shorthand analytic
expression for the NAND calculation:
\[NAND(X,Y) = 1.3 - (1\times X + 1\times Y).\] Check that \(NAND(X,Y)=0\) if and only if \(X=1\) and \(Y=1\), otherwise it equals \(1\).

4.3 Complex networks designed using simple building blocks
Observe that stringing some of these primitive networks together,
or/and increasing the number of hidden layers, allows us to model
problems with exponentially increasing complexity. For instance,
constructing a 4-input NAND function would simply require
repeating several of our 2-input NAND operators. This will
increase the space of possible outcomes from \(2^2\) to \(2^4\). Of course, introducing more depth in
the hidden layers further expands the complexity of the
problems that can be modeled using neural nets.
You can interactively manipulate the Google’s TensorFlow Deep Neural Network Webapp to gain additional intuition and experience with the various components of deep learning networks.
The ConvnetJS demo provides another hands-on example using 2D classification with 2-layer neural network.
5 Neural Network Modeling
using Keras
There are many different neural-net and deep-learning frameworks. The
table below summarizes some of the main deep learning R
packages.
| Package | Description |
|---|---|
| nnet | Feed-forward neural networks using 1 hidden layer |
| neuralnet | Training backpropagation neural networks |
| tensorflow | Google TensorFlow used in TensorBoard (see SOCR UKBB Demo) |
| deepnet | Deep learning toolkit |
| darch | Deep Architectures based on Restricted Boltzmann Machines |
| rnn | Recurrent Neural Networks (RRNs) |
| rcppDL | Multi-layer machine learning methods including dA (Denoising Autoencoder), SdA (Stacked Denoising Autoencoder), RBM (Restricted Boltzmann machine), and DBN (Deep Belief Nets) |
| deepr | DL training, fine-tuning and predicting processes using darch and deepnet |
| MXNetR | Flexible and efficient ML/DL tools utilizing CPU/GPU computing |
| kerasR | RStudio’s keras DL implementation wrapping C++/Python executable libraries |
| Keras | Python based neural networks API, connecting Google TensorFlow, Microsoft Cognitive Toolkit (CNTK), and Theano |
5.1 Iterations - Samples, Batches and Epochs
| Iteration | Description |
|---|---|
| Sample | A singleton from the dataset, i.e., one element such as a patient, case, image, file, etc. |
| Batch | An n-tuple, a set of \(n\) samples. All samples in a batch are typically processed independently, e.g., in parallel. AI training on a batch yields a single model (or model update). Dataset batches should accurately represent the underlying input data distribution, whereas a single sample represents one input. Larger batch sizes correspond to better model fits; however, they require significantly more computing processing power (cf. algorithmic complexity). |
| Epoch | A user-specified iterator that controls the number of passes over the entire dataset. Epochs separate training into independent model estimators and provide mechanisms for performance tracking and algorithmic evaluation. |
Most DL/ML R packages provide interfaces (APIs) to
libraries that are built using foundational languages like C/C++ and
Java. Most of the Python libraries also act as APIs to lower-level
executables compiled for specific platforms (Mac, Linux, PC).
The keras package uses the magrittr package
pipe operator (%>%) to join multiple
functions or operators, which streamlines the readability of the script
protocol. Also, the library zeallot supplies the reverse
piping function “%<-%”, used in multiple assignment operators, see
brain_dataset() function later.
The kerasR package contains functions analogous to the
ones in keras and utilizes the \(\$\) operator to create models. There are
parallels between the core Python methods and their
keras counterparts: compile() and
keras_compile(), fit() and
keras_fit(), predict() and
keras_predict().
Below we will demonstrate the utilization of the Keras
package for deep neural network analytics. This will require
installation of keras and TensorFlow via
R devtools::install_github("rstudio/keras").
For additional details, see the keras installation
reference, user guide and
FAQs.
We start by installing keras, which would install the
keras library, Tensorflow and other
dependencies. After the installation the R session will
restart. The following two blocks of code are run manually only
once, to install the necessary system libraries, mind the flag
eval=FALSE, then restart the entire RStudio session.
# Install Git on the system, outside RStudio: https://git-scm.com/download/win
# devtools::install_github("rstudio/keras")
reticulate::install_python()
library(reticulate)
install.packages("keras")
library(keras)
install_keras()The below cell will install tensorflow dataset wrapper for
R.
venv_name <- "r-tensorflow"
reticulate::use_virtualenv(virtualenv = venv_name, required = TRUE)
library(reticulate)
# install.packages("remotes")
remotes::install_github("rstudio/tfds")
tfds::install_tfds()venv_name <- "r-tensorflow"
reticulate::use_virtualenv(virtualenv = venv_name, required = TRUE)
library(reticulate)
# Install tensofrlow addons
reticulate::py_install(c('tensorflow-addons'), pip = TRUE)
devtools::install_github('henry090/tfaddons')
tfaddons::install_tfaddons()Before we start training load all the necessary libraries into the R session.
venv_name <- "r-tensorflow"
reticulate::use_virtualenv(virtualenv = venv_name, required = TRUE)
library(reticulate)
# use_condaenv(condaenv = "pytorch_env", required = TRUE)
# devtools::install_github("rstudio/keras")
library("keras")
# install_keras()
# install.packages("tensorflow")
# remotes::install_github("rstudio/tensorflow")
library(tensorflow)
# install_tensorflow()
# tfaddons::install_tfaddons()
library(tfaddons)The Keras
package includes built-in datasets with load()
functions, e.g., mnist.load_data() and
imdb.load_data().
5.2 Use-Case: Predicting Titanic Passengers Survival
Instead of using the default data provided in the keras
package, we will utilize one of the datasets on the DSPA
Case-Studies Website, which can be loaded much like we
did earlier in Chapter 2. Below, we download the Titanic
Passengers Dataset and perform some preprocessing steps.
library(reshape)
library(caret)
dat <- read.csv("https://umich.instructure.com/files/9372716/download?download_frd=1")
# Inspect for missing values (empty or NA):
dat.miss <- melt(apply(dat[, -2], 2, function(x) sum(is.na(x) | x=="")))
cbind(row.names(dat.miss)[dat.miss$value>0], dat.miss[dat.miss$value>0,])## [,1] [,2]
## [1,] "age" "263"
## [2,] "fare" "1"
## [3,] "cabin" "1014"
## [4,] "embarked" "2"# We can exclude the "Cabin" feature which includes 80% missing values.
# Impute the few missing Embarked values using the most common value (S)
table(dat$embarked)##
## C Q S
## 2 270 123 914dat$embarked[which(is.na(dat$embarked) | dat$embarked=="")] <- "S"
# Some "fare"" values may represent total cost of group purchases
# We can derive a new variable "price" representing fare per person
# Update missing fare value with 0
dat$fare[which(is.na(dat$fare))] <- 0
# calculate ticket Price (Fare per person)
ticket.count <- aggregate(dat$ticket, by=list(dat$ticket), function(x) sum( !is.na(x) ))
dat$price <- apply(dat, 1, function(x) as.numeric(x["fare"]) /
ticket.count[which(ticket.count[, 1] == x["ticket"]), 2])
# Impute missing prices (price=0) using the median price per passenger class
pclass.price<-aggregate(dat$price, by = list(dat$pclass), FUN = function(x) median(x, na.rm = T))
dat[which(dat$price==0), "price"] <-
apply(dat[which(dat$price==0), ] , 1, function(x)
pclass.price[pclass.price[, 1]==x["pclass"], 2])
# Define a new variable "ticketcount" coding the number of passengers sharing the same ticket number
dat$ticketcount <-
apply(dat, 1, function(x) ticket.count[which(ticket.count[, 1] ==
x["ticket"]), 2])
# Capture the passenger title
dat$title <-
regmatches(as.character(dat$name),
regexpr("\\,[A-z ]{1,20}\\.", as.character(dat$name)))
dat$title <-
unlist(lapply(dat$title,
FUN=function(x) substr(x, 3, nchar(x)-1)))
table(dat$title)##
## Capt Col Don Dona Dr Jonkheer
## 1 4 1 1 8 1
## Lady Major Master Miss Mlle Mme
## 1 2 61 260 2 1
## Mr Mrs Ms Rev Sir the Countess
## 757 197 2 8 1 1# Bin the 17 alternative title groups into 4 common 4 titles (factors)
dat$title[which(dat$title %in% c("Mme", "Mlle"))] <- "Miss"
dat$title[which(dat$title %in%
c("Lady", "Ms", "the Countess", "Dona"))] <- "Mrs"
dat$title[which(dat$title=="Dr" & dat$sex=="female")] <- "Mrs"
dat$title[which(dat$title=="Dr" & dat$sex=="male")] <- "Mr"
dat$title[which(dat$title %in% c("Capt", "Col", "Don",
"Jonkheer", "Major", "Rev", "Sir"))] <- "Mr"
dat$title <- as.factor(dat$title)
table(dat$title)##
## Master Miss Mr Mrs
## 61 263 782 2035.3 EDA/Visualization
We can start by some simple EDA plots, reporting some numerical summaries, examining pairwise correlations, and showing the distributions of some features in this dataset.
## pclass survived name sex
## Min. :1.000 Min. :0.000 Length:1309 Length:1309
## 1st Qu.:2.000 1st Qu.:0.000 Class :character Class :character
## Median :3.000 Median :0.000 Mode :character Mode :character
## Mean :2.295 Mean :0.382
## 3rd Qu.:3.000 3rd Qu.:1.000
## Max. :3.000 Max. :1.000
## age sibsp parch ticket
## Min. : 0.1667 Min. :0.0000 Min. :0.000 Length:1309
## 1st Qu.:22.0000 1st Qu.:0.0000 1st Qu.:0.000 Class :character
## Median :30.0000 Median :0.0000 Median :0.000 Mode :character
## Mean :29.5689 Mean :0.4989 Mean :0.385
## 3rd Qu.:36.0000 3rd Qu.:1.0000 3rd Qu.:0.000
## Max. :80.0000 Max. :8.0000 Max. :9.000
## fare cabin embarked price
## Min. : 0.000 Length:1309 Length:1309 Min. : 3.171
## 1st Qu.: 7.896 Class :character Class :character 1st Qu.: 7.729
## Median : 14.454 Mode :character Mode :character Median : 8.158
## Mean : 33.270 Mean : 14.991
## 3rd Qu.: 31.275 3rd Qu.: 15.050
## Max. :512.329 Max. :128.082
## ticketcount title
## Min. : 1.000 Master: 61
## 1st Qu.: 1.000 Miss :263
## Median : 1.000 Mr :782
## Mean : 2.102 Mrs :203
## 3rd Qu.: 3.000
## Max. :11.000# cols <- c("red","green")[unclass(dat$survived)]
#
# plot(dat$ticketcount, dat$fare, pch=21, cex=1.5,
# bg=alpha(cols, 0.4),
# xlab="Number of Tickets per Party", ylab="Passenger Fare",
# main="Titanic Passenger Data (TicketCount vs. Fare) Color Coded by Survival")
# legend("topright", inset=.02, title="Survival",
# c("0","1"), fill=c("red", "green"), horiz=F, cex=0.8)
plot_ly(dat, type="scatter", mode="markers") %>%
add_trace(x = ~ticketcount, y=~fare, mode = 'markers',
color = ~as.character(survived), colors=~survived) %>%
layout(legend = list(title=list(text='<b> Survival </b>'), orientation = 'h'),
title="Titanic Passenger Data (TicketCount vs. Fare) Color Coded by Survival")# plot_ly(dat, x = ~ticketcount, color = ~survived) %>% add_histogram()
#
# plot_ly(dat, x = ~ticketcount, y = ~fare, color = ~survived, name=~survived) %>% add_bars() %>% layout(barmode = "stack")
# ggplot(dat, aes(x=survived, y=fare, fill=sex)) +
# #geom_dotplot(binaxis='y', stackdir='center',
# # position=position_dodge(1)) +
# #scale_fill_manual(values=c("#999999", "#E69F00")) +
# geom_violin(trim=FALSE) +
# theme(legend.position="top")
fig <- dat %>% plot_ly(type = 'violin')
fig <- fig %>% add_trace(x = ~survived[dat$survived == '1'], y = ~fare[dat$survived == '1'],
legendgroup = 'survived', scalegroup = 'survived', name = 'survived',
box = list(visible = T), meanline = list(visible = T ), color = I("green"))
fig <- fig %>% add_trace(x = ~survived[dat$survived == '0'], y = ~fare[dat$survived == '0'],
legendgroup = 'died', scalegroup = 'died', name = 'died',
box = list(visible = T), meanline = list(visible = T ), color = I("red"))
fig <- fig %>% layout( xaxis = list(title="Survival"), yaxis = list(title="Fare"),
title='<b> Titanic Passenger Survival vs. Fare </b>', orientation = 'h')
fig# library(GGally)
# ggpairs(dat[ , c("pclass", "age", "sibsp", "parch",
# "fare", "price", "ticketcount", "survived")],
# aes(colour = as.factor(survived), alpha = 0.4))
dims <- dplyr::select_if(dat, is.numeric)
dims <- purrr::map2(dims, names(dims), ~list(values=.x, label=.y))
plot_ly(type = "splom", dimensions = setNames(dims, NULL), showupperhalf = FALSE,
diagonal = list(visible = FALSE) ) %>%
layout( title='<b> Titanic Passengers Pairs-Plots </b>')5.4 Data Preprocessing
Before we go into modeling the data, we need to preprocess it, e.g., normalize the numerical values and split it into training and testing sets.
dat1 <- dat[ , c("pclass", "age", "sibsp", "parch", "fare",
"price", "ticketcount", "survived")]
dat1$pclass <- as.factor(dat1$pclass)
dat1$age <- as.numeric(dat1$age)
dat1$sibsp <- as.factor(dat1$sibsp)
dat1$parch <- as.factor(dat1$parch)
dat1$fare <- as.numeric(dat1$fare)
dat1$price <- as.numeric(dat1$price)
dat1$ticketcount <- as.numeric(dat1$ticketcount)
dat1$survived <- as.factor(dat1$survived)
# Set the `dimnames` to `NULL`
# dimnames(dat1) <- NULL
dim(dat1)## [1] 1309 8Use keras::normalize() to normalize the numerical data.
See the
details about installing keras, TensorFlow,
and their dependencies in R/Python/Posit/RStudio environment.
### library(tensorflow)
# tensorflow::install_tensorflow()
# reticulate::py_module_available("tensorflow")
# reticulate::conda_list()
library(tensorflow)
# use_virtualenv("r-tensorflow")
# devtools::install_github("rstudio/keras")
# First install Anaconda/Python: https://www.anaconda.com/download/#windows
# install_keras()
# reticulate::py_config()
# library("keras")
# use_python("C:/Users/Dinov/AppData/Local/Programs/Python/Python37/python.exe")
# install_keras()
# install_keras(method = "conda")
# install_tensorflow()
# reticulate::virtualenv_starter(all = TRUE)
library("keras")
# Check Conda/Python Environments on the system
# conda_list()
# For local PC testing use conda...
# Create a new "pytorch_env" environment first
# https://rstudio.github.io/reticulate/articles/python_packages.html
# library(reticulate)
# conda_create(name = "pytorch_env",
# packages = c("python=3.8", "torch", "pillow", "numpy", "pybase64", "uuid"))
# in terminal
# %> conda create --name pytorch_env python=3.8
# %> conda activate pytorch_env
# %> pip install torch pillow numpy pybase64 uuid tensorflow typing-extensions tensorflow-addons
#
# use_condaenv(condaenv = "pytorch_env", required = TRUE)
# py_path = "C:/Users/IvoD/Anaconda3/" # manual
# py_path = "C:/Users/IvoD/Documents/.virtualenvs/r-tensorflow/Scripts/python.exe"
# py_path = Sys.which("python3") # automated
# use_python(py_path, required = T)
# Sys.setenv(RETICULATE_PYTHON = "C:/Users/IvoD/Anaconda3/")
# library("tensorflow")
# Normalize the data
summary(dat1[ , c(2,5,6,7)])## age fare price ticketcount
## Min. : 0.1667 Min. : 0.000 Min. : 3.171 Min. : 1.000
## 1st Qu.:22.0000 1st Qu.: 7.896 1st Qu.: 7.729 1st Qu.: 1.000
## Median :30.0000 Median : 14.454 Median : 8.158 Median : 1.000
## Mean :29.5689 Mean : 33.270 Mean : 14.991 Mean : 2.102
## 3rd Qu.:36.0000 3rd Qu.: 31.275 3rd Qu.: 15.050 3rd Qu.: 3.000
## Max. :80.0000 Max. :512.329 Max. :128.082 Max. :11.000dat2 <- dat1[ , c(2,5,6,7)]
dat2 <- as.matrix(dat2)
dimnames(dat2) <- NULL
# May be best to avoid normalizing the ordinal variable "ticketcount"
dat2.norm <- normalize(dat2, axis=2)
# report the summary`
summary(dat2.norm)## V1 V2 V3 V4
## Min. :0.005962 Min. :0.0000 Min. :0.0797 Min. :0.007529
## 1st Qu.:0.529205 1st Qu.:0.2891 1st Qu.:0.2265 1st Qu.:0.026743
## Median :0.823905 Median :0.4298 Median :0.2845 Median :0.034269
## Mean :0.700518 Mean :0.5105 Mean :0.2961 Mean :0.049940
## 3rd Qu.:0.913000 3rd Qu.:0.7543 3rd Qu.:0.3640 3rd Qu.:0.050859
## Max. :0.991762 Max. :0.9884 Max. :0.7033 Max. :0.246830Next, we’ll partition the raw data into training (80%) and testing (20%) sets that will be utilized to build the forecasting model (to predict Titanic passenger survival) and assess the model performance, respectively.
train_set_ind <- sample(nrow(dat2.norm), floor(nrow(dat2.norm)*0.8)) # 80:20 plot training:testing
train_dat2.X <- dat2.norm[train_set_ind, ]
train_dat2.Y <- dat1[train_set_ind , 8] # Outcome "survived" column:8
test_dat2.X <- dat2.norm[-train_set_ind, ]
test_dat2.Y <- dat1[-train_set_ind , 8] # Outcome "survived" column:8
# double check the size/dimensions of the training and testing data (predictors and responses)
dim(train_dat2.X); length(train_dat2.Y); dim(test_dat2.X); length(test_dat2.Y)## [1] 1047 4## [1] 1047## [1] 262 4## [1] 2625.5 Keras Modeling
For multi-class classification problems via NN modeling, the
keras::to_categorical() function allows us to transform the
outcome attribute from a vector of class labels to a matrix of Boolean
features, one for each class label. In this case, we have a bivariate
(binary classification), passenger survival indicator.
Keras modeling starts with first initializing a sequential model
using the keras::keras_model_sequential() function.
We will try to predict the passenger survival using a fully-connected
multi-layer perceptron NN. We will need to choose an activation
function, e.g., relu, sigmoid. A rectifier
activation function (relu) may be used in a hidden layer and a
softmax activation function may be used in the final output
layer so that the outputs represent (posterior) probabilities between 0
and 1, corresponding to the odds of survival. In the first layer, we can
specify 8 hidden nodes (units), an input_shape
of 4, to reflect the 4 features in the training data age,
fare, price, ticketcount, and the output
layer with 2 output values, one for each of the survival categories. We
can also inspect the structure of the NN model using:
summary(): print a summary representation of your model,get_config(): return a list that contains the configuration of the model,get_layer(): return the layer configuration,$layers: NN model attribute retrieves a flattened list of the model’s layers,$inputs: NN model attribute listing the input tensors,$outputs: NN model attribute retrieves the output tensors.
model.1 <- keras_model_sequential()
# library(keras3)
# Add layers to the model
model.1 %>%
layer_dense(units = 8, activation = 'relu', input_shape = c(4)) %>%
layer_dense(units = 2, activation = 'softmax')
# NN model summary
summary(model.1)## Model: "sequential"
## ________________________________________________________________________________
## Layer (type) Output Shape Param #
## ================================================================================
## dense_1 (Dense) (None, 8) 40
## dense (Dense) (None, 2) 18
## ================================================================================
## Total params: 58 (232.00 Byte)
## Trainable params: 58 (232.00 Byte)
## Non-trainable params: 0 (0.00 Byte)
## ________________________________________________________________________________## {'name': 'sequential', 'layers': [{'module': 'keras.layers', 'class_name': 'InputLayer', 'config': {'batch_input_shape': (None, 4), 'dtype': 'float32', 'sparse': False, 'ragged': False, 'name': 'dense_1_input'}, 'registered_name': None}, {'module': 'keras.layers', 'class_name': 'Dense', 'config': {'name': 'dense_1', 'trainable': True, 'dtype': 'float32', 'batch_input_shape': (None, 4), 'units': 8, 'activation': 'relu', 'use_bias': True, 'kernel_initializer': {'module': 'keras.initializers', 'class_name': 'GlorotUniform', 'config': {'seed': None}, 'registered_name': None}, 'bias_initializer': {'module': 'keras.initializers', 'class_name': 'Zeros', 'config': {}, 'registered_name': None}, 'kernel_regularizer': None, 'bias_regularizer': None, 'activity_regularizer': None, 'kernel_constraint': None, 'bias_constraint': None}, 'registered_name': None, 'build_config': {'input_shape': (None, 4)}}, {'module': 'keras.layers', 'class_name': 'Dense', 'config': {'name': 'dense', 'trainable': True, 'dtype': 'float32', 'units': 2, 'activation': 'softmax', 'use_bias': True, 'kernel_initializer': {'module': 'keras.initializers', 'class_name': 'GlorotUniform', 'config': {'seed': None}, 'registered_name': None}, 'bias_initializer': {'module': 'keras.initializers', 'class_name': 'Zeros', 'config': {}, 'registered_name': None}, 'kernel_regularizer': None, 'bias_regularizer': None, 'activity_regularizer': None, 'kernel_constraint': None, 'bias_constraint': None}, 'registered_name': None, 'build_config': {'input_shape': (None, 8)}}]}## <keras.src.layers.core.dense.Dense object at 0x0000024B2C1377F0>
## signature: (*args, **kwargs)## [[1]]
## <keras.src.layers.core.dense.Dense object at 0x0000024B2C1377F0>
## signature: (*args, **kwargs)
##
## [[2]]
## <keras.src.layers.core.dense.Dense object at 0x0000024B2C136F80>
## signature: (*args, **kwargs)## [[1]]
## KerasTensor(type_spec=TensorSpec(shape=(None, 4), dtype=tf.float32, name='dense_1_input'), name='dense_1_input', description="created by layer 'dense_1_input'")## [[1]]
## KerasTensor(type_spec=TensorSpec(shape=(None, 2), dtype=tf.float32, name=None), name='dense/Softmax:0', description="created by layer 'dense'")Once the model architecture is specified, we need to estimate (fit)
the NN model using the training data. The adaptive momentum
(ADAM) optimizer along with
categorical_crossentropy objective function may be used to
compile the NN model. Specifying accuracy
as a metrics argument allows us to inspect the quality of the NN model
fit during the training phase (training data validation). The
optimizer and the objective (loss) functions are the
pair of required arguments for model compilation.
In addition to ADAM, alternative optimization algorithms include Stochastic Gradient Descent (SGD) and Root Mean Square proportion (RMSprop). ADAM is essentially RMSprop with momentum whereas NADAM is ADAM RMSprop with Nesterov momentum. Following the selection of the optimization algorithm, we need to tune the model parameters, e.g., learning rate or momentum. Choosing an appropriate objective function depends on the classification or regression forecasting task, e.g., regression prediction (continuous outcomes) usually utilizes Mean Squared Error (MSE), whereas multi-class classification problems use categorical_crossentropy loss function and binary classification problems commonly use binary_crossentropy loss function.
5.6 NN Model Fitting
The next step fits the NN model (model.1) to the
training data using 200 epochs, or iterations over all the samples in
train_dat2.X (predictors) and train_dat2.Y
(outcomes), in batches of 10 samples. This process trains the model on a
specified number of epochs (iterations or exposures) on the training
data. One epoch is a single pass through the whole training set followed
by comparing the model prediction results against the verification
labels. The batch size defines the number of samples being propagated
through the network at once (as a batch).
# convert the labels to categorical values
train_dat2.Y <- to_categorical(train_dat2.Y)
test_dat2.Y <- to_categorical(test_dat2.Y)
# library(keras3)
# Fit the model & Store the fitting history
track.model.1 <- model.1 %>% fit(
train_dat2.X,
train_dat2.Y,
epochs = 200,
batch_size = 10,
validation_split = 0.2
)## Epoch 1/200
## 84/84 - 1s - loss: 0.7144 - accuracy: 0.3740 - val_loss: 0.7002 - val_accuracy: 0.5667 - 787ms/epoch - 9ms/step
## Epoch 2/200
## 84/84 - 0s - loss: 0.6813 - accuracy: 0.6201 - val_loss: 0.6818 - val_accuracy: 0.5667 - 118ms/epoch - 1ms/step
## Epoch 3/200
## 84/84 - 0s - loss: 0.6617 - accuracy: 0.6201 - val_loss: 0.6732 - val_accuracy: 0.5667 - 109ms/epoch - 1ms/step
## Epoch 4/200
## 84/84 - 0s - loss: 0.6488 - accuracy: 0.6201 - val_loss: 0.6687 - val_accuracy: 0.5667 - 117ms/epoch - 1ms/step
## Epoch 5/200
## 84/84 - 0s - loss: 0.6404 - accuracy: 0.6201 - val_loss: 0.6651 - val_accuracy: 0.5667 - 104ms/epoch - 1ms/step
## Epoch 6/200
## 84/84 - 0s - loss: 0.6346 - accuracy: 0.6201 - val_loss: 0.6612 - val_accuracy: 0.5667 - 107ms/epoch - 1ms/step
## Epoch 7/200
## 84/84 - 0s - loss: 0.6301 - accuracy: 0.6201 - val_loss: 0.6589 - val_accuracy: 0.5667 - 102ms/epoch - 1ms/step
## Epoch 8/200
## 84/84 - 0s - loss: 0.6262 - accuracy: 0.6201 - val_loss: 0.6566 - val_accuracy: 0.5667 - 102ms/epoch - 1ms/step
## Epoch 9/200
## 84/84 - 0s - loss: 0.6233 - accuracy: 0.6201 - val_loss: 0.6546 - val_accuracy: 0.5667 - 103ms/epoch - 1ms/step
## Epoch 10/200
## 84/84 - 0s - loss: 0.6204 - accuracy: 0.6201 - val_loss: 0.6532 - val_accuracy: 0.5667 - 103ms/epoch - 1ms/step
## Epoch 11/200
## 84/84 - 0s - loss: 0.6180 - accuracy: 0.6201 - val_loss: 0.6509 - val_accuracy: 0.5667 - 100ms/epoch - 1ms/step
## Epoch 12/200
## 84/84 - 0s - loss: 0.6156 - accuracy: 0.6201 - val_loss: 0.6492 - val_accuracy: 0.5667 - 103ms/epoch - 1ms/step
## Epoch 13/200
## 84/84 - 0s - loss: 0.6141 - accuracy: 0.6201 - val_loss: 0.6476 - val_accuracy: 0.5667 - 103ms/epoch - 1ms/step
## Epoch 14/200
## 84/84 - 0s - loss: 0.6121 - accuracy: 0.6225 - val_loss: 0.6458 - val_accuracy: 0.6095 - 102ms/epoch - 1ms/step
## Epoch 15/200
## 84/84 - 0s - loss: 0.6106 - accuracy: 0.6476 - val_loss: 0.6442 - val_accuracy: 0.6762 - 103ms/epoch - 1ms/step
## Epoch 16/200
## 84/84 - 0s - loss: 0.6089 - accuracy: 0.6906 - val_loss: 0.6439 - val_accuracy: 0.6857 - 102ms/epoch - 1ms/step
## Epoch 17/200
## 84/84 - 0s - loss: 0.6075 - accuracy: 0.6906 - val_loss: 0.6440 - val_accuracy: 0.6905 - 104ms/epoch - 1ms/step
## Epoch 18/200
## 84/84 - 0s - loss: 0.6064 - accuracy: 0.6870 - val_loss: 0.6439 - val_accuracy: 0.6810 - 103ms/epoch - 1ms/step
## Epoch 19/200
## 84/84 - 0s - loss: 0.6055 - accuracy: 0.6918 - val_loss: 0.6426 - val_accuracy: 0.6762 - 100ms/epoch - 1ms/step
## Epoch 20/200
## 84/84 - 0s - loss: 0.6047 - accuracy: 0.6953 - val_loss: 0.6427 - val_accuracy: 0.6762 - 102ms/epoch - 1ms/step
## Epoch 21/200
## 84/84 - 0s - loss: 0.6036 - accuracy: 0.6918 - val_loss: 0.6413 - val_accuracy: 0.6810 - 103ms/epoch - 1ms/step
## Epoch 22/200
## 84/84 - 0s - loss: 0.6031 - accuracy: 0.6977 - val_loss: 0.6415 - val_accuracy: 0.6810 - 100ms/epoch - 1ms/step
## Epoch 23/200
## 84/84 - 0s - loss: 0.6026 - accuracy: 0.6953 - val_loss: 0.6401 - val_accuracy: 0.6810 - 106ms/epoch - 1ms/step
## Epoch 24/200
## 84/84 - 0s - loss: 0.6018 - accuracy: 0.7001 - val_loss: 0.6385 - val_accuracy: 0.6857 - 102ms/epoch - 1ms/step
## Epoch 25/200
## 84/84 - 0s - loss: 0.6013 - accuracy: 0.7001 - val_loss: 0.6384 - val_accuracy: 0.6762 - 101ms/epoch - 1ms/step
## Epoch 26/200
## 84/84 - 0s - loss: 0.6006 - accuracy: 0.6930 - val_loss: 0.6385 - val_accuracy: 0.6762 - 109ms/epoch - 1ms/step
## Epoch 27/200
## 84/84 - 0s - loss: 0.5999 - accuracy: 0.6882 - val_loss: 0.6381 - val_accuracy: 0.6762 - 102ms/epoch - 1ms/step
## Epoch 28/200
## 84/84 - 0s - loss: 0.5993 - accuracy: 0.6941 - val_loss: 0.6377 - val_accuracy: 0.6762 - 102ms/epoch - 1ms/step
## Epoch 29/200
## 84/84 - 0s - loss: 0.5990 - accuracy: 0.6941 - val_loss: 0.6379 - val_accuracy: 0.6762 - 104ms/epoch - 1ms/step
## Epoch 30/200
## 84/84 - 0s - loss: 0.5987 - accuracy: 0.6894 - val_loss: 0.6364 - val_accuracy: 0.6714 - 102ms/epoch - 1ms/step
## Epoch 31/200
## 84/84 - 0s - loss: 0.5980 - accuracy: 0.6918 - val_loss: 0.6359 - val_accuracy: 0.6714 - 101ms/epoch - 1ms/step
## Epoch 32/200
## 84/84 - 0s - loss: 0.5976 - accuracy: 0.6953 - val_loss: 0.6353 - val_accuracy: 0.6762 - 102ms/epoch - 1ms/step
## Epoch 33/200
## 84/84 - 0s - loss: 0.5972 - accuracy: 0.6906 - val_loss: 0.6349 - val_accuracy: 0.6762 - 106ms/epoch - 1ms/step
## Epoch 34/200
## 84/84 - 0s - loss: 0.5968 - accuracy: 0.6941 - val_loss: 0.6348 - val_accuracy: 0.6810 - 103ms/epoch - 1ms/step
## Epoch 35/200
## 84/84 - 0s - loss: 0.5964 - accuracy: 0.6918 - val_loss: 0.6348 - val_accuracy: 0.6810 - 103ms/epoch - 1ms/step
## Epoch 36/200
## 84/84 - 0s - loss: 0.5959 - accuracy: 0.6858 - val_loss: 0.6339 - val_accuracy: 0.6857 - 104ms/epoch - 1ms/step
## Epoch 37/200
## 84/84 - 0s - loss: 0.5954 - accuracy: 0.6894 - val_loss: 0.6347 - val_accuracy: 0.6810 - 101ms/epoch - 1ms/step
## Epoch 38/200
## 84/84 - 0s - loss: 0.5953 - accuracy: 0.6906 - val_loss: 0.6329 - val_accuracy: 0.6905 - 102ms/epoch - 1ms/step
## Epoch 39/200
## 84/84 - 0s - loss: 0.5950 - accuracy: 0.6858 - val_loss: 0.6351 - val_accuracy: 0.6810 - 99ms/epoch - 1ms/step
## Epoch 40/200
## 84/84 - 0s - loss: 0.5946 - accuracy: 0.6834 - val_loss: 0.6335 - val_accuracy: 0.6952 - 103ms/epoch - 1ms/step
## Epoch 41/200
## 84/84 - 0s - loss: 0.5944 - accuracy: 0.6858 - val_loss: 0.6327 - val_accuracy: 0.6905 - 104ms/epoch - 1ms/step
## Epoch 42/200
## 84/84 - 0s - loss: 0.5939 - accuracy: 0.6894 - val_loss: 0.6322 - val_accuracy: 0.6952 - 105ms/epoch - 1ms/step
## Epoch 43/200
## 84/84 - 0s - loss: 0.5937 - accuracy: 0.6858 - val_loss: 0.6336 - val_accuracy: 0.6952 - 106ms/epoch - 1ms/step
## Epoch 44/200
## 84/84 - 0s - loss: 0.5930 - accuracy: 0.6858 - val_loss: 0.6322 - val_accuracy: 0.6952 - 102ms/epoch - 1ms/step
## Epoch 45/200
## 84/84 - 0s - loss: 0.5930 - accuracy: 0.6858 - val_loss: 0.6321 - val_accuracy: 0.6905 - 107ms/epoch - 1ms/step
## Epoch 46/200
## 84/84 - 0s - loss: 0.5926 - accuracy: 0.6882 - val_loss: 0.6322 - val_accuracy: 0.6952 - 101ms/epoch - 1ms/step
## Epoch 47/200
## 84/84 - 0s - loss: 0.5923 - accuracy: 0.6894 - val_loss: 0.6316 - val_accuracy: 0.6905 - 100ms/epoch - 1ms/step
## Epoch 48/200
## 84/84 - 0s - loss: 0.5923 - accuracy: 0.6906 - val_loss: 0.6327 - val_accuracy: 0.6905 - 108ms/epoch - 1ms/step
## Epoch 49/200
## 84/84 - 0s - loss: 0.5919 - accuracy: 0.6882 - val_loss: 0.6313 - val_accuracy: 0.6905 - 104ms/epoch - 1ms/step
## Epoch 50/200
## 84/84 - 0s - loss: 0.5918 - accuracy: 0.6906 - val_loss: 0.6324 - val_accuracy: 0.6905 - 102ms/epoch - 1ms/step
## Epoch 51/200
## 84/84 - 0s - loss: 0.5917 - accuracy: 0.6906 - val_loss: 0.6331 - val_accuracy: 0.6952 - 102ms/epoch - 1ms/step
## Epoch 52/200
## 84/84 - 0s - loss: 0.5914 - accuracy: 0.6906 - val_loss: 0.6303 - val_accuracy: 0.6810 - 101ms/epoch - 1ms/step
## Epoch 53/200
## 84/84 - 0s - loss: 0.5909 - accuracy: 0.6941 - val_loss: 0.6316 - val_accuracy: 0.6952 - 103ms/epoch - 1ms/step
## Epoch 54/200
## 84/84 - 0s - loss: 0.5907 - accuracy: 0.6953 - val_loss: 0.6304 - val_accuracy: 0.6810 - 102ms/epoch - 1ms/step
## Epoch 55/200
## 84/84 - 0s - loss: 0.5909 - accuracy: 0.6941 - val_loss: 0.6307 - val_accuracy: 0.6905 - 102ms/epoch - 1ms/step
## Epoch 56/200
## 84/84 - 0s - loss: 0.5902 - accuracy: 0.6989 - val_loss: 0.6297 - val_accuracy: 0.6857 - 104ms/epoch - 1ms/step
## Epoch 57/200
## 84/84 - 0s - loss: 0.5899 - accuracy: 0.6989 - val_loss: 0.6308 - val_accuracy: 0.6905 - 102ms/epoch - 1ms/step
## Epoch 58/200
## 84/84 - 0s - loss: 0.5901 - accuracy: 0.6953 - val_loss: 0.6300 - val_accuracy: 0.6857 - 103ms/epoch - 1ms/step
## Epoch 59/200
## 84/84 - 0s - loss: 0.5896 - accuracy: 0.6977 - val_loss: 0.6313 - val_accuracy: 0.6857 - 101ms/epoch - 1ms/step
## Epoch 60/200
## 84/84 - 0s - loss: 0.5892 - accuracy: 0.6953 - val_loss: 0.6300 - val_accuracy: 0.6810 - 101ms/epoch - 1ms/step
## Epoch 61/200
## 84/84 - 0s - loss: 0.5892 - accuracy: 0.7013 - val_loss: 0.6320 - val_accuracy: 0.6905 - 101ms/epoch - 1ms/step
## Epoch 62/200
## 84/84 - 0s - loss: 0.5892 - accuracy: 0.7049 - val_loss: 0.6317 - val_accuracy: 0.6857 - 103ms/epoch - 1ms/step
## Epoch 63/200
## 84/84 - 0s - loss: 0.5886 - accuracy: 0.7061 - val_loss: 0.6301 - val_accuracy: 0.6857 - 106ms/epoch - 1ms/step
## Epoch 64/200
## 84/84 - 0s - loss: 0.5881 - accuracy: 0.7025 - val_loss: 0.6296 - val_accuracy: 0.6810 - 102ms/epoch - 1ms/step
## Epoch 65/200
## 84/84 - 0s - loss: 0.5879 - accuracy: 0.7025 - val_loss: 0.6300 - val_accuracy: 0.6810 - 104ms/epoch - 1ms/step
## Epoch 66/200
## 84/84 - 0s - loss: 0.5881 - accuracy: 0.7013 - val_loss: 0.6294 - val_accuracy: 0.6762 - 103ms/epoch - 1ms/step
## Epoch 67/200
## 84/84 - 0s - loss: 0.5878 - accuracy: 0.7061 - val_loss: 0.6307 - val_accuracy: 0.6857 - 102ms/epoch - 1ms/step
## Epoch 68/200
## 84/84 - 0s - loss: 0.5875 - accuracy: 0.7085 - val_loss: 0.6303 - val_accuracy: 0.6810 - 101ms/epoch - 1ms/step
## Epoch 69/200
## 84/84 - 0s - loss: 0.5870 - accuracy: 0.7097 - val_loss: 0.6286 - val_accuracy: 0.6762 - 98ms/epoch - 1ms/step
## Epoch 70/200
## 84/84 - 0s - loss: 0.5873 - accuracy: 0.7073 - val_loss: 0.6289 - val_accuracy: 0.6762 - 102ms/epoch - 1ms/step
## Epoch 71/200
## 84/84 - 0s - loss: 0.5865 - accuracy: 0.7085 - val_loss: 0.6287 - val_accuracy: 0.6762 - 104ms/epoch - 1ms/step
## Epoch 72/200
## 84/84 - 0s - loss: 0.5864 - accuracy: 0.7109 - val_loss: 0.6291 - val_accuracy: 0.6714 - 101ms/epoch - 1ms/step
## Epoch 73/200
## 84/84 - 0s - loss: 0.5860 - accuracy: 0.7109 - val_loss: 0.6290 - val_accuracy: 0.6762 - 109ms/epoch - 1ms/step
## Epoch 74/200
## 84/84 - 0s - loss: 0.5859 - accuracy: 0.7168 - val_loss: 0.6288 - val_accuracy: 0.6762 - 101ms/epoch - 1ms/step
## Epoch 75/200
## 84/84 - 0s - loss: 0.5860 - accuracy: 0.7073 - val_loss: 0.6290 - val_accuracy: 0.6762 - 104ms/epoch - 1ms/step
## Epoch 76/200
## 84/84 - 0s - loss: 0.5852 - accuracy: 0.7109 - val_loss: 0.6288 - val_accuracy: 0.6762 - 100ms/epoch - 1ms/step
## Epoch 77/200
## 84/84 - 0s - loss: 0.5858 - accuracy: 0.7097 - val_loss: 0.6298 - val_accuracy: 0.6714 - 103ms/epoch - 1ms/step
## Epoch 78/200
## 84/84 - 0s - loss: 0.5845 - accuracy: 0.7085 - val_loss: 0.6279 - val_accuracy: 0.6762 - 100ms/epoch - 1ms/step
## Epoch 79/200
## 84/84 - 0s - loss: 0.5845 - accuracy: 0.7097 - val_loss: 0.6277 - val_accuracy: 0.6762 - 102ms/epoch - 1ms/step
## Epoch 80/200
## 84/84 - 0s - loss: 0.5850 - accuracy: 0.7073 - val_loss: 0.6283 - val_accuracy: 0.6714 - 102ms/epoch - 1ms/step
## Epoch 81/200
## 84/84 - 0s - loss: 0.5842 - accuracy: 0.7145 - val_loss: 0.6294 - val_accuracy: 0.6714 - 102ms/epoch - 1ms/step
## Epoch 82/200
## 84/84 - 0s - loss: 0.5836 - accuracy: 0.7133 - val_loss: 0.6292 - val_accuracy: 0.6762 - 100ms/epoch - 1ms/step
## Epoch 83/200
## 84/84 - 0s - loss: 0.5836 - accuracy: 0.7097 - val_loss: 0.6283 - val_accuracy: 0.6762 - 104ms/epoch - 1ms/step
## Epoch 84/200
## 84/84 - 0s - loss: 0.5830 - accuracy: 0.7073 - val_loss: 0.6287 - val_accuracy: 0.6714 - 101ms/epoch - 1ms/step
## Epoch 85/200
## 84/84 - 0s - loss: 0.5834 - accuracy: 0.7145 - val_loss: 0.6289 - val_accuracy: 0.6714 - 101ms/epoch - 1ms/step
## Epoch 86/200
## 84/84 - 0s - loss: 0.5829 - accuracy: 0.7145 - val_loss: 0.6289 - val_accuracy: 0.6714 - 104ms/epoch - 1ms/step
## Epoch 87/200
## 84/84 - 0s - loss: 0.5828 - accuracy: 0.7145 - val_loss: 0.6281 - val_accuracy: 0.6762 - 100ms/epoch - 1ms/step
## Epoch 88/200
## 84/84 - 0s - loss: 0.5826 - accuracy: 0.7168 - val_loss: 0.6298 - val_accuracy: 0.6714 - 100ms/epoch - 1ms/step
## Epoch 89/200
## 84/84 - 0s - loss: 0.5820 - accuracy: 0.7145 - val_loss: 0.6289 - val_accuracy: 0.6714 - 100ms/epoch - 1ms/step
## Epoch 90/200
## 84/84 - 0s - loss: 0.5821 - accuracy: 0.7121 - val_loss: 0.6281 - val_accuracy: 0.6762 - 103ms/epoch - 1ms/step
## Epoch 91/200
## 84/84 - 0s - loss: 0.5815 - accuracy: 0.7168 - val_loss: 0.6276 - val_accuracy: 0.6762 - 104ms/epoch - 1ms/step
## Epoch 92/200
## 84/84 - 0s - loss: 0.5813 - accuracy: 0.7145 - val_loss: 0.6281 - val_accuracy: 0.6762 - 101ms/epoch - 1ms/step
## Epoch 93/200
## 84/84 - 0s - loss: 0.5808 - accuracy: 0.7145 - val_loss: 0.6284 - val_accuracy: 0.6762 - 109ms/epoch - 1ms/step
## Epoch 94/200
## 84/84 - 0s - loss: 0.5806 - accuracy: 0.7157 - val_loss: 0.6278 - val_accuracy: 0.6762 - 104ms/epoch - 1ms/step
## Epoch 95/200
## 84/84 - 0s - loss: 0.5809 - accuracy: 0.7145 - val_loss: 0.6274 - val_accuracy: 0.6762 - 101ms/epoch - 1ms/step
## Epoch 96/200
## 84/84 - 0s - loss: 0.5808 - accuracy: 0.7133 - val_loss: 0.6271 - val_accuracy: 0.6762 - 102ms/epoch - 1ms/step
## Epoch 97/200
## 84/84 - 0s - loss: 0.5803 - accuracy: 0.7180 - val_loss: 0.6264 - val_accuracy: 0.6762 - 101ms/epoch - 1ms/step
## Epoch 98/200
## 84/84 - 0s - loss: 0.5798 - accuracy: 0.7168 - val_loss: 0.6285 - val_accuracy: 0.6762 - 99ms/epoch - 1ms/step
## Epoch 99/200
## 84/84 - 0s - loss: 0.5797 - accuracy: 0.7145 - val_loss: 0.6278 - val_accuracy: 0.6714 - 103ms/epoch - 1ms/step
## Epoch 100/200
## 84/84 - 0s - loss: 0.5802 - accuracy: 0.7180 - val_loss: 0.6258 - val_accuracy: 0.6762 - 103ms/epoch - 1ms/step
## Epoch 101/200
## 84/84 - 0s - loss: 0.5794 - accuracy: 0.7168 - val_loss: 0.6267 - val_accuracy: 0.6714 - 104ms/epoch - 1ms/step
## Epoch 102/200
## 84/84 - 0s - loss: 0.5799 - accuracy: 0.7097 - val_loss: 0.6288 - val_accuracy: 0.6762 - 101ms/epoch - 1ms/step
## Epoch 103/200
## 84/84 - 0s - loss: 0.5788 - accuracy: 0.7157 - val_loss: 0.6288 - val_accuracy: 0.6762 - 104ms/epoch - 1ms/step
## Epoch 104/200
## 84/84 - 0s - loss: 0.5783 - accuracy: 0.7157 - val_loss: 0.6271 - val_accuracy: 0.6714 - 103ms/epoch - 1ms/step
## Epoch 105/200
## 84/84 - 0s - loss: 0.5785 - accuracy: 0.7145 - val_loss: 0.6274 - val_accuracy: 0.6762 - 100ms/epoch - 1ms/step
## Epoch 106/200
## 84/84 - 0s - loss: 0.5782 - accuracy: 0.7157 - val_loss: 0.6273 - val_accuracy: 0.6714 - 100ms/epoch - 1ms/step
## Epoch 107/200
## 84/84 - 0s - loss: 0.5778 - accuracy: 0.7157 - val_loss: 0.6272 - val_accuracy: 0.6714 - 101ms/epoch - 1ms/step
## Epoch 108/200
## 84/84 - 0s - loss: 0.5776 - accuracy: 0.7157 - val_loss: 0.6279 - val_accuracy: 0.6762 - 101ms/epoch - 1ms/step
## Epoch 109/200
## 84/84 - 0s - loss: 0.5773 - accuracy: 0.7133 - val_loss: 0.6293 - val_accuracy: 0.6762 - 101ms/epoch - 1ms/step
## Epoch 110/200
## 84/84 - 0s - loss: 0.5777 - accuracy: 0.7180 - val_loss: 0.6285 - val_accuracy: 0.6762 - 104ms/epoch - 1ms/step
## Epoch 111/200
## 84/84 - 0s - loss: 0.5770 - accuracy: 0.7145 - val_loss: 0.6288 - val_accuracy: 0.6762 - 106ms/epoch - 1ms/step
## Epoch 112/200
## 84/84 - 0s - loss: 0.5771 - accuracy: 0.7121 - val_loss: 0.6274 - val_accuracy: 0.6762 - 103ms/epoch - 1ms/step
## Epoch 113/200
## 84/84 - 0s - loss: 0.5767 - accuracy: 0.7168 - val_loss: 0.6285 - val_accuracy: 0.6762 - 106ms/epoch - 1ms/step
## Epoch 114/200
## 84/84 - 0s - loss: 0.5762 - accuracy: 0.7157 - val_loss: 0.6290 - val_accuracy: 0.6762 - 101ms/epoch - 1ms/step
## Epoch 115/200
## 84/84 - 0s - loss: 0.5763 - accuracy: 0.7168 - val_loss: 0.6279 - val_accuracy: 0.6762 - 105ms/epoch - 1ms/step
## Epoch 116/200
## 84/84 - 0s - loss: 0.5758 - accuracy: 0.7145 - val_loss: 0.6283 - val_accuracy: 0.6762 - 103ms/epoch - 1ms/step
## Epoch 117/200
## 84/84 - 0s - loss: 0.5763 - accuracy: 0.7133 - val_loss: 0.6287 - val_accuracy: 0.6762 - 101ms/epoch - 1ms/step
## Epoch 118/200
## 84/84 - 0s - loss: 0.5754 - accuracy: 0.7168 - val_loss: 0.6274 - val_accuracy: 0.6762 - 101ms/epoch - 1ms/step
## Epoch 119/200
## 84/84 - 0s - loss: 0.5754 - accuracy: 0.7168 - val_loss: 0.6284 - val_accuracy: 0.6810 - 102ms/epoch - 1ms/step
## Epoch 120/200
## 84/84 - 0s - loss: 0.5751 - accuracy: 0.7157 - val_loss: 0.6285 - val_accuracy: 0.6810 - 102ms/epoch - 1ms/step
## Epoch 121/200
## 84/84 - 0s - loss: 0.5748 - accuracy: 0.7168 - val_loss: 0.6280 - val_accuracy: 0.6762 - 100ms/epoch - 1ms/step
## Epoch 122/200
## 84/84 - 0s - loss: 0.5748 - accuracy: 0.7180 - val_loss: 0.6278 - val_accuracy: 0.6714 - 99ms/epoch - 1ms/step
## Epoch 123/200
## 84/84 - 0s - loss: 0.5755 - accuracy: 0.7133 - val_loss: 0.6277 - val_accuracy: 0.6762 - 105ms/epoch - 1ms/step
## Epoch 124/200
## 84/84 - 0s - loss: 0.5743 - accuracy: 0.7157 - val_loss: 0.6274 - val_accuracy: 0.6714 - 100ms/epoch - 1ms/step
## Epoch 125/200
## 84/84 - 0s - loss: 0.5738 - accuracy: 0.7157 - val_loss: 0.6289 - val_accuracy: 0.6762 - 101ms/epoch - 1ms/step
## Epoch 126/200
## 84/84 - 0s - loss: 0.5738 - accuracy: 0.7168 - val_loss: 0.6281 - val_accuracy: 0.6714 - 100ms/epoch - 1ms/step
## Epoch 127/200
## 84/84 - 0s - loss: 0.5735 - accuracy: 0.7145 - val_loss: 0.6281 - val_accuracy: 0.6762 - 103ms/epoch - 1ms/step
## Epoch 128/200
## 84/84 - 0s - loss: 0.5733 - accuracy: 0.7157 - val_loss: 0.6293 - val_accuracy: 0.6762 - 102ms/epoch - 1ms/step
## Epoch 129/200
## 84/84 - 0s - loss: 0.5732 - accuracy: 0.7204 - val_loss: 0.6278 - val_accuracy: 0.6667 - 100ms/epoch - 1ms/step
## Epoch 130/200
## 84/84 - 0s - loss: 0.5732 - accuracy: 0.7157 - val_loss: 0.6281 - val_accuracy: 0.6714 - 100ms/epoch - 1ms/step
## Epoch 131/200
## 84/84 - 0s - loss: 0.5739 - accuracy: 0.7180 - val_loss: 0.6275 - val_accuracy: 0.6714 - 100ms/epoch - 1ms/step
## Epoch 132/200
## 84/84 - 0s - loss: 0.5730 - accuracy: 0.7204 - val_loss: 0.6280 - val_accuracy: 0.6714 - 100ms/epoch - 1ms/step
## Epoch 133/200
## 84/84 - 0s - loss: 0.5722 - accuracy: 0.7204 - val_loss: 0.6298 - val_accuracy: 0.6762 - 101ms/epoch - 1ms/step
## Epoch 134/200
## 84/84 - 0s - loss: 0.5723 - accuracy: 0.7157 - val_loss: 0.6294 - val_accuracy: 0.6714 - 100ms/epoch - 1ms/step
## Epoch 135/200
## 84/84 - 0s - loss: 0.5720 - accuracy: 0.7168 - val_loss: 0.6293 - val_accuracy: 0.6714 - 100ms/epoch - 1ms/step
## Epoch 136/200
## 84/84 - 0s - loss: 0.5717 - accuracy: 0.7216 - val_loss: 0.6294 - val_accuracy: 0.6762 - 100ms/epoch - 1ms/step
## Epoch 137/200
## 84/84 - 0s - loss: 0.5716 - accuracy: 0.7204 - val_loss: 0.6297 - val_accuracy: 0.6714 - 106ms/epoch - 1ms/step
## Epoch 138/200
## 84/84 - 0s - loss: 0.5715 - accuracy: 0.7216 - val_loss: 0.6303 - val_accuracy: 0.6762 - 102ms/epoch - 1ms/step
## Epoch 139/200
## 84/84 - 0s - loss: 0.5716 - accuracy: 0.7204 - val_loss: 0.6286 - val_accuracy: 0.6667 - 113ms/epoch - 1ms/step
## Epoch 140/200
## 84/84 - 0s - loss: 0.5709 - accuracy: 0.7204 - val_loss: 0.6301 - val_accuracy: 0.6619 - 124ms/epoch - 1ms/step
## Epoch 141/200
## 84/84 - 0s - loss: 0.5706 - accuracy: 0.7204 - val_loss: 0.6301 - val_accuracy: 0.6619 - 103ms/epoch - 1ms/step
## Epoch 142/200
## 84/84 - 0s - loss: 0.5704 - accuracy: 0.7192 - val_loss: 0.6305 - val_accuracy: 0.6667 - 104ms/epoch - 1ms/step
## Epoch 143/200
## 84/84 - 0s - loss: 0.5704 - accuracy: 0.7204 - val_loss: 0.6314 - val_accuracy: 0.6667 - 100ms/epoch - 1ms/step
## Epoch 144/200
## 84/84 - 0s - loss: 0.5704 - accuracy: 0.7192 - val_loss: 0.6306 - val_accuracy: 0.6571 - 99ms/epoch - 1ms/step
## Epoch 145/200
## 84/84 - 0s - loss: 0.5702 - accuracy: 0.7180 - val_loss: 0.6313 - val_accuracy: 0.6667 - 101ms/epoch - 1ms/step
## Epoch 146/200
## 84/84 - 0s - loss: 0.5706 - accuracy: 0.7204 - val_loss: 0.6306 - val_accuracy: 0.6619 - 100ms/epoch - 1ms/step
## Epoch 147/200
## 84/84 - 0s - loss: 0.5701 - accuracy: 0.7192 - val_loss: 0.6328 - val_accuracy: 0.6762 - 100ms/epoch - 1ms/step
## Epoch 148/200
## 84/84 - 0s - loss: 0.5695 - accuracy: 0.7204 - val_loss: 0.6320 - val_accuracy: 0.6762 - 99ms/epoch - 1ms/step
## Epoch 149/200
## 84/84 - 0s - loss: 0.5693 - accuracy: 0.7204 - val_loss: 0.6307 - val_accuracy: 0.6714 - 102ms/epoch - 1ms/step
## Epoch 150/200
## 84/84 - 0s - loss: 0.5693 - accuracy: 0.7228 - val_loss: 0.6306 - val_accuracy: 0.6619 - 102ms/epoch - 1ms/step
## Epoch 151/200
## 84/84 - 0s - loss: 0.5690 - accuracy: 0.7180 - val_loss: 0.6317 - val_accuracy: 0.6762 - 102ms/epoch - 1ms/step
## Epoch 152/200
## 84/84 - 0s - loss: 0.5687 - accuracy: 0.7252 - val_loss: 0.6323 - val_accuracy: 0.6762 - 105ms/epoch - 1ms/step
## Epoch 153/200
## 84/84 - 0s - loss: 0.5686 - accuracy: 0.7204 - val_loss: 0.6324 - val_accuracy: 0.6762 - 100ms/epoch - 1ms/step
## Epoch 154/200
## 84/84 - 0s - loss: 0.5696 - accuracy: 0.7204 - val_loss: 0.6319 - val_accuracy: 0.6619 - 104ms/epoch - 1ms/step
## Epoch 155/200
## 84/84 - 0s - loss: 0.5682 - accuracy: 0.7228 - val_loss: 0.6322 - val_accuracy: 0.6762 - 102ms/epoch - 1ms/step
## Epoch 156/200
## 84/84 - 0s - loss: 0.5680 - accuracy: 0.7204 - val_loss: 0.6316 - val_accuracy: 0.6667 - 102ms/epoch - 1ms/step
## Epoch 157/200
## 84/84 - 0s - loss: 0.5680 - accuracy: 0.7216 - val_loss: 0.6314 - val_accuracy: 0.6667 - 100ms/epoch - 1ms/step
## Epoch 158/200
## 84/84 - 0s - loss: 0.5681 - accuracy: 0.7216 - val_loss: 0.6312 - val_accuracy: 0.6667 - 100ms/epoch - 1ms/step
## Epoch 159/200
## 84/84 - 0s - loss: 0.5678 - accuracy: 0.7145 - val_loss: 0.6344 - val_accuracy: 0.6714 - 98ms/epoch - 1ms/step
## Epoch 160/200
## 84/84 - 0s - loss: 0.5679 - accuracy: 0.7192 - val_loss: 0.6340 - val_accuracy: 0.6714 - 103ms/epoch - 1ms/step
## Epoch 161/200
## 84/84 - 0s - loss: 0.5678 - accuracy: 0.7264 - val_loss: 0.6323 - val_accuracy: 0.6762 - 99ms/epoch - 1ms/step
## Epoch 162/200
## 84/84 - 0s - loss: 0.5674 - accuracy: 0.7216 - val_loss: 0.6328 - val_accuracy: 0.6714 - 102ms/epoch - 1ms/step
## Epoch 163/200
## 84/84 - 0s - loss: 0.5674 - accuracy: 0.7204 - val_loss: 0.6325 - val_accuracy: 0.6762 - 98ms/epoch - 1ms/step
## Epoch 164/200
## 84/84 - 0s - loss: 0.5675 - accuracy: 0.7216 - val_loss: 0.6330 - val_accuracy: 0.6714 - 99ms/epoch - 1ms/step
## Epoch 165/200
## 84/84 - 0s - loss: 0.5670 - accuracy: 0.7216 - val_loss: 0.6338 - val_accuracy: 0.6667 - 99ms/epoch - 1ms/step
## Epoch 166/200
## 84/84 - 0s - loss: 0.5670 - accuracy: 0.7228 - val_loss: 0.6332 - val_accuracy: 0.6667 - 101ms/epoch - 1ms/step
## Epoch 167/200
## 84/84 - 0s - loss: 0.5670 - accuracy: 0.7216 - val_loss: 0.6314 - val_accuracy: 0.6571 - 98ms/epoch - 1ms/step
## Epoch 168/200
## 84/84 - 0s - loss: 0.5669 - accuracy: 0.7252 - val_loss: 0.6319 - val_accuracy: 0.6619 - 101ms/epoch - 1ms/step
## Epoch 169/200
## 84/84 - 0s - loss: 0.5667 - accuracy: 0.7228 - val_loss: 0.6326 - val_accuracy: 0.6667 - 98ms/epoch - 1ms/step
## Epoch 170/200
## 84/84 - 0s - loss: 0.5663 - accuracy: 0.7216 - val_loss: 0.6326 - val_accuracy: 0.6571 - 100ms/epoch - 1ms/step
## Epoch 171/200
## 84/84 - 0s - loss: 0.5667 - accuracy: 0.7288 - val_loss: 0.6329 - val_accuracy: 0.6571 - 99ms/epoch - 1ms/step
## Epoch 172/200
## 84/84 - 0s - loss: 0.5662 - accuracy: 0.7252 - val_loss: 0.6347 - val_accuracy: 0.6667 - 97ms/epoch - 1ms/step
## Epoch 173/200
## 84/84 - 0s - loss: 0.5659 - accuracy: 0.7276 - val_loss: 0.6328 - val_accuracy: 0.6571 - 103ms/epoch - 1ms/step
## Epoch 174/200
## 84/84 - 0s - loss: 0.5659 - accuracy: 0.7240 - val_loss: 0.6345 - val_accuracy: 0.6667 - 99ms/epoch - 1ms/step
## Epoch 175/200
## 84/84 - 0s - loss: 0.5658 - accuracy: 0.7264 - val_loss: 0.6361 - val_accuracy: 0.6667 - 98ms/epoch - 1ms/step
## Epoch 176/200
## 84/84 - 0s - loss: 0.5657 - accuracy: 0.7276 - val_loss: 0.6347 - val_accuracy: 0.6667 - 101ms/epoch - 1ms/step
## Epoch 177/200
## 84/84 - 0s - loss: 0.5660 - accuracy: 0.7192 - val_loss: 0.6345 - val_accuracy: 0.6667 - 99ms/epoch - 1ms/step
## Epoch 178/200
## 84/84 - 0s - loss: 0.5652 - accuracy: 0.7288 - val_loss: 0.6333 - val_accuracy: 0.6571 - 99ms/epoch - 1ms/step
## Epoch 179/200
## 84/84 - 0s - loss: 0.5650 - accuracy: 0.7240 - val_loss: 0.6339 - val_accuracy: 0.6571 - 99ms/epoch - 1ms/step
## Epoch 180/200
## 84/84 - 0s - loss: 0.5649 - accuracy: 0.7276 - val_loss: 0.6329 - val_accuracy: 0.6571 - 98ms/epoch - 1ms/step
## Epoch 181/200
## 84/84 - 0s - loss: 0.5646 - accuracy: 0.7240 - val_loss: 0.6342 - val_accuracy: 0.6571 - 102ms/epoch - 1ms/step
## Epoch 182/200
## 84/84 - 0s - loss: 0.5649 - accuracy: 0.7264 - val_loss: 0.6352 - val_accuracy: 0.6667 - 103ms/epoch - 1ms/step
## Epoch 183/200
## 84/84 - 0s - loss: 0.5644 - accuracy: 0.7240 - val_loss: 0.6343 - val_accuracy: 0.6571 - 105ms/epoch - 1ms/step
## Epoch 184/200
## 84/84 - 0s - loss: 0.5641 - accuracy: 0.7312 - val_loss: 0.6351 - val_accuracy: 0.6571 - 98ms/epoch - 1ms/step
## Epoch 185/200
## 84/84 - 0s - loss: 0.5645 - accuracy: 0.7276 - val_loss: 0.6348 - val_accuracy: 0.6571 - 99ms/epoch - 1ms/step
## Epoch 186/200
## 84/84 - 0s - loss: 0.5644 - accuracy: 0.7240 - val_loss: 0.6344 - val_accuracy: 0.6571 - 100ms/epoch - 1ms/step
## Epoch 187/200
## 84/84 - 0s - loss: 0.5641 - accuracy: 0.7240 - val_loss: 0.6356 - val_accuracy: 0.6619 - 97ms/epoch - 1ms/step
## Epoch 188/200
## 84/84 - 0s - loss: 0.5640 - accuracy: 0.7240 - val_loss: 0.6352 - val_accuracy: 0.6571 - 99ms/epoch - 1ms/step
## Epoch 189/200
## 84/84 - 0s - loss: 0.5640 - accuracy: 0.7264 - val_loss: 0.6332 - val_accuracy: 0.6476 - 98ms/epoch - 1ms/step
## Epoch 190/200
## 84/84 - 0s - loss: 0.5636 - accuracy: 0.7228 - val_loss: 0.6344 - val_accuracy: 0.6571 - 98ms/epoch - 1ms/step
## Epoch 191/200
## 84/84 - 0s - loss: 0.5638 - accuracy: 0.7228 - val_loss: 0.6354 - val_accuracy: 0.6571 - 97ms/epoch - 1ms/step
## Epoch 192/200
## 84/84 - 0s - loss: 0.5638 - accuracy: 0.7252 - val_loss: 0.6344 - val_accuracy: 0.6571 - 97ms/epoch - 1ms/step
## Epoch 193/200
## 84/84 - 0s - loss: 0.5638 - accuracy: 0.7264 - val_loss: 0.6340 - val_accuracy: 0.6571 - 105ms/epoch - 1ms/step
## Epoch 194/200
## 84/84 - 0s - loss: 0.5632 - accuracy: 0.7216 - val_loss: 0.6340 - val_accuracy: 0.6524 - 101ms/epoch - 1ms/step
## Epoch 195/200
## 84/84 - 0s - loss: 0.5634 - accuracy: 0.7264 - val_loss: 0.6344 - val_accuracy: 0.6571 - 100ms/epoch - 1ms/step
## Epoch 196/200
## 84/84 - 0s - loss: 0.5628 - accuracy: 0.7264 - val_loss: 0.6349 - val_accuracy: 0.6571 - 98ms/epoch - 1ms/step
## Epoch 197/200
## 84/84 - 0s - loss: 0.5631 - accuracy: 0.7240 - val_loss: 0.6351 - val_accuracy: 0.6571 - 97ms/epoch - 1ms/step
## Epoch 198/200
## 84/84 - 0s - loss: 0.5628 - accuracy: 0.7240 - val_loss: 0.6343 - val_accuracy: 0.6524 - 98ms/epoch - 1ms/step
## Epoch 199/200
## 84/84 - 0s - loss: 0.5625 - accuracy: 0.7240 - val_loss: 0.6346 - val_accuracy: 0.6524 - 97ms/epoch - 1ms/step
## Epoch 200/200
## 84/84 - 0s - loss: 0.5624 - accuracy: 0.7240 - val_loss: 0.6350 - val_accuracy: 0.6571 - 97ms/epoch - 1ms/step5.7 Convolutional Neural Networks (CNNs)
Convolutional Neural Networks represent a specific type of Deep Learning algorithm that incorporates the topological, geometric, spatial and temporal structure of the input data (generally images) and assigns importance by learning the weights and biases of the (image) intensities associated with the objects or affinities present in the data. These important features are then utilized to differentiate between datasets (images) or components within the data (structure and objects in images). CNNs require less pre-processing compared to other DL classification algorithms, which may depend on manually-specified filters. CNNs tend to learn these filters by iteratively extrapolating multi-resolution characteristics in the data objects by convolution methods. See the DSPA Appendix for the mathematical operation convolution and its applications in image processing.
Recall that one may attempt to learn the features of an image (or a higher dimensional tensor) by flattening the image array (matrix/tensor) into a 1D vector. This vectorization works well if there are no spatiotemporal dependencies in the data. Most of the time, there are such image intensity correlations that can’t be ignored. The CNN architecture facilitates a mechanism to better model the intrinsic image affinities, reduce the number of DNN parameters, and produce more reliable predictions. Many images are represented as tensors whose modes (dimensions) encode spatial, temporal, color-channel, and other information about the observed image intensity. For instance, an RGB image of size \(1,000 \times 1,000=10^6\) pixels, may require 3MB of memory/storage. A CNN learns to encode the image into a higher-dimensional multispectral hierarchical tensor encoding the intrinsic image characteristics that can lead to easy classification of similar images or generation of synthetic images. For instance, ignoring the color-channels and using a stride=10, convolving the original image of dimension with a kernel of size \(10\times 10\) would yield another (smoother) lower-resolution image of size \(100\times 100\), encoding the convolved features.
The convolution process aims to extract the high-level features such as edges, borders, and contrasts from the input image. CNNs involve both convolutional and dense layers. Much like the Fourier transform, the first convolutional layer captures low-level features such as edges, color, gradient orientation, etc. Subsequent layers progressively add higher-level details and the entire CNN holistically encodes the understanding of the input image structure.
Convolution, de-convolution (the reverse process) and padding reduce or increase the image dimensionality. Most CNNs mix convolutional layers with pooling layers. The latter are responsible for reducing the spatial size of the convolved features, which decreases the computational data processing demand. Pooling may be implemented as Max Pooling or Average Pooling. Max-pooling takes an image patch defined by the kernel and returns the maximum intensity value. It performs noise-suppression as it decimates noisy pixel intensities, denoises the image, and reduces the image dimensions. Average-pooling returns the average of all intensity values covered by the image-kernel and reduces the image dimension.
Jointly, the convolutional and pooling processes form the CNN \(i\)-th layer and the number of layers may reflect the ANN complexity. Fully connected layers are typically added to the ANN architecture to enhance the classification, prediction, or regression performance of DL models. Fully-connected layers provide a mechanism to learn non-linear associations and non-affine characteristics of high-level features captured as outputs of the convolutional layers.
5.8 Model EDA
We can visualize the model fitting process using
keras::plot() jointly depicting the loss of the objective
function and the accuracy of the model, across epochs. Alternatively, we
can split the pair of plots - one for the model loss and the
other for the model accuracy. The \(\$\) operator is used to access the tensor
data and plot it step-by-step. A sign of overfitting may be an accuracy
(on training data) that keeps improving while the accuracy (on the
validation data) worsens. This may be an indication that the NN model
started to learn noise in the data instead of learning real
patterns or affinities in the data. While the accuracy trends of both
datasets are rising towards the final epochs, this may indicate that the
model is still in the process of learning on the training dataset (and
we can increase the number of epochs).
# Plot the history
# plot(track.model.1)
#
# # NN model loss on the training data
# plot(track.model.1$metrics$loss, main="Model 1 Loss",
# xlab = "Epoch", ylab="Loss", col="green", type="l", ylim=c(0.54, 0.6))
#
# # NN model loss of the 20% validation data
# lines(track.model.1$metrics$val_loss, col="blue", type="l")
#
# # Add legend
# legend("right", c("train", "test"), col=c("green", "blue"), lty=c(1,1))
#
# # Plot the accuracy of the training data
# plot(track.model.1$metrics$acc, main="Model 1 Accuracy",
# xlab = "Epoch", ylab="Accuracy", col="blue", type="l", ylim=c(0.65, 0.75))
#
# # Plot the accuracy of the validation data
# lines(track.model.1$metrics$val_acc, col="green")
#
# # Add Legend
# legend("bottom", c("Training", "Testing"), col=c("blue", "green"), lty=c(1,1))
## plot_ly
epochs <- 200
time <- 1:epochs
hist_df <- data.frame(time=time, loss=track.model.1$metrics$loss, acc=track.model.1$metrics$acc,
valid_loss=track.model.1$metrics$val_loss, valid_acc=track.model.1$metrics$val_acc)
plot_ly(hist_df, x = ~time) %>%
add_trace(y = ~loss, name = 'training loss', mode = 'lines') %>%
add_trace(y = ~acc, name = 'training accuracy', mode = 'lines+markers') %>%
add_trace(y = ~valid_loss, name = 'validation loss',mode = 'lines+markers') %>%
add_trace(y = ~valid_acc, name = 'validation accuracy', mode = 'lines+markers') %>%
layout(title="Titanic NN Model Performance",
legend = list(orientation = 'h'), yaxis=list(title="metric"))5.9 Passenger Survival Forecasting using New Data
Once the model is fit, we can use it to predict the survival of
passengers using the testing data, test_dat2.X. As we have
seen before, predict() provides this functionality.
Finally, we can evaluate the performance of the NN model by comparing
the predicted class labels and test_dat2.Y using
table() or confusionMatrix().
# Predict the classes for the test data
predict.survival <- model.1 %>% predict(test_dat2.X, batch_size = 30) %>% k_argmax()## 9/9 - 0s - 70ms/epoch - 8ms/step# Confusion matrix
test_dat2.Y <- dat1[-train_set_ind , 8]
table(test_dat2.Y, predict.survival$numpy())##
## test_dat2.Y 0 1
## 0 147 24
## 1 53 38## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 147 24
## 1 53 38
##
## Accuracy : 0.7061
## 95% CI : (0.6469, 0.7606)
## No Information Rate : 0.7634
## P-Value [Acc > NIR] : 0.986357
##
## Kappa : 0.2996
##
## Mcnemar's Test P-Value : 0.001418
##
## Sensitivity : 0.7350
## Specificity : 0.6129
## Pos Pred Value : 0.8596
## Neg Pred Value : 0.4176
## Prevalence : 0.7634
## Detection Rate : 0.5611
## Detection Prevalence : 0.6527
## Balanced Accuracy : 0.6740
##
## 'Positive' Class : 0
## We can also utilize the evaluate() function to assess
the model quality using testing data.
# Evaluate on test data and labels
test_dat2.Y <- to_categorical(test_dat2.Y)
model1.qual <- model.1 %>% evaluate(test_dat2.X, test_dat2.Y, batch_size = 30)## 9/9 - 0s - loss: 0.5913 - accuracy: 0.7061 - 68ms/epoch - 8ms/step## loss accuracy
## 0.5913115 0.70610685.10 Fine-tuning the NN Model
The main NN model parameters we can adjust to improve the model quality include:
- the number of layers,
- the number of nodes within layers (hidden units),
- the number of epochs,
- the batch size.
Models can be improved by adding additional layers, increasing the
number of hidden units, and by tuning the optimization parameters in
compile(). Let’s first try to add another layer to the N
model.
# Initialize the sequential model
model.2 <- keras_model_sequential()
# Add layers to model
model.2 %>%
layer_dense(units = 8, activation = 'relu', input_shape = c(4)) %>%
layer_dense(units = 6, activation = 'relu') %>%
layer_dense(units = 2, activation = 'softmax')
# Compile the model
model.2 %>% compile(
loss = 'binary_crossentropy',
optimizer = 'adam',
metrics = 'accuracy'
)
# Fit NN model to training data & Save the training history
track.model.2 <- model.2 %>% fit(
train_dat2.X,
train_dat2.Y,
epochs = 200,
batch_size = 10,
validation_split = 0.2
)## Epoch 1/200
## 84/84 - 0s - loss: 0.6752 - accuracy: 0.6428 - val_loss: 0.6693 - val_accuracy: 0.6476 - 492ms/epoch - 6ms/step
## Epoch 2/200
## 84/84 - 0s - loss: 0.6506 - accuracy: 0.6535 - val_loss: 0.6537 - val_accuracy: 0.6762 - 110ms/epoch - 1ms/step
## Epoch 3/200
## 84/84 - 0s - loss: 0.6326 - accuracy: 0.6786 - val_loss: 0.6466 - val_accuracy: 0.6524 - 106ms/epoch - 1ms/step
## Epoch 4/200
## 84/84 - 0s - loss: 0.6206 - accuracy: 0.6703 - val_loss: 0.6386 - val_accuracy: 0.6905 - 106ms/epoch - 1ms/step
## Epoch 5/200
## 84/84 - 0s - loss: 0.6107 - accuracy: 0.6726 - val_loss: 0.6329 - val_accuracy: 0.6714 - 112ms/epoch - 1ms/step
## Epoch 6/200
## 84/84 - 0s - loss: 0.6061 - accuracy: 0.6703 - val_loss: 0.6307 - val_accuracy: 0.6571 - 119ms/epoch - 1ms/step
## Epoch 7/200
## 84/84 - 0s - loss: 0.6027 - accuracy: 0.6726 - val_loss: 0.6282 - val_accuracy: 0.6667 - 109ms/epoch - 1ms/step
## Epoch 8/200
## 84/84 - 0s - loss: 0.5998 - accuracy: 0.6834 - val_loss: 0.6264 - val_accuracy: 0.6667 - 109ms/epoch - 1ms/step
## Epoch 9/200
## 84/84 - 0s - loss: 0.5986 - accuracy: 0.6786 - val_loss: 0.6248 - val_accuracy: 0.6762 - 106ms/epoch - 1ms/step
## Epoch 10/200
## 84/84 - 0s - loss: 0.5973 - accuracy: 0.6834 - val_loss: 0.6238 - val_accuracy: 0.6810 - 136ms/epoch - 2ms/step
## Epoch 11/200
## 84/84 - 0s - loss: 0.5960 - accuracy: 0.6834 - val_loss: 0.6242 - val_accuracy: 0.6810 - 106ms/epoch - 1ms/step
## Epoch 12/200
## 84/84 - 0s - loss: 0.5957 - accuracy: 0.6846 - val_loss: 0.6209 - val_accuracy: 0.6857 - 109ms/epoch - 1ms/step
## Epoch 13/200
## 84/84 - 0s - loss: 0.5957 - accuracy: 0.6834 - val_loss: 0.6216 - val_accuracy: 0.6810 - 111ms/epoch - 1ms/step
## Epoch 14/200
## 84/84 - 0s - loss: 0.5939 - accuracy: 0.6882 - val_loss: 0.6283 - val_accuracy: 0.6762 - 110ms/epoch - 1ms/step
## Epoch 15/200
## 84/84 - 0s - loss: 0.5936 - accuracy: 0.6846 - val_loss: 0.6251 - val_accuracy: 0.6905 - 109ms/epoch - 1ms/step
## Epoch 16/200
## 84/84 - 0s - loss: 0.5948 - accuracy: 0.6858 - val_loss: 0.6267 - val_accuracy: 0.6810 - 130ms/epoch - 2ms/step
## Epoch 17/200
## 84/84 - 0s - loss: 0.5927 - accuracy: 0.6846 - val_loss: 0.6229 - val_accuracy: 0.6810 - 105ms/epoch - 1ms/step
## Epoch 18/200
## 84/84 - 0s - loss: 0.5925 - accuracy: 0.6846 - val_loss: 0.6236 - val_accuracy: 0.6857 - 104ms/epoch - 1ms/step
## Epoch 19/200
## 84/84 - 0s - loss: 0.5922 - accuracy: 0.6846 - val_loss: 0.6192 - val_accuracy: 0.6667 - 109ms/epoch - 1ms/step
## Epoch 20/200
## 84/84 - 0s - loss: 0.5922 - accuracy: 0.6774 - val_loss: 0.6258 - val_accuracy: 0.6952 - 111ms/epoch - 1ms/step
## Epoch 21/200
## 84/84 - 0s - loss: 0.5924 - accuracy: 0.6834 - val_loss: 0.6221 - val_accuracy: 0.6810 - 116ms/epoch - 1ms/step
## Epoch 22/200
## 84/84 - 0s - loss: 0.5920 - accuracy: 0.6822 - val_loss: 0.6258 - val_accuracy: 0.6905 - 105ms/epoch - 1ms/step
## Epoch 23/200
## 84/84 - 0s - loss: 0.5908 - accuracy: 0.6810 - val_loss: 0.6249 - val_accuracy: 0.6905 - 102ms/epoch - 1ms/step
## Epoch 24/200
## 84/84 - 0s - loss: 0.5903 - accuracy: 0.6810 - val_loss: 0.6212 - val_accuracy: 0.6857 - 103ms/epoch - 1ms/step
## Epoch 25/200
## 84/84 - 0s - loss: 0.5903 - accuracy: 0.6822 - val_loss: 0.6266 - val_accuracy: 0.6905 - 114ms/epoch - 1ms/step
## Epoch 26/200
## 84/84 - 0s - loss: 0.5898 - accuracy: 0.6846 - val_loss: 0.6242 - val_accuracy: 0.6810 - 126ms/epoch - 1ms/step
## Epoch 27/200
## 84/84 - 0s - loss: 0.5893 - accuracy: 0.6846 - val_loss: 0.6224 - val_accuracy: 0.6810 - 105ms/epoch - 1ms/step
## Epoch 28/200
## 84/84 - 0s - loss: 0.5889 - accuracy: 0.6834 - val_loss: 0.6249 - val_accuracy: 0.6857 - 112ms/epoch - 1ms/step
## Epoch 29/200
## 84/84 - 0s - loss: 0.5893 - accuracy: 0.6822 - val_loss: 0.6221 - val_accuracy: 0.6857 - 110ms/epoch - 1ms/step
## Epoch 30/200
## 84/84 - 0s - loss: 0.5893 - accuracy: 0.6798 - val_loss: 0.6242 - val_accuracy: 0.6857 - 105ms/epoch - 1ms/step
## Epoch 31/200
## 84/84 - 0s - loss: 0.5887 - accuracy: 0.6846 - val_loss: 0.6229 - val_accuracy: 0.6810 - 107ms/epoch - 1ms/step
## Epoch 32/200
## 84/84 - 0s - loss: 0.5891 - accuracy: 0.6798 - val_loss: 0.6229 - val_accuracy: 0.6810 - 99ms/epoch - 1ms/step
## Epoch 33/200
## 84/84 - 0s - loss: 0.5879 - accuracy: 0.6846 - val_loss: 0.6191 - val_accuracy: 0.6714 - 107ms/epoch - 1ms/step
## Epoch 34/200
## 84/84 - 0s - loss: 0.5874 - accuracy: 0.6810 - val_loss: 0.6258 - val_accuracy: 0.6857 - 106ms/epoch - 1ms/step
## Epoch 35/200
## 84/84 - 0s - loss: 0.5868 - accuracy: 0.6822 - val_loss: 0.6217 - val_accuracy: 0.6762 - 100ms/epoch - 1ms/step
## Epoch 36/200
## 84/84 - 0s - loss: 0.5862 - accuracy: 0.6798 - val_loss: 0.6233 - val_accuracy: 0.6857 - 118ms/epoch - 1ms/step
## Epoch 37/200
## 84/84 - 0s - loss: 0.5865 - accuracy: 0.6882 - val_loss: 0.6253 - val_accuracy: 0.6810 - 111ms/epoch - 1ms/step
## Epoch 38/200
## 84/84 - 0s - loss: 0.5857 - accuracy: 0.6834 - val_loss: 0.6244 - val_accuracy: 0.6810 - 117ms/epoch - 1ms/step
## Epoch 39/200
## 84/84 - 0s - loss: 0.5856 - accuracy: 0.6882 - val_loss: 0.6208 - val_accuracy: 0.6714 - 113ms/epoch - 1ms/step
## Epoch 40/200
## 84/84 - 0s - loss: 0.5848 - accuracy: 0.6858 - val_loss: 0.6215 - val_accuracy: 0.6857 - 141ms/epoch - 2ms/step
## Epoch 41/200
## 84/84 - 0s - loss: 0.5855 - accuracy: 0.6977 - val_loss: 0.6261 - val_accuracy: 0.6857 - 113ms/epoch - 1ms/step
## Epoch 42/200
## 84/84 - 0s - loss: 0.5844 - accuracy: 0.6906 - val_loss: 0.6229 - val_accuracy: 0.6810 - 107ms/epoch - 1ms/step
## Epoch 43/200
## 84/84 - 0s - loss: 0.5837 - accuracy: 0.6906 - val_loss: 0.6253 - val_accuracy: 0.6810 - 114ms/epoch - 1ms/step
## Epoch 44/200
## 84/84 - 0s - loss: 0.5839 - accuracy: 0.6965 - val_loss: 0.6220 - val_accuracy: 0.6857 - 117ms/epoch - 1ms/step
## Epoch 45/200
## 84/84 - 0s - loss: 0.5829 - accuracy: 0.7013 - val_loss: 0.6218 - val_accuracy: 0.6905 - 115ms/epoch - 1ms/step
## Epoch 46/200
## 84/84 - 0s - loss: 0.5830 - accuracy: 0.6906 - val_loss: 0.6217 - val_accuracy: 0.6905 - 124ms/epoch - 1ms/step
## Epoch 47/200
## 84/84 - 0s - loss: 0.5836 - accuracy: 0.6894 - val_loss: 0.6271 - val_accuracy: 0.6952 - 120ms/epoch - 1ms/step
## Epoch 48/200
## 84/84 - 0s - loss: 0.5829 - accuracy: 0.6965 - val_loss: 0.6210 - val_accuracy: 0.6952 - 123ms/epoch - 1ms/step
## Epoch 49/200
## 84/84 - 0s - loss: 0.5819 - accuracy: 0.6918 - val_loss: 0.6247 - val_accuracy: 0.6905 - 114ms/epoch - 1ms/step
## Epoch 50/200
## 84/84 - 0s - loss: 0.5827 - accuracy: 0.7049 - val_loss: 0.6246 - val_accuracy: 0.6857 - 117ms/epoch - 1ms/step
## Epoch 51/200
## 84/84 - 0s - loss: 0.5812 - accuracy: 0.7073 - val_loss: 0.6193 - val_accuracy: 0.6952 - 109ms/epoch - 1ms/step
## Epoch 52/200
## 84/84 - 0s - loss: 0.5815 - accuracy: 0.6965 - val_loss: 0.6233 - val_accuracy: 0.6905 - 108ms/epoch - 1ms/step
## Epoch 53/200
## 84/84 - 0s - loss: 0.5811 - accuracy: 0.7001 - val_loss: 0.6197 - val_accuracy: 0.6952 - 106ms/epoch - 1ms/step
## Epoch 54/200
## 84/84 - 0s - loss: 0.5811 - accuracy: 0.7001 - val_loss: 0.6241 - val_accuracy: 0.6857 - 133ms/epoch - 2ms/step
## Epoch 55/200
## 84/84 - 0s - loss: 0.5812 - accuracy: 0.7037 - val_loss: 0.6237 - val_accuracy: 0.6857 - 134ms/epoch - 2ms/step
## Epoch 56/200
## 84/84 - 0s - loss: 0.5807 - accuracy: 0.7145 - val_loss: 0.6188 - val_accuracy: 0.6905 - 105ms/epoch - 1ms/step
## Epoch 57/200
## 84/84 - 0s - loss: 0.5804 - accuracy: 0.7121 - val_loss: 0.6173 - val_accuracy: 0.6762 - 108ms/epoch - 1ms/step
## Epoch 58/200
## 84/84 - 0s - loss: 0.5797 - accuracy: 0.7097 - val_loss: 0.6231 - val_accuracy: 0.6810 - 108ms/epoch - 1ms/step
## Epoch 59/200
## 84/84 - 0s - loss: 0.5795 - accuracy: 0.7097 - val_loss: 0.6184 - val_accuracy: 0.6905 - 109ms/epoch - 1ms/step
## Epoch 60/200
## 84/84 - 0s - loss: 0.5794 - accuracy: 0.7097 - val_loss: 0.6299 - val_accuracy: 0.6905 - 106ms/epoch - 1ms/step
## Epoch 61/200
## 84/84 - 0s - loss: 0.5808 - accuracy: 0.7097 - val_loss: 0.6236 - val_accuracy: 0.6857 - 109ms/epoch - 1ms/step
## Epoch 62/200
## 84/84 - 0s - loss: 0.5794 - accuracy: 0.7192 - val_loss: 0.6174 - val_accuracy: 0.6810 - 105ms/epoch - 1ms/step
## Epoch 63/200
## 84/84 - 0s - loss: 0.5787 - accuracy: 0.7097 - val_loss: 0.6219 - val_accuracy: 0.6857 - 115ms/epoch - 1ms/step
## Epoch 64/200
## 84/84 - 0s - loss: 0.5789 - accuracy: 0.7109 - val_loss: 0.6163 - val_accuracy: 0.6714 - 105ms/epoch - 1ms/step
## Epoch 65/200
## 84/84 - 0s - loss: 0.5777 - accuracy: 0.7085 - val_loss: 0.6222 - val_accuracy: 0.6810 - 145ms/epoch - 2ms/step
## Epoch 66/200
## 84/84 - 0s - loss: 0.5779 - accuracy: 0.7157 - val_loss: 0.6221 - val_accuracy: 0.6857 - 100ms/epoch - 1ms/step
## Epoch 67/200
## 84/84 - 0s - loss: 0.5784 - accuracy: 0.7109 - val_loss: 0.6197 - val_accuracy: 0.6857 - 95ms/epoch - 1ms/step
## Epoch 68/200
## 84/84 - 0s - loss: 0.5773 - accuracy: 0.7157 - val_loss: 0.6231 - val_accuracy: 0.6857 - 95ms/epoch - 1ms/step
## Epoch 69/200
## 84/84 - 0s - loss: 0.5775 - accuracy: 0.7037 - val_loss: 0.6252 - val_accuracy: 0.6857 - 93ms/epoch - 1ms/step
## Epoch 70/200
## 84/84 - 0s - loss: 0.5775 - accuracy: 0.7228 - val_loss: 0.6198 - val_accuracy: 0.6857 - 94ms/epoch - 1ms/step
## Epoch 71/200
## 84/84 - 0s - loss: 0.5785 - accuracy: 0.7121 - val_loss: 0.6213 - val_accuracy: 0.6857 - 98ms/epoch - 1ms/step
## Epoch 72/200
## 84/84 - 0s - loss: 0.5769 - accuracy: 0.7133 - val_loss: 0.6304 - val_accuracy: 0.6905 - 95ms/epoch - 1ms/step
## Epoch 73/200
## 84/84 - 0s - loss: 0.5763 - accuracy: 0.7228 - val_loss: 0.6162 - val_accuracy: 0.6762 - 95ms/epoch - 1ms/step
## Epoch 74/200
## 84/84 - 0s - loss: 0.5769 - accuracy: 0.7121 - val_loss: 0.6220 - val_accuracy: 0.6857 - 102ms/epoch - 1ms/step
## Epoch 75/200
## 84/84 - 0s - loss: 0.5757 - accuracy: 0.7216 - val_loss: 0.6190 - val_accuracy: 0.6810 - 97ms/epoch - 1ms/step
## Epoch 76/200
## 84/84 - 0s - loss: 0.5767 - accuracy: 0.7109 - val_loss: 0.6205 - val_accuracy: 0.6857 - 96ms/epoch - 1ms/step
## Epoch 77/200
## 84/84 - 0s - loss: 0.5752 - accuracy: 0.7228 - val_loss: 0.6200 - val_accuracy: 0.6810 - 94ms/epoch - 1ms/step
## Epoch 78/200
## 84/84 - 0s - loss: 0.5750 - accuracy: 0.7180 - val_loss: 0.6266 - val_accuracy: 0.6857 - 97ms/epoch - 1ms/step
## Epoch 79/200
## 84/84 - 0s - loss: 0.5751 - accuracy: 0.7204 - val_loss: 0.6231 - val_accuracy: 0.6857 - 93ms/epoch - 1ms/step
## Epoch 80/200
## 84/84 - 0s - loss: 0.5745 - accuracy: 0.7192 - val_loss: 0.6239 - val_accuracy: 0.6857 - 89ms/epoch - 1ms/step
## Epoch 81/200
## 84/84 - 0s - loss: 0.5748 - accuracy: 0.7133 - val_loss: 0.6284 - val_accuracy: 0.6762 - 95ms/epoch - 1ms/step
## Epoch 82/200
## 84/84 - 0s - loss: 0.5738 - accuracy: 0.7157 - val_loss: 0.6194 - val_accuracy: 0.6810 - 95ms/epoch - 1ms/step
## Epoch 83/200
## 84/84 - 0s - loss: 0.5735 - accuracy: 0.7228 - val_loss: 0.6236 - val_accuracy: 0.6857 - 94ms/epoch - 1ms/step
## Epoch 84/200
## 84/84 - 0s - loss: 0.5737 - accuracy: 0.7168 - val_loss: 0.6285 - val_accuracy: 0.6762 - 101ms/epoch - 1ms/step
## Epoch 85/200
## 84/84 - 0s - loss: 0.5734 - accuracy: 0.7157 - val_loss: 0.6232 - val_accuracy: 0.6857 - 103ms/epoch - 1ms/step
## Epoch 86/200
## 84/84 - 0s - loss: 0.5744 - accuracy: 0.7180 - val_loss: 0.6217 - val_accuracy: 0.6857 - 96ms/epoch - 1ms/step
## Epoch 87/200
## 84/84 - 0s - loss: 0.5733 - accuracy: 0.7133 - val_loss: 0.6197 - val_accuracy: 0.6810 - 91ms/epoch - 1ms/step
## Epoch 88/200
## 84/84 - 0s - loss: 0.5724 - accuracy: 0.7192 - val_loss: 0.6285 - val_accuracy: 0.6762 - 101ms/epoch - 1ms/step
## Epoch 89/200
## 84/84 - 0s - loss: 0.5714 - accuracy: 0.7240 - val_loss: 0.6195 - val_accuracy: 0.6714 - 94ms/epoch - 1ms/step
## Epoch 90/200
## 84/84 - 0s - loss: 0.5730 - accuracy: 0.7216 - val_loss: 0.6242 - val_accuracy: 0.6810 - 92ms/epoch - 1ms/step
## Epoch 91/200
## 84/84 - 0s - loss: 0.5729 - accuracy: 0.7180 - val_loss: 0.6220 - val_accuracy: 0.6810 - 89ms/epoch - 1ms/step
## Epoch 92/200
## 84/84 - 0s - loss: 0.5715 - accuracy: 0.7204 - val_loss: 0.6265 - val_accuracy: 0.6762 - 100ms/epoch - 1ms/step
## Epoch 93/200
## 84/84 - 0s - loss: 0.5721 - accuracy: 0.7204 - val_loss: 0.6292 - val_accuracy: 0.6762 - 93ms/epoch - 1ms/step
## Epoch 94/200
## 84/84 - 0s - loss: 0.5719 - accuracy: 0.7145 - val_loss: 0.6359 - val_accuracy: 0.6619 - 93ms/epoch - 1ms/step
## Epoch 95/200
## 84/84 - 0s - loss: 0.5717 - accuracy: 0.7228 - val_loss: 0.6268 - val_accuracy: 0.6810 - 91ms/epoch - 1ms/step
## Epoch 96/200
## 84/84 - 0s - loss: 0.5707 - accuracy: 0.7204 - val_loss: 0.6232 - val_accuracy: 0.6714 - 98ms/epoch - 1ms/step
## Epoch 97/200
## 84/84 - 0s - loss: 0.5702 - accuracy: 0.7228 - val_loss: 0.6271 - val_accuracy: 0.6762 - 98ms/epoch - 1ms/step
## Epoch 98/200
## 84/84 - 0s - loss: 0.5707 - accuracy: 0.7228 - val_loss: 0.6225 - val_accuracy: 0.6667 - 94ms/epoch - 1ms/step
## Epoch 99/200
## 84/84 - 0s - loss: 0.5707 - accuracy: 0.7168 - val_loss: 0.6274 - val_accuracy: 0.6762 - 97ms/epoch - 1ms/step
## Epoch 100/200
## 84/84 - 0s - loss: 0.5699 - accuracy: 0.7180 - val_loss: 0.6263 - val_accuracy: 0.6810 - 91ms/epoch - 1ms/step
## Epoch 101/200
## 84/84 - 0s - loss: 0.5709 - accuracy: 0.7252 - val_loss: 0.6211 - val_accuracy: 0.6667 - 93ms/epoch - 1ms/step
## Epoch 102/200
## 84/84 - 0s - loss: 0.5702 - accuracy: 0.7240 - val_loss: 0.6267 - val_accuracy: 0.6762 - 93ms/epoch - 1ms/step
## Epoch 103/200
## 84/84 - 0s - loss: 0.5693 - accuracy: 0.7180 - val_loss: 0.6217 - val_accuracy: 0.6619 - 88ms/epoch - 1ms/step
## Epoch 104/200
## 84/84 - 0s - loss: 0.5683 - accuracy: 0.7145 - val_loss: 0.6261 - val_accuracy: 0.6810 - 97ms/epoch - 1ms/step
## Epoch 105/200
## 84/84 - 0s - loss: 0.5685 - accuracy: 0.7180 - val_loss: 0.6225 - val_accuracy: 0.6619 - 94ms/epoch - 1ms/step
## Epoch 106/200
## 84/84 - 0s - loss: 0.5682 - accuracy: 0.7228 - val_loss: 0.6273 - val_accuracy: 0.6810 - 95ms/epoch - 1ms/step
## Epoch 107/200
## 84/84 - 0s - loss: 0.5681 - accuracy: 0.7228 - val_loss: 0.6208 - val_accuracy: 0.6667 - 96ms/epoch - 1ms/step
## Epoch 108/200
## 84/84 - 0s - loss: 0.5702 - accuracy: 0.7216 - val_loss: 0.6234 - val_accuracy: 0.6619 - 92ms/epoch - 1ms/step
## Epoch 109/200
## 84/84 - 0s - loss: 0.5678 - accuracy: 0.7204 - val_loss: 0.6262 - val_accuracy: 0.6714 - 94ms/epoch - 1ms/step
## Epoch 110/200
## 84/84 - 0s - loss: 0.5678 - accuracy: 0.7168 - val_loss: 0.6335 - val_accuracy: 0.6762 - 90ms/epoch - 1ms/step
## Epoch 111/200
## 84/84 - 0s - loss: 0.5680 - accuracy: 0.7216 - val_loss: 0.6234 - val_accuracy: 0.6667 - 96ms/epoch - 1ms/step
## Epoch 112/200
## 84/84 - 0s - loss: 0.5675 - accuracy: 0.7216 - val_loss: 0.6239 - val_accuracy: 0.6619 - 94ms/epoch - 1ms/step
## Epoch 113/200
## 84/84 - 0s - loss: 0.5680 - accuracy: 0.7204 - val_loss: 0.6308 - val_accuracy: 0.6714 - 95ms/epoch - 1ms/step
## Epoch 114/200
## 84/84 - 0s - loss: 0.5678 - accuracy: 0.7216 - val_loss: 0.6272 - val_accuracy: 0.6667 - 100ms/epoch - 1ms/step
## Epoch 115/200
## 84/84 - 0s - loss: 0.5669 - accuracy: 0.7204 - val_loss: 0.6251 - val_accuracy: 0.6619 - 97ms/epoch - 1ms/step
## Epoch 116/200
## 84/84 - 0s - loss: 0.5666 - accuracy: 0.7216 - val_loss: 0.6269 - val_accuracy: 0.6619 - 96ms/epoch - 1ms/step
## Epoch 117/200
## 84/84 - 0s - loss: 0.5670 - accuracy: 0.7192 - val_loss: 0.6263 - val_accuracy: 0.6619 - 97ms/epoch - 1ms/step
## Epoch 118/200
## 84/84 - 0s - loss: 0.5665 - accuracy: 0.7216 - val_loss: 0.6222 - val_accuracy: 0.6667 - 98ms/epoch - 1ms/step
## Epoch 119/200
## 84/84 - 0s - loss: 0.5664 - accuracy: 0.7192 - val_loss: 0.6278 - val_accuracy: 0.6619 - 95ms/epoch - 1ms/step
## Epoch 120/200
## 84/84 - 0s - loss: 0.5661 - accuracy: 0.7228 - val_loss: 0.6350 - val_accuracy: 0.6714 - 96ms/epoch - 1ms/step
## Epoch 121/200
## 84/84 - 0s - loss: 0.5659 - accuracy: 0.7228 - val_loss: 0.6285 - val_accuracy: 0.6667 - 93ms/epoch - 1ms/step
## Epoch 122/200
## 84/84 - 0s - loss: 0.5664 - accuracy: 0.7276 - val_loss: 0.6256 - val_accuracy: 0.6571 - 102ms/epoch - 1ms/step
## Epoch 123/200
## 84/84 - 0s - loss: 0.5667 - accuracy: 0.7192 - val_loss: 0.6222 - val_accuracy: 0.6619 - 93ms/epoch - 1ms/step
## Epoch 124/200
## 84/84 - 0s - loss: 0.5651 - accuracy: 0.7264 - val_loss: 0.6282 - val_accuracy: 0.6714 - 98ms/epoch - 1ms/step
## Epoch 125/200
## 84/84 - 0s - loss: 0.5655 - accuracy: 0.7300 - val_loss: 0.6251 - val_accuracy: 0.6524 - 95ms/epoch - 1ms/step
## Epoch 126/200
## 84/84 - 0s - loss: 0.5664 - accuracy: 0.7180 - val_loss: 0.6254 - val_accuracy: 0.6619 - 96ms/epoch - 1ms/step
## Epoch 127/200
## 84/84 - 0s - loss: 0.5644 - accuracy: 0.7264 - val_loss: 0.6268 - val_accuracy: 0.6571 - 91ms/epoch - 1ms/step
## Epoch 128/200
## 84/84 - 0s - loss: 0.5639 - accuracy: 0.7276 - val_loss: 0.6348 - val_accuracy: 0.6714 - 100ms/epoch - 1ms/step
## Epoch 129/200
## 84/84 - 0s - loss: 0.5659 - accuracy: 0.7228 - val_loss: 0.6311 - val_accuracy: 0.6619 - 102ms/epoch - 1ms/step
## Epoch 130/200
## 84/84 - 0s - loss: 0.5635 - accuracy: 0.7216 - val_loss: 0.6261 - val_accuracy: 0.6524 - 95ms/epoch - 1ms/step
## Epoch 131/200
## 84/84 - 0s - loss: 0.5642 - accuracy: 0.7216 - val_loss: 0.6256 - val_accuracy: 0.6476 - 100ms/epoch - 1ms/step
## Epoch 132/200
## 84/84 - 0s - loss: 0.5639 - accuracy: 0.7240 - val_loss: 0.6299 - val_accuracy: 0.6524 - 95ms/epoch - 1ms/step
## Epoch 133/200
## 84/84 - 0s - loss: 0.5633 - accuracy: 0.7216 - val_loss: 0.6288 - val_accuracy: 0.6524 - 97ms/epoch - 1ms/step
## Epoch 134/200
## 84/84 - 0s - loss: 0.5627 - accuracy: 0.7240 - val_loss: 0.6275 - val_accuracy: 0.6524 - 92ms/epoch - 1ms/step
## Epoch 135/200
## 84/84 - 0s - loss: 0.5635 - accuracy: 0.7216 - val_loss: 0.6268 - val_accuracy: 0.6571 - 98ms/epoch - 1ms/step
## Epoch 136/200
## 84/84 - 0s - loss: 0.5630 - accuracy: 0.7240 - val_loss: 0.6341 - val_accuracy: 0.6714 - 97ms/epoch - 1ms/step
## Epoch 137/200
## 84/84 - 0s - loss: 0.5614 - accuracy: 0.7264 - val_loss: 0.6262 - val_accuracy: 0.6476 - 90ms/epoch - 1ms/step
## Epoch 138/200
## 84/84 - 0s - loss: 0.5633 - accuracy: 0.7252 - val_loss: 0.6267 - val_accuracy: 0.6476 - 97ms/epoch - 1ms/step
## Epoch 139/200
## 84/84 - 0s - loss: 0.5625 - accuracy: 0.7204 - val_loss: 0.6290 - val_accuracy: 0.6476 - 106ms/epoch - 1ms/step
## Epoch 140/200
## 84/84 - 0s - loss: 0.5632 - accuracy: 0.7252 - val_loss: 0.6299 - val_accuracy: 0.6524 - 96ms/epoch - 1ms/step
## Epoch 141/200
## 84/84 - 0s - loss: 0.5633 - accuracy: 0.7240 - val_loss: 0.6331 - val_accuracy: 0.6619 - 92ms/epoch - 1ms/step
## Epoch 142/200
## 84/84 - 0s - loss: 0.5625 - accuracy: 0.7264 - val_loss: 0.6344 - val_accuracy: 0.6667 - 98ms/epoch - 1ms/step
## Epoch 143/200
## 84/84 - 0s - loss: 0.5621 - accuracy: 0.7300 - val_loss: 0.6284 - val_accuracy: 0.6429 - 94ms/epoch - 1ms/step
## Epoch 144/200
## 84/84 - 0s - loss: 0.5615 - accuracy: 0.7216 - val_loss: 0.6342 - val_accuracy: 0.6714 - 94ms/epoch - 1ms/step
## Epoch 145/200
## 84/84 - 0s - loss: 0.5626 - accuracy: 0.7312 - val_loss: 0.6254 - val_accuracy: 0.6524 - 97ms/epoch - 1ms/step
## Epoch 146/200
## 84/84 - 0s - loss: 0.5614 - accuracy: 0.7204 - val_loss: 0.6319 - val_accuracy: 0.6524 - 98ms/epoch - 1ms/step
## Epoch 147/200
## 84/84 - 0s - loss: 0.5614 - accuracy: 0.7228 - val_loss: 0.6282 - val_accuracy: 0.6429 - 99ms/epoch - 1ms/step
## Epoch 148/200
## 84/84 - 0s - loss: 0.5612 - accuracy: 0.7216 - val_loss: 0.6284 - val_accuracy: 0.6429 - 102ms/epoch - 1ms/step
## Epoch 149/200
## 84/84 - 0s - loss: 0.5603 - accuracy: 0.7288 - val_loss: 0.6345 - val_accuracy: 0.6619 - 97ms/epoch - 1ms/step
## Epoch 150/200
## 84/84 - 0s - loss: 0.5609 - accuracy: 0.7264 - val_loss: 0.6342 - val_accuracy: 0.6619 - 92ms/epoch - 1ms/step
## Epoch 151/200
## 84/84 - 0s - loss: 0.5613 - accuracy: 0.7228 - val_loss: 0.6318 - val_accuracy: 0.6571 - 90ms/epoch - 1ms/step
## Epoch 152/200
## 84/84 - 0s - loss: 0.5597 - accuracy: 0.7252 - val_loss: 0.6273 - val_accuracy: 0.6476 - 93ms/epoch - 1ms/step
## Epoch 153/200
## 84/84 - 0s - loss: 0.5601 - accuracy: 0.7252 - val_loss: 0.6360 - val_accuracy: 0.6571 - 93ms/epoch - 1ms/step
## Epoch 154/200
## 84/84 - 0s - loss: 0.5599 - accuracy: 0.7276 - val_loss: 0.6333 - val_accuracy: 0.6476 - 89ms/epoch - 1ms/step
## Epoch 155/200
## 84/84 - 0s - loss: 0.5620 - accuracy: 0.7240 - val_loss: 0.6311 - val_accuracy: 0.6429 - 93ms/epoch - 1ms/step
## Epoch 156/200
## 84/84 - 0s - loss: 0.5597 - accuracy: 0.7288 - val_loss: 0.6305 - val_accuracy: 0.6429 - 100ms/epoch - 1ms/step
## Epoch 157/200
## 84/84 - 0s - loss: 0.5598 - accuracy: 0.7312 - val_loss: 0.6369 - val_accuracy: 0.6524 - 95ms/epoch - 1ms/step
## Epoch 158/200
## 84/84 - 0s - loss: 0.5605 - accuracy: 0.7264 - val_loss: 0.6334 - val_accuracy: 0.6381 - 92ms/epoch - 1ms/step
## Epoch 159/200
## 84/84 - 0s - loss: 0.5590 - accuracy: 0.7228 - val_loss: 0.6313 - val_accuracy: 0.6429 - 97ms/epoch - 1ms/step
## Epoch 160/200
## 84/84 - 0s - loss: 0.5591 - accuracy: 0.7264 - val_loss: 0.6321 - val_accuracy: 0.6429 - 97ms/epoch - 1ms/step
## Epoch 161/200
## 84/84 - 0s - loss: 0.5580 - accuracy: 0.7252 - val_loss: 0.6311 - val_accuracy: 0.6429 - 93ms/epoch - 1ms/step
## Epoch 162/200
## 84/84 - 0s - loss: 0.5598 - accuracy: 0.7288 - val_loss: 0.6321 - val_accuracy: 0.6429 - 95ms/epoch - 1ms/step
## Epoch 163/200
## 84/84 - 0s - loss: 0.5598 - accuracy: 0.7276 - val_loss: 0.6339 - val_accuracy: 0.6381 - 96ms/epoch - 1ms/step
## Epoch 164/200
## 84/84 - 0s - loss: 0.5583 - accuracy: 0.7324 - val_loss: 0.6338 - val_accuracy: 0.6381 - 95ms/epoch - 1ms/step
## Epoch 165/200
## 84/84 - 0s - loss: 0.5586 - accuracy: 0.7252 - val_loss: 0.6347 - val_accuracy: 0.6429 - 91ms/epoch - 1ms/step
## Epoch 166/200
## 84/84 - 0s - loss: 0.5579 - accuracy: 0.7300 - val_loss: 0.6330 - val_accuracy: 0.6476 - 96ms/epoch - 1ms/step
## Epoch 167/200
## 84/84 - 0s - loss: 0.5573 - accuracy: 0.7288 - val_loss: 0.6331 - val_accuracy: 0.6429 - 96ms/epoch - 1ms/step
## Epoch 168/200
## 84/84 - 0s - loss: 0.5588 - accuracy: 0.7276 - val_loss: 0.6365 - val_accuracy: 0.6429 - 95ms/epoch - 1ms/step
## Epoch 169/200
## 84/84 - 0s - loss: 0.5567 - accuracy: 0.7312 - val_loss: 0.6346 - val_accuracy: 0.6381 - 96ms/epoch - 1ms/step
## Epoch 170/200
## 84/84 - 0s - loss: 0.5570 - accuracy: 0.7264 - val_loss: 0.6338 - val_accuracy: 0.6429 - 100ms/epoch - 1ms/step
## Epoch 171/200
## 84/84 - 0s - loss: 0.5569 - accuracy: 0.7300 - val_loss: 0.6309 - val_accuracy: 0.6429 - 129ms/epoch - 2ms/step
## Epoch 172/200
## 84/84 - 0s - loss: 0.5570 - accuracy: 0.7252 - val_loss: 0.6318 - val_accuracy: 0.6381 - 104ms/epoch - 1ms/step
## Epoch 173/200
## 84/84 - 0s - loss: 0.5573 - accuracy: 0.7240 - val_loss: 0.6315 - val_accuracy: 0.6429 - 95ms/epoch - 1ms/step
## Epoch 174/200
## 84/84 - 0s - loss: 0.5557 - accuracy: 0.7324 - val_loss: 0.6401 - val_accuracy: 0.6429 - 96ms/epoch - 1ms/step
## Epoch 175/200
## 84/84 - 0s - loss: 0.5559 - accuracy: 0.7324 - val_loss: 0.6371 - val_accuracy: 0.6429 - 93ms/epoch - 1ms/step
## Epoch 176/200
## 84/84 - 0s - loss: 0.5560 - accuracy: 0.7300 - val_loss: 0.6448 - val_accuracy: 0.6524 - 94ms/epoch - 1ms/step
## Epoch 177/200
## 84/84 - 0s - loss: 0.5564 - accuracy: 0.7312 - val_loss: 0.6324 - val_accuracy: 0.6429 - 94ms/epoch - 1ms/step
## Epoch 178/200
## 84/84 - 0s - loss: 0.5569 - accuracy: 0.7336 - val_loss: 0.6347 - val_accuracy: 0.6429 - 93ms/epoch - 1ms/step
## Epoch 179/200
## 84/84 - 0s - loss: 0.5557 - accuracy: 0.7336 - val_loss: 0.6349 - val_accuracy: 0.6429 - 93ms/epoch - 1ms/step
## Epoch 180/200
## 84/84 - 0s - loss: 0.5567 - accuracy: 0.7300 - val_loss: 0.6361 - val_accuracy: 0.6429 - 97ms/epoch - 1ms/step
## Epoch 181/200
## 84/84 - 0s - loss: 0.5565 - accuracy: 0.7276 - val_loss: 0.6376 - val_accuracy: 0.6429 - 100ms/epoch - 1ms/step
## Epoch 182/200
## 84/84 - 0s - loss: 0.5561 - accuracy: 0.7324 - val_loss: 0.6313 - val_accuracy: 0.6429 - 99ms/epoch - 1ms/step
## Epoch 183/200
## 84/84 - 0s - loss: 0.5554 - accuracy: 0.7288 - val_loss: 0.6343 - val_accuracy: 0.6429 - 92ms/epoch - 1ms/step
## Epoch 184/200
## 84/84 - 0s - loss: 0.5553 - accuracy: 0.7240 - val_loss: 0.6401 - val_accuracy: 0.6429 - 94ms/epoch - 1ms/step
## Epoch 185/200
## 84/84 - 0s - loss: 0.5575 - accuracy: 0.7276 - val_loss: 0.6306 - val_accuracy: 0.6429 - 97ms/epoch - 1ms/step
## Epoch 186/200
## 84/84 - 0s - loss: 0.5559 - accuracy: 0.7312 - val_loss: 0.6344 - val_accuracy: 0.6381 - 97ms/epoch - 1ms/step
## Epoch 187/200
## 84/84 - 0s - loss: 0.5550 - accuracy: 0.7336 - val_loss: 0.6339 - val_accuracy: 0.6381 - 96ms/epoch - 1ms/step
## Epoch 188/200
## 84/84 - 0s - loss: 0.5552 - accuracy: 0.7276 - val_loss: 0.6313 - val_accuracy: 0.6429 - 93ms/epoch - 1ms/step
## Epoch 189/200
## 84/84 - 0s - loss: 0.5544 - accuracy: 0.7336 - val_loss: 0.6328 - val_accuracy: 0.6381 - 126ms/epoch - 2ms/step
## Epoch 190/200
## 84/84 - 0s - loss: 0.5544 - accuracy: 0.7336 - val_loss: 0.6365 - val_accuracy: 0.6381 - 101ms/epoch - 1ms/step
## Epoch 191/200
## 84/84 - 0s - loss: 0.5549 - accuracy: 0.7360 - val_loss: 0.6411 - val_accuracy: 0.6429 - 96ms/epoch - 1ms/step
## Epoch 192/200
## 84/84 - 0s - loss: 0.5527 - accuracy: 0.7324 - val_loss: 0.6342 - val_accuracy: 0.6429 - 95ms/epoch - 1ms/step
## Epoch 193/200
## 84/84 - 0s - loss: 0.5527 - accuracy: 0.7312 - val_loss: 0.6312 - val_accuracy: 0.6429 - 96ms/epoch - 1ms/step
## Epoch 194/200
## 84/84 - 0s - loss: 0.5544 - accuracy: 0.7336 - val_loss: 0.6324 - val_accuracy: 0.6429 - 95ms/epoch - 1ms/step
## Epoch 195/200
## 84/84 - 0s - loss: 0.5514 - accuracy: 0.7348 - val_loss: 0.6455 - val_accuracy: 0.6524 - 98ms/epoch - 1ms/step
## Epoch 196/200
## 84/84 - 0s - loss: 0.5551 - accuracy: 0.7324 - val_loss: 0.6351 - val_accuracy: 0.6381 - 97ms/epoch - 1ms/step
## Epoch 197/200
## 84/84 - 0s - loss: 0.5536 - accuracy: 0.7360 - val_loss: 0.6326 - val_accuracy: 0.6381 - 97ms/epoch - 1ms/step
## Epoch 198/200
## 84/84 - 0s - loss: 0.5525 - accuracy: 0.7348 - val_loss: 0.6339 - val_accuracy: 0.6381 - 95ms/epoch - 1ms/step
## Epoch 199/200
## 84/84 - 0s - loss: 0.5529 - accuracy: 0.7336 - val_loss: 0.6330 - val_accuracy: 0.6381 - 95ms/epoch - 1ms/step
## Epoch 200/200
## 84/84 - 0s - loss: 0.5524 - accuracy: 0.7300 - val_loss: 0.6372 - val_accuracy: 0.6429 - 96ms/epoch - 1ms/step## 9/9 - 0s - loss: 0.5926 - accuracy: 0.7099 - 70ms/epoch - 8ms/step## loss accuracy
## 0.5925683 0.7099237# EDA on the loss and accuracy metrics of this model.2
# Plot the history
# plot(track.model.2)
#
# # NN model loss on the training data
# plot(track.model.2$metrics$loss, main="Model Loss",
# xlab = "Epoch", ylab="Loss", col="green", type="l", ylim=c(0.54, 0.6))
#
# # NN model loss of the 20% validation data
# lines(track.model.2$metrics$val_loss, col="blue", type="l")
#
# # Add legend
# legend("right", c("Training", "Testing"), col=c("green", "blue"), lty=c(1,1))
#
# # Plot the accuracy of the training data
# plot(track.model.2$metrics$acc, main="Model 2 (Extra Layer) Accuracy",
# xlab = "Epoch", ylab="Accuracy", col="blue", type="l", ylim=c(0.65, 0.76))
#
# # Plot the accuracy of the validation data
# lines(track.model.2$metrics$val_acc, col="green")
#
# # Add Legend
# legend("top", c("Training", "Testing"), col=c("blue", "green"), lty=c(1,1))
## plot_ly
epochs <- 200
time <- 1:epochs
hist_df2 <- data.frame(time=time, loss=track.model.2$metrics$loss, acc=track.model.2$metrics$acc,
valid_loss=track.model.2$metrics$val_loss, valid_acc=track.model.2$metrics$val_acc)
plot_ly(hist_df2, x = ~time) %>%
add_trace(y = ~loss, name = 'training loss', mode = 'lines') %>%
add_trace(y = ~acc, name = 'training accuracy', mode = 'lines+markers') %>%
add_trace(y = ~valid_loss, name = 'validation loss',mode = 'lines+markers') %>%
add_trace(y = ~valid_acc, name = 'validation accuracy', mode = 'lines+markers') %>%
layout(title="Titanic (model.2) Model Performance",
legend = list(orientation = 'h'), yaxis=list(title="metric"))Next we can examine the effects of adding more hidden units to the NN model.
# Initialize a sequential model
model.3 <- keras_model_sequential()
# Add layers and Node-Units to model
model.3 %>%
layer_dense(units = 30, activation = 'relu', input_shape = c(4)) %>%
layer_dense(units = 15, activation = 'relu') %>%
layer_dense(units = 2, activation = 'softmax')
# Compile the model
model.3 %>% compile(
loss = 'binary_crossentropy',
optimizer = 'adam',
metrics = 'accuracy'
)
# Fit NN model to training data & Save the training history
track.model.3 <- model.3 %>% fit(
train_dat2.X,
train_dat2.Y,
epochs = 200,
batch_size = 10,
validation_split = 0.2
)## Epoch 1/200
## 84/84 - 1s - loss: 0.6671 - accuracy: 0.6057 - val_loss: 0.6477 - val_accuracy: 0.6619 - 525ms/epoch - 6ms/step
## Epoch 2/200
## 84/84 - 0s - loss: 0.6203 - accuracy: 0.6714 - val_loss: 0.6319 - val_accuracy: 0.6667 - 105ms/epoch - 1ms/step
## Epoch 3/200
## 84/84 - 0s - loss: 0.6047 - accuracy: 0.6882 - val_loss: 0.6297 - val_accuracy: 0.6667 - 101ms/epoch - 1ms/step
## Epoch 4/200
## 84/84 - 0s - loss: 0.5981 - accuracy: 0.6858 - val_loss: 0.6257 - val_accuracy: 0.6714 - 101ms/epoch - 1ms/step
## Epoch 5/200
## 84/84 - 0s - loss: 0.5944 - accuracy: 0.6858 - val_loss: 0.6256 - val_accuracy: 0.6714 - 101ms/epoch - 1ms/step
## Epoch 6/200
## 84/84 - 0s - loss: 0.5927 - accuracy: 0.6858 - val_loss: 0.6207 - val_accuracy: 0.6571 - 102ms/epoch - 1ms/step
## Epoch 7/200
## 84/84 - 0s - loss: 0.5916 - accuracy: 0.6882 - val_loss: 0.6188 - val_accuracy: 0.6619 - 104ms/epoch - 1ms/step
## Epoch 8/200
## 84/84 - 0s - loss: 0.5901 - accuracy: 0.6846 - val_loss: 0.6252 - val_accuracy: 0.6810 - 102ms/epoch - 1ms/step
## Epoch 9/200
## 84/84 - 0s - loss: 0.5873 - accuracy: 0.6882 - val_loss: 0.6228 - val_accuracy: 0.6857 - 104ms/epoch - 1ms/step
## Epoch 10/200
## 84/84 - 0s - loss: 0.5855 - accuracy: 0.6965 - val_loss: 0.6204 - val_accuracy: 0.6714 - 107ms/epoch - 1ms/step
## Epoch 11/200
## 84/84 - 0s - loss: 0.5833 - accuracy: 0.7013 - val_loss: 0.6293 - val_accuracy: 0.6905 - 103ms/epoch - 1ms/step
## Epoch 12/200
## 84/84 - 0s - loss: 0.5837 - accuracy: 0.7049 - val_loss: 0.6199 - val_accuracy: 0.6762 - 103ms/epoch - 1ms/step
## Epoch 13/200
## 84/84 - 0s - loss: 0.5864 - accuracy: 0.7192 - val_loss: 0.6196 - val_accuracy: 0.6667 - 108ms/epoch - 1ms/step
## Epoch 14/200
## 84/84 - 0s - loss: 0.5784 - accuracy: 0.7073 - val_loss: 0.6245 - val_accuracy: 0.6905 - 103ms/epoch - 1ms/step
## Epoch 15/200
## 84/84 - 0s - loss: 0.5783 - accuracy: 0.7168 - val_loss: 0.6227 - val_accuracy: 0.6762 - 104ms/epoch - 1ms/step
## Epoch 16/200
## 84/84 - 0s - loss: 0.5755 - accuracy: 0.7288 - val_loss: 0.6158 - val_accuracy: 0.6619 - 104ms/epoch - 1ms/step
## Epoch 17/200
## 84/84 - 0s - loss: 0.5726 - accuracy: 0.7276 - val_loss: 0.6363 - val_accuracy: 0.6952 - 101ms/epoch - 1ms/step
## Epoch 18/200
## 84/84 - 0s - loss: 0.5736 - accuracy: 0.7192 - val_loss: 0.6210 - val_accuracy: 0.6667 - 101ms/epoch - 1ms/step
## Epoch 19/200
## 84/84 - 0s - loss: 0.5714 - accuracy: 0.7216 - val_loss: 0.6301 - val_accuracy: 0.6905 - 102ms/epoch - 1ms/step
## Epoch 20/200
## 84/84 - 0s - loss: 0.5701 - accuracy: 0.7180 - val_loss: 0.6184 - val_accuracy: 0.6714 - 104ms/epoch - 1ms/step
## Epoch 21/200
## 84/84 - 0s - loss: 0.5698 - accuracy: 0.7133 - val_loss: 0.6233 - val_accuracy: 0.6619 - 101ms/epoch - 1ms/step
## Epoch 22/200
## 84/84 - 0s - loss: 0.5685 - accuracy: 0.7276 - val_loss: 0.6226 - val_accuracy: 0.6619 - 103ms/epoch - 1ms/step
## Epoch 23/200
## 84/84 - 0s - loss: 0.5690 - accuracy: 0.7240 - val_loss: 0.6211 - val_accuracy: 0.6619 - 102ms/epoch - 1ms/step
## Epoch 24/200
## 84/84 - 0s - loss: 0.5668 - accuracy: 0.7216 - val_loss: 0.6261 - val_accuracy: 0.6762 - 101ms/epoch - 1ms/step
## Epoch 25/200
## 84/84 - 0s - loss: 0.5655 - accuracy: 0.7180 - val_loss: 0.6342 - val_accuracy: 0.6714 - 100ms/epoch - 1ms/step
## Epoch 26/200
## 84/84 - 0s - loss: 0.5636 - accuracy: 0.7300 - val_loss: 0.6225 - val_accuracy: 0.6619 - 102ms/epoch - 1ms/step
## Epoch 27/200
## 84/84 - 0s - loss: 0.5627 - accuracy: 0.7252 - val_loss: 0.6255 - val_accuracy: 0.6714 - 104ms/epoch - 1ms/step
## Epoch 28/200
## 84/84 - 0s - loss: 0.5630 - accuracy: 0.7180 - val_loss: 0.6230 - val_accuracy: 0.6619 - 102ms/epoch - 1ms/step
## Epoch 29/200
## 84/84 - 0s - loss: 0.5604 - accuracy: 0.7360 - val_loss: 0.6228 - val_accuracy: 0.6714 - 101ms/epoch - 1ms/step
## Epoch 30/200
## 84/84 - 0s - loss: 0.5585 - accuracy: 0.7252 - val_loss: 0.6352 - val_accuracy: 0.6524 - 107ms/epoch - 1ms/step
## Epoch 31/200
## 84/84 - 0s - loss: 0.5588 - accuracy: 0.7348 - val_loss: 0.6242 - val_accuracy: 0.6667 - 103ms/epoch - 1ms/step
## Epoch 32/200
## 84/84 - 0s - loss: 0.5599 - accuracy: 0.7180 - val_loss: 0.6265 - val_accuracy: 0.6667 - 104ms/epoch - 1ms/step
## Epoch 33/200
## 84/84 - 0s - loss: 0.5575 - accuracy: 0.7240 - val_loss: 0.6268 - val_accuracy: 0.6524 - 103ms/epoch - 1ms/step
## Epoch 34/200
## 84/84 - 0s - loss: 0.5567 - accuracy: 0.7264 - val_loss: 0.6390 - val_accuracy: 0.6571 - 105ms/epoch - 1ms/step
## Epoch 35/200
## 84/84 - 0s - loss: 0.5569 - accuracy: 0.7312 - val_loss: 0.6286 - val_accuracy: 0.6619 - 101ms/epoch - 1ms/step
## Epoch 36/200
## 84/84 - 0s - loss: 0.5560 - accuracy: 0.7288 - val_loss: 0.6304 - val_accuracy: 0.6571 - 102ms/epoch - 1ms/step
## Epoch 37/200
## 84/84 - 0s - loss: 0.5562 - accuracy: 0.7276 - val_loss: 0.6321 - val_accuracy: 0.6524 - 100ms/epoch - 1ms/step
## Epoch 38/200
## 84/84 - 0s - loss: 0.5543 - accuracy: 0.7312 - val_loss: 0.6300 - val_accuracy: 0.6476 - 101ms/epoch - 1ms/step
## Epoch 39/200
## 84/84 - 0s - loss: 0.5546 - accuracy: 0.7300 - val_loss: 0.6348 - val_accuracy: 0.6524 - 107ms/epoch - 1ms/step
## Epoch 40/200
## 84/84 - 0s - loss: 0.5564 - accuracy: 0.7336 - val_loss: 0.6365 - val_accuracy: 0.6524 - 105ms/epoch - 1ms/step
## Epoch 41/200
## 84/84 - 0s - loss: 0.5540 - accuracy: 0.7312 - val_loss: 0.6389 - val_accuracy: 0.6476 - 101ms/epoch - 1ms/step
## Epoch 42/200
## 84/84 - 0s - loss: 0.5524 - accuracy: 0.7288 - val_loss: 0.6354 - val_accuracy: 0.6524 - 102ms/epoch - 1ms/step
## Epoch 43/200
## 84/84 - 0s - loss: 0.5519 - accuracy: 0.7288 - val_loss: 0.6328 - val_accuracy: 0.6381 - 104ms/epoch - 1ms/step
## Epoch 44/200
## 84/84 - 0s - loss: 0.5501 - accuracy: 0.7360 - val_loss: 0.6539 - val_accuracy: 0.6476 - 101ms/epoch - 1ms/step
## Epoch 45/200
## 84/84 - 0s - loss: 0.5516 - accuracy: 0.7288 - val_loss: 0.6400 - val_accuracy: 0.6476 - 102ms/epoch - 1ms/step
## Epoch 46/200
## 84/84 - 0s - loss: 0.5504 - accuracy: 0.7360 - val_loss: 0.6340 - val_accuracy: 0.6381 - 103ms/epoch - 1ms/step
## Epoch 47/200
## 84/84 - 0s - loss: 0.5505 - accuracy: 0.7324 - val_loss: 0.6471 - val_accuracy: 0.6476 - 104ms/epoch - 1ms/step
## Epoch 48/200
## 84/84 - 0s - loss: 0.5524 - accuracy: 0.7324 - val_loss: 0.6390 - val_accuracy: 0.6476 - 107ms/epoch - 1ms/step
## Epoch 49/200
## 84/84 - 0s - loss: 0.5532 - accuracy: 0.7288 - val_loss: 0.6561 - val_accuracy: 0.6476 - 101ms/epoch - 1ms/step
## Epoch 50/200
## 84/84 - 0s - loss: 0.5488 - accuracy: 0.7264 - val_loss: 0.6452 - val_accuracy: 0.6381 - 105ms/epoch - 1ms/step
## Epoch 51/200
## 84/84 - 0s - loss: 0.5482 - accuracy: 0.7288 - val_loss: 0.6420 - val_accuracy: 0.6381 - 104ms/epoch - 1ms/step
## Epoch 52/200
## 84/84 - 0s - loss: 0.5475 - accuracy: 0.7288 - val_loss: 0.6400 - val_accuracy: 0.6333 - 110ms/epoch - 1ms/step
## Epoch 53/200
## 84/84 - 0s - loss: 0.5488 - accuracy: 0.7288 - val_loss: 0.6464 - val_accuracy: 0.6429 - 108ms/epoch - 1ms/step
## Epoch 54/200
## 84/84 - 0s - loss: 0.5491 - accuracy: 0.7264 - val_loss: 0.6504 - val_accuracy: 0.6429 - 106ms/epoch - 1ms/step
## Epoch 55/200
## 84/84 - 0s - loss: 0.5470 - accuracy: 0.7336 - val_loss: 0.6466 - val_accuracy: 0.6429 - 102ms/epoch - 1ms/step
## Epoch 56/200
## 84/84 - 0s - loss: 0.5474 - accuracy: 0.7360 - val_loss: 0.6586 - val_accuracy: 0.6381 - 102ms/epoch - 1ms/step
## Epoch 57/200
## 84/84 - 0s - loss: 0.5475 - accuracy: 0.7336 - val_loss: 0.6429 - val_accuracy: 0.6333 - 104ms/epoch - 1ms/step
## Epoch 58/200
## 84/84 - 0s - loss: 0.5464 - accuracy: 0.7312 - val_loss: 0.6396 - val_accuracy: 0.6333 - 104ms/epoch - 1ms/step
## Epoch 59/200
## 84/84 - 0s - loss: 0.5464 - accuracy: 0.7300 - val_loss: 0.6410 - val_accuracy: 0.6286 - 101ms/epoch - 1ms/step
## Epoch 60/200
## 84/84 - 0s - loss: 0.5461 - accuracy: 0.7276 - val_loss: 0.6473 - val_accuracy: 0.6381 - 104ms/epoch - 1ms/step
## Epoch 61/200
## 84/84 - 0s - loss: 0.5470 - accuracy: 0.7360 - val_loss: 0.6461 - val_accuracy: 0.6381 - 102ms/epoch - 1ms/step
## Epoch 62/200
## 84/84 - 0s - loss: 0.5445 - accuracy: 0.7360 - val_loss: 0.6465 - val_accuracy: 0.6381 - 105ms/epoch - 1ms/step
## Epoch 63/200
## 84/84 - 0s - loss: 0.5446 - accuracy: 0.7276 - val_loss: 0.6475 - val_accuracy: 0.6381 - 102ms/epoch - 1ms/step
## Epoch 64/200
## 84/84 - 0s - loss: 0.5447 - accuracy: 0.7276 - val_loss: 0.6458 - val_accuracy: 0.6381 - 107ms/epoch - 1ms/step
## Epoch 65/200
## 84/84 - 0s - loss: 0.5460 - accuracy: 0.7324 - val_loss: 0.6452 - val_accuracy: 0.6333 - 110ms/epoch - 1ms/step
## Epoch 66/200
## 84/84 - 0s - loss: 0.5450 - accuracy: 0.7360 - val_loss: 0.6480 - val_accuracy: 0.6333 - 105ms/epoch - 1ms/step
## Epoch 67/200
## 84/84 - 0s - loss: 0.5431 - accuracy: 0.7336 - val_loss: 0.6666 - val_accuracy: 0.6381 - 105ms/epoch - 1ms/step
## Epoch 68/200
## 84/84 - 0s - loss: 0.5450 - accuracy: 0.7312 - val_loss: 0.6572 - val_accuracy: 0.6429 - 104ms/epoch - 1ms/step
## Epoch 69/200
## 84/84 - 0s - loss: 0.5415 - accuracy: 0.7431 - val_loss: 0.6521 - val_accuracy: 0.6381 - 109ms/epoch - 1ms/step
## Epoch 70/200
## 84/84 - 0s - loss: 0.5437 - accuracy: 0.7312 - val_loss: 0.6560 - val_accuracy: 0.6429 - 104ms/epoch - 1ms/step
## Epoch 71/200
## 84/84 - 0s - loss: 0.5417 - accuracy: 0.7312 - val_loss: 0.6592 - val_accuracy: 0.6333 - 104ms/epoch - 1ms/step
## Epoch 72/200
## 84/84 - 0s - loss: 0.5435 - accuracy: 0.7348 - val_loss: 0.6501 - val_accuracy: 0.6286 - 107ms/epoch - 1ms/step
## Epoch 73/200
## 84/84 - 0s - loss: 0.5426 - accuracy: 0.7384 - val_loss: 0.6503 - val_accuracy: 0.6333 - 104ms/epoch - 1ms/step
## Epoch 74/200
## 84/84 - 0s - loss: 0.5423 - accuracy: 0.7360 - val_loss: 0.6513 - val_accuracy: 0.6381 - 105ms/epoch - 1ms/step
## Epoch 75/200
## 84/84 - 0s - loss: 0.5419 - accuracy: 0.7276 - val_loss: 0.6529 - val_accuracy: 0.6333 - 106ms/epoch - 1ms/step
## Epoch 76/200
## 84/84 - 0s - loss: 0.5420 - accuracy: 0.7300 - val_loss: 0.6484 - val_accuracy: 0.6333 - 106ms/epoch - 1ms/step
## Epoch 77/200
## 84/84 - 0s - loss: 0.5408 - accuracy: 0.7336 - val_loss: 0.6483 - val_accuracy: 0.6381 - 106ms/epoch - 1ms/step
## Epoch 78/200
## 84/84 - 0s - loss: 0.5451 - accuracy: 0.7372 - val_loss: 0.6530 - val_accuracy: 0.6381 - 104ms/epoch - 1ms/step
## Epoch 79/200
## 84/84 - 0s - loss: 0.5414 - accuracy: 0.7372 - val_loss: 0.6574 - val_accuracy: 0.6381 - 109ms/epoch - 1ms/step
## Epoch 80/200
## 84/84 - 0s - loss: 0.5429 - accuracy: 0.7288 - val_loss: 0.6517 - val_accuracy: 0.6333 - 103ms/epoch - 1ms/step
## Epoch 81/200
## 84/84 - 0s - loss: 0.5419 - accuracy: 0.7360 - val_loss: 0.6572 - val_accuracy: 0.6333 - 103ms/epoch - 1ms/step
## Epoch 82/200
## 84/84 - 0s - loss: 0.5412 - accuracy: 0.7360 - val_loss: 0.6545 - val_accuracy: 0.6381 - 109ms/epoch - 1ms/step
## Epoch 83/200
## 84/84 - 0s - loss: 0.5399 - accuracy: 0.7372 - val_loss: 0.6653 - val_accuracy: 0.6381 - 103ms/epoch - 1ms/step
## Epoch 84/200
## 84/84 - 0s - loss: 0.5411 - accuracy: 0.7384 - val_loss: 0.6505 - val_accuracy: 0.6381 - 103ms/epoch - 1ms/step
## Epoch 85/200
## 84/84 - 0s - loss: 0.5399 - accuracy: 0.7360 - val_loss: 0.6588 - val_accuracy: 0.6381 - 105ms/epoch - 1ms/step
## Epoch 86/200
## 84/84 - 0s - loss: 0.5399 - accuracy: 0.7384 - val_loss: 0.6563 - val_accuracy: 0.6381 - 103ms/epoch - 1ms/step
## Epoch 87/200
## 84/84 - 0s - loss: 0.5405 - accuracy: 0.7312 - val_loss: 0.6532 - val_accuracy: 0.6381 - 101ms/epoch - 1ms/step
## Epoch 88/200
## 84/84 - 0s - loss: 0.5405 - accuracy: 0.7336 - val_loss: 0.6564 - val_accuracy: 0.6381 - 103ms/epoch - 1ms/step
## Epoch 89/200
## 84/84 - 0s - loss: 0.5388 - accuracy: 0.7372 - val_loss: 0.6579 - val_accuracy: 0.6381 - 105ms/epoch - 1ms/step
## Epoch 90/200
## 84/84 - 0s - loss: 0.5394 - accuracy: 0.7372 - val_loss: 0.6584 - val_accuracy: 0.6333 - 101ms/epoch - 1ms/step
## Epoch 91/200
## 84/84 - 0s - loss: 0.5410 - accuracy: 0.7336 - val_loss: 0.6570 - val_accuracy: 0.6333 - 100ms/epoch - 1ms/step
## Epoch 92/200
## 84/84 - 0s - loss: 0.5408 - accuracy: 0.7324 - val_loss: 0.6535 - val_accuracy: 0.6381 - 101ms/epoch - 1ms/step
## Epoch 93/200
## 84/84 - 0s - loss: 0.5396 - accuracy: 0.7360 - val_loss: 0.6557 - val_accuracy: 0.6381 - 103ms/epoch - 1ms/step
## Epoch 94/200
## 84/84 - 0s - loss: 0.5362 - accuracy: 0.7348 - val_loss: 0.6697 - val_accuracy: 0.6381 - 101ms/epoch - 1ms/step
## Epoch 95/200
## 84/84 - 0s - loss: 0.5393 - accuracy: 0.7384 - val_loss: 0.6549 - val_accuracy: 0.6381 - 104ms/epoch - 1ms/step
## Epoch 96/200
## 84/84 - 0s - loss: 0.5392 - accuracy: 0.7407 - val_loss: 0.6608 - val_accuracy: 0.6381 - 103ms/epoch - 1ms/step
## Epoch 97/200
## 84/84 - 0s - loss: 0.5380 - accuracy: 0.7336 - val_loss: 0.6635 - val_accuracy: 0.6333 - 106ms/epoch - 1ms/step
## Epoch 98/200
## 84/84 - 0s - loss: 0.5372 - accuracy: 0.7407 - val_loss: 0.6605 - val_accuracy: 0.6333 - 104ms/epoch - 1ms/step
## Epoch 99/200
## 84/84 - 0s - loss: 0.5388 - accuracy: 0.7407 - val_loss: 0.6558 - val_accuracy: 0.6381 - 103ms/epoch - 1ms/step
## Epoch 100/200
## 84/84 - 0s - loss: 0.5373 - accuracy: 0.7372 - val_loss: 0.6560 - val_accuracy: 0.6381 - 108ms/epoch - 1ms/step
## Epoch 101/200
## 84/84 - 0s - loss: 0.5383 - accuracy: 0.7372 - val_loss: 0.6578 - val_accuracy: 0.6381 - 100ms/epoch - 1ms/step
## Epoch 102/200
## 84/84 - 0s - loss: 0.5373 - accuracy: 0.7419 - val_loss: 0.6557 - val_accuracy: 0.6381 - 104ms/epoch - 1ms/step
## Epoch 103/200
## 84/84 - 0s - loss: 0.5373 - accuracy: 0.7360 - val_loss: 0.6638 - val_accuracy: 0.6286 - 104ms/epoch - 1ms/step
## Epoch 104/200
## 84/84 - 0s - loss: 0.5387 - accuracy: 0.7348 - val_loss: 0.6629 - val_accuracy: 0.6333 - 101ms/epoch - 1ms/step
## Epoch 105/200
## 84/84 - 0s - loss: 0.5390 - accuracy: 0.7395 - val_loss: 0.6654 - val_accuracy: 0.6333 - 101ms/epoch - 1ms/step
## Epoch 106/200
## 84/84 - 0s - loss: 0.5367 - accuracy: 0.7348 - val_loss: 0.6613 - val_accuracy: 0.6286 - 101ms/epoch - 1ms/step
## Epoch 107/200
## 84/84 - 0s - loss: 0.5367 - accuracy: 0.7348 - val_loss: 0.6600 - val_accuracy: 0.6381 - 100ms/epoch - 1ms/step
## Epoch 108/200
## 84/84 - 0s - loss: 0.5362 - accuracy: 0.7360 - val_loss: 0.6654 - val_accuracy: 0.6333 - 104ms/epoch - 1ms/step
## Epoch 109/200
## 84/84 - 0s - loss: 0.5383 - accuracy: 0.7348 - val_loss: 0.6607 - val_accuracy: 0.6381 - 102ms/epoch - 1ms/step
## Epoch 110/200
## 84/84 - 0s - loss: 0.5354 - accuracy: 0.7372 - val_loss: 0.6589 - val_accuracy: 0.6381 - 103ms/epoch - 1ms/step
## Epoch 111/200
## 84/84 - 0s - loss: 0.5398 - accuracy: 0.7395 - val_loss: 0.6631 - val_accuracy: 0.6286 - 103ms/epoch - 1ms/step
## Epoch 112/200
## 84/84 - 0s - loss: 0.5363 - accuracy: 0.7360 - val_loss: 0.6657 - val_accuracy: 0.6333 - 101ms/epoch - 1ms/step
## Epoch 113/200
## 84/84 - 0s - loss: 0.5347 - accuracy: 0.7324 - val_loss: 0.6669 - val_accuracy: 0.6333 - 100ms/epoch - 1ms/step
## Epoch 114/200
## 84/84 - 0s - loss: 0.5361 - accuracy: 0.7348 - val_loss: 0.6659 - val_accuracy: 0.6333 - 100ms/epoch - 1ms/step
## Epoch 115/200
## 84/84 - 0s - loss: 0.5362 - accuracy: 0.7336 - val_loss: 0.6620 - val_accuracy: 0.6381 - 102ms/epoch - 1ms/step
## Epoch 116/200
## 84/84 - 0s - loss: 0.5381 - accuracy: 0.7384 - val_loss: 0.6612 - val_accuracy: 0.6333 - 101ms/epoch - 1ms/step
## Epoch 117/200
## 84/84 - 0s - loss: 0.5370 - accuracy: 0.7348 - val_loss: 0.6650 - val_accuracy: 0.6333 - 108ms/epoch - 1ms/step
## Epoch 118/200
## 84/84 - 0s - loss: 0.5372 - accuracy: 0.7407 - val_loss: 0.6630 - val_accuracy: 0.6333 - 107ms/epoch - 1ms/step
## Epoch 119/200
## 84/84 - 0s - loss: 0.5355 - accuracy: 0.7372 - val_loss: 0.6745 - val_accuracy: 0.6333 - 103ms/epoch - 1ms/step
## Epoch 120/200
## 84/84 - 0s - loss: 0.5367 - accuracy: 0.7407 - val_loss: 0.6695 - val_accuracy: 0.6333 - 105ms/epoch - 1ms/step
## Epoch 121/200
## 84/84 - 0s - loss: 0.5366 - accuracy: 0.7407 - val_loss: 0.6648 - val_accuracy: 0.6286 - 104ms/epoch - 1ms/step
## Epoch 122/200
## 84/84 - 0s - loss: 0.5369 - accuracy: 0.7384 - val_loss: 0.6616 - val_accuracy: 0.6381 - 102ms/epoch - 1ms/step
## Epoch 123/200
## 84/84 - 0s - loss: 0.5375 - accuracy: 0.7372 - val_loss: 0.6647 - val_accuracy: 0.6286 - 103ms/epoch - 1ms/step
## Epoch 124/200
## 84/84 - 0s - loss: 0.5382 - accuracy: 0.7372 - val_loss: 0.6623 - val_accuracy: 0.6333 - 102ms/epoch - 1ms/step
## Epoch 125/200
## 84/84 - 0s - loss: 0.5357 - accuracy: 0.7360 - val_loss: 0.6621 - val_accuracy: 0.6381 - 102ms/epoch - 1ms/step
## Epoch 126/200
## 84/84 - 0s - loss: 0.5362 - accuracy: 0.7336 - val_loss: 0.6615 - val_accuracy: 0.6333 - 105ms/epoch - 1ms/step
## Epoch 127/200
## 84/84 - 0s - loss: 0.5359 - accuracy: 0.7407 - val_loss: 0.6640 - val_accuracy: 0.6333 - 104ms/epoch - 1ms/step
## Epoch 128/200
## 84/84 - 0s - loss: 0.5357 - accuracy: 0.7419 - val_loss: 0.6632 - val_accuracy: 0.6381 - 106ms/epoch - 1ms/step
## Epoch 129/200
## 84/84 - 0s - loss: 0.5347 - accuracy: 0.7324 - val_loss: 0.6644 - val_accuracy: 0.6333 - 103ms/epoch - 1ms/step
## Epoch 130/200
## 84/84 - 0s - loss: 0.5354 - accuracy: 0.7348 - val_loss: 0.6697 - val_accuracy: 0.6333 - 102ms/epoch - 1ms/step
## Epoch 131/200
## 84/84 - 0s - loss: 0.5365 - accuracy: 0.7360 - val_loss: 0.6754 - val_accuracy: 0.6381 - 100ms/epoch - 1ms/step
## Epoch 132/200
## 84/84 - 0s - loss: 0.5344 - accuracy: 0.7372 - val_loss: 0.6620 - val_accuracy: 0.6381 - 103ms/epoch - 1ms/step
## Epoch 133/200
## 84/84 - 0s - loss: 0.5375 - accuracy: 0.7324 - val_loss: 0.6646 - val_accuracy: 0.6333 - 103ms/epoch - 1ms/step
## Epoch 134/200
## 84/84 - 0s - loss: 0.5364 - accuracy: 0.7324 - val_loss: 0.6671 - val_accuracy: 0.6286 - 108ms/epoch - 1ms/step
## Epoch 135/200
## 84/84 - 0s - loss: 0.5359 - accuracy: 0.7348 - val_loss: 0.6639 - val_accuracy: 0.6333 - 101ms/epoch - 1ms/step
## Epoch 136/200
## 84/84 - 0s - loss: 0.5340 - accuracy: 0.7407 - val_loss: 0.6699 - val_accuracy: 0.6333 - 102ms/epoch - 1ms/step
## Epoch 137/200
## 84/84 - 0s - loss: 0.5342 - accuracy: 0.7348 - val_loss: 0.6733 - val_accuracy: 0.6381 - 101ms/epoch - 1ms/step
## Epoch 138/200
## 84/84 - 0s - loss: 0.5365 - accuracy: 0.7419 - val_loss: 0.6805 - val_accuracy: 0.6429 - 107ms/epoch - 1ms/step
## Epoch 139/200
## 84/84 - 0s - loss: 0.5355 - accuracy: 0.7372 - val_loss: 0.6698 - val_accuracy: 0.6286 - 101ms/epoch - 1ms/step
## Epoch 140/200
## 84/84 - 0s - loss: 0.5343 - accuracy: 0.7395 - val_loss: 0.6679 - val_accuracy: 0.6333 - 101ms/epoch - 1ms/step
## Epoch 141/200
## 84/84 - 0s - loss: 0.5358 - accuracy: 0.7348 - val_loss: 0.6646 - val_accuracy: 0.6333 - 100ms/epoch - 1ms/step
## Epoch 142/200
## 84/84 - 0s - loss: 0.5355 - accuracy: 0.7372 - val_loss: 0.6656 - val_accuracy: 0.6333 - 101ms/epoch - 1ms/step
## Epoch 143/200
## 84/84 - 0s - loss: 0.5351 - accuracy: 0.7407 - val_loss: 0.6661 - val_accuracy: 0.6333 - 100ms/epoch - 1ms/step
## Epoch 144/200
## 84/84 - 0s - loss: 0.5333 - accuracy: 0.7384 - val_loss: 0.6749 - val_accuracy: 0.6381 - 114ms/epoch - 1ms/step
## Epoch 145/200
## 84/84 - 0s - loss: 0.5363 - accuracy: 0.7419 - val_loss: 0.6799 - val_accuracy: 0.6381 - 140ms/epoch - 2ms/step
## Epoch 146/200
## 84/84 - 0s - loss: 0.5341 - accuracy: 0.7443 - val_loss: 0.6696 - val_accuracy: 0.6333 - 138ms/epoch - 2ms/step
## Epoch 147/200
## 84/84 - 0s - loss: 0.5345 - accuracy: 0.7336 - val_loss: 0.6658 - val_accuracy: 0.6333 - 140ms/epoch - 2ms/step
## Epoch 148/200
## 84/84 - 0s - loss: 0.5340 - accuracy: 0.7395 - val_loss: 0.6657 - val_accuracy: 0.6333 - 141ms/epoch - 2ms/step
## Epoch 149/200
## 84/84 - 0s - loss: 0.5366 - accuracy: 0.7384 - val_loss: 0.6652 - val_accuracy: 0.6381 - 139ms/epoch - 2ms/step
## Epoch 150/200
## 84/84 - 0s - loss: 0.5339 - accuracy: 0.7372 - val_loss: 0.6652 - val_accuracy: 0.6381 - 140ms/epoch - 2ms/step
## Epoch 151/200
## 84/84 - 0s - loss: 0.5364 - accuracy: 0.7395 - val_loss: 0.6708 - val_accuracy: 0.6333 - 175ms/epoch - 2ms/step
## Epoch 152/200
## 84/84 - 0s - loss: 0.5354 - accuracy: 0.7419 - val_loss: 0.6679 - val_accuracy: 0.6333 - 138ms/epoch - 2ms/step
## Epoch 153/200
## 84/84 - 0s - loss: 0.5332 - accuracy: 0.7395 - val_loss: 0.6616 - val_accuracy: 0.6381 - 137ms/epoch - 2ms/step
## Epoch 154/200
## 84/84 - 0s - loss: 0.5347 - accuracy: 0.7384 - val_loss: 0.6691 - val_accuracy: 0.6333 - 140ms/epoch - 2ms/step
## Epoch 155/200
## 84/84 - 0s - loss: 0.5343 - accuracy: 0.7395 - val_loss: 0.6674 - val_accuracy: 0.6333 - 136ms/epoch - 2ms/step
## Epoch 156/200
## 84/84 - 0s - loss: 0.5340 - accuracy: 0.7395 - val_loss: 0.6667 - val_accuracy: 0.6333 - 134ms/epoch - 2ms/step
## Epoch 157/200
## 84/84 - 0s - loss: 0.5346 - accuracy: 0.7360 - val_loss: 0.6703 - val_accuracy: 0.6333 - 135ms/epoch - 2ms/step
## Epoch 158/200
## 84/84 - 0s - loss: 0.5331 - accuracy: 0.7372 - val_loss: 0.6689 - val_accuracy: 0.6381 - 136ms/epoch - 2ms/step
## Epoch 159/200
## 84/84 - 0s - loss: 0.5348 - accuracy: 0.7384 - val_loss: 0.6671 - val_accuracy: 0.6381 - 138ms/epoch - 2ms/step
## Epoch 160/200
## 84/84 - 0s - loss: 0.5338 - accuracy: 0.7348 - val_loss: 0.6633 - val_accuracy: 0.6381 - 137ms/epoch - 2ms/step
## Epoch 161/200
## 84/84 - 0s - loss: 0.5346 - accuracy: 0.7407 - val_loss: 0.6648 - val_accuracy: 0.6381 - 137ms/epoch - 2ms/step
## Epoch 162/200
## 84/84 - 0s - loss: 0.5364 - accuracy: 0.7395 - val_loss: 0.6667 - val_accuracy: 0.6381 - 140ms/epoch - 2ms/step
## Epoch 163/200
## 84/84 - 0s - loss: 0.5347 - accuracy: 0.7395 - val_loss: 0.6682 - val_accuracy: 0.6381 - 134ms/epoch - 2ms/step
## Epoch 164/200
## 84/84 - 0s - loss: 0.5330 - accuracy: 0.7384 - val_loss: 0.6764 - val_accuracy: 0.6381 - 135ms/epoch - 2ms/step
## Epoch 165/200
## 84/84 - 0s - loss: 0.5343 - accuracy: 0.7360 - val_loss: 0.6678 - val_accuracy: 0.6381 - 138ms/epoch - 2ms/step
## Epoch 166/200
## 84/84 - 0s - loss: 0.5332 - accuracy: 0.7419 - val_loss: 0.6722 - val_accuracy: 0.6333 - 136ms/epoch - 2ms/step
## Epoch 167/200
## 84/84 - 0s - loss: 0.5331 - accuracy: 0.7419 - val_loss: 0.6680 - val_accuracy: 0.6333 - 136ms/epoch - 2ms/step
## Epoch 168/200
## 84/84 - 0s - loss: 0.5340 - accuracy: 0.7384 - val_loss: 0.6690 - val_accuracy: 0.6333 - 140ms/epoch - 2ms/step
## Epoch 169/200
## 84/84 - 0s - loss: 0.5332 - accuracy: 0.7395 - val_loss: 0.6688 - val_accuracy: 0.6333 - 119ms/epoch - 1ms/step
## Epoch 170/200
## 84/84 - 0s - loss: 0.5324 - accuracy: 0.7407 - val_loss: 0.6667 - val_accuracy: 0.6381 - 104ms/epoch - 1ms/step
## Epoch 171/200
## 84/84 - 0s - loss: 0.5323 - accuracy: 0.7407 - val_loss: 0.6704 - val_accuracy: 0.6333 - 101ms/epoch - 1ms/step
## Epoch 172/200
## 84/84 - 0s - loss: 0.5347 - accuracy: 0.7395 - val_loss: 0.6689 - val_accuracy: 0.6333 - 105ms/epoch - 1ms/step
## Epoch 173/200
## 84/84 - 0s - loss: 0.5348 - accuracy: 0.7360 - val_loss: 0.6702 - val_accuracy: 0.6333 - 104ms/epoch - 1ms/step
## Epoch 174/200
## 84/84 - 0s - loss: 0.5319 - accuracy: 0.7395 - val_loss: 0.6748 - val_accuracy: 0.6381 - 105ms/epoch - 1ms/step
## Epoch 175/200
## 84/84 - 0s - loss: 0.5341 - accuracy: 0.7372 - val_loss: 0.6731 - val_accuracy: 0.6381 - 106ms/epoch - 1ms/step
## Epoch 176/200
## 84/84 - 0s - loss: 0.5330 - accuracy: 0.7407 - val_loss: 0.6658 - val_accuracy: 0.6381 - 102ms/epoch - 1ms/step
## Epoch 177/200
## 84/84 - 0s - loss: 0.5334 - accuracy: 0.7395 - val_loss: 0.6711 - val_accuracy: 0.6381 - 103ms/epoch - 1ms/step
## Epoch 178/200
## 84/84 - 0s - loss: 0.5339 - accuracy: 0.7312 - val_loss: 0.6680 - val_accuracy: 0.6381 - 103ms/epoch - 1ms/step
## Epoch 179/200
## 84/84 - 0s - loss: 0.5338 - accuracy: 0.7395 - val_loss: 0.6691 - val_accuracy: 0.6333 - 106ms/epoch - 1ms/step
## Epoch 180/200
## 84/84 - 0s - loss: 0.5314 - accuracy: 0.7407 - val_loss: 0.6658 - val_accuracy: 0.6381 - 103ms/epoch - 1ms/step
## Epoch 181/200
## 84/84 - 0s - loss: 0.5335 - accuracy: 0.7348 - val_loss: 0.6706 - val_accuracy: 0.6333 - 102ms/epoch - 1ms/step
## Epoch 182/200
## 84/84 - 0s - loss: 0.5335 - accuracy: 0.7395 - val_loss: 0.6704 - val_accuracy: 0.6333 - 101ms/epoch - 1ms/step
## Epoch 183/200
## 84/84 - 0s - loss: 0.5324 - accuracy: 0.7395 - val_loss: 0.6635 - val_accuracy: 0.6381 - 104ms/epoch - 1ms/step
## Epoch 184/200
## 84/84 - 0s - loss: 0.5359 - accuracy: 0.7407 - val_loss: 0.6657 - val_accuracy: 0.6333 - 104ms/epoch - 1ms/step
## Epoch 185/200
## 84/84 - 0s - loss: 0.5326 - accuracy: 0.7384 - val_loss: 0.6691 - val_accuracy: 0.6333 - 104ms/epoch - 1ms/step
## Epoch 186/200
## 84/84 - 0s - loss: 0.5336 - accuracy: 0.7395 - val_loss: 0.6728 - val_accuracy: 0.6333 - 106ms/epoch - 1ms/step
## Epoch 187/200
## 84/84 - 0s - loss: 0.5336 - accuracy: 0.7372 - val_loss: 0.6714 - val_accuracy: 0.6333 - 103ms/epoch - 1ms/step
## Epoch 188/200
## 84/84 - 0s - loss: 0.5323 - accuracy: 0.7395 - val_loss: 0.6701 - val_accuracy: 0.6333 - 108ms/epoch - 1ms/step
## Epoch 189/200
## 84/84 - 0s - loss: 0.5326 - accuracy: 0.7360 - val_loss: 0.6706 - val_accuracy: 0.6333 - 101ms/epoch - 1ms/step
## Epoch 190/200
## 84/84 - 0s - loss: 0.5322 - accuracy: 0.7407 - val_loss: 0.6693 - val_accuracy: 0.6381 - 102ms/epoch - 1ms/step
## Epoch 191/200
## 84/84 - 0s - loss: 0.5320 - accuracy: 0.7372 - val_loss: 0.6737 - val_accuracy: 0.6381 - 102ms/epoch - 1ms/step
## Epoch 192/200
## 84/84 - 0s - loss: 0.5325 - accuracy: 0.7395 - val_loss: 0.6731 - val_accuracy: 0.6381 - 102ms/epoch - 1ms/step
## Epoch 193/200
## 84/84 - 0s - loss: 0.5333 - accuracy: 0.7360 - val_loss: 0.6739 - val_accuracy: 0.6381 - 103ms/epoch - 1ms/step
## Epoch 194/200
## 84/84 - 0s - loss: 0.5324 - accuracy: 0.7407 - val_loss: 0.6670 - val_accuracy: 0.6381 - 102ms/epoch - 1ms/step
## Epoch 195/200
## 84/84 - 0s - loss: 0.5328 - accuracy: 0.7348 - val_loss: 0.6672 - val_accuracy: 0.6333 - 103ms/epoch - 1ms/step
## Epoch 196/200
## 84/84 - 0s - loss: 0.5318 - accuracy: 0.7360 - val_loss: 0.6675 - val_accuracy: 0.6333 - 104ms/epoch - 1ms/step
## Epoch 197/200
## 84/84 - 0s - loss: 0.5361 - accuracy: 0.7407 - val_loss: 0.6721 - val_accuracy: 0.6333 - 102ms/epoch - 1ms/step
## Epoch 198/200
## 84/84 - 0s - loss: 0.5333 - accuracy: 0.7384 - val_loss: 0.6710 - val_accuracy: 0.6381 - 105ms/epoch - 1ms/step
## Epoch 199/200
## 84/84 - 0s - loss: 0.5291 - accuracy: 0.7467 - val_loss: 0.6659 - val_accuracy: 0.6333 - 102ms/epoch - 1ms/step
## Epoch 200/200
## 84/84 - 0s - loss: 0.5347 - accuracy: 0.7348 - val_loss: 0.6672 - val_accuracy: 0.6381 - 103ms/epoch - 1ms/step## 9/9 - 0s - loss: 0.6200 - accuracy: 0.6908 - 72ms/epoch - 8ms/step## loss accuracy
## 0.6199568 0.6908397# EDA on the loss and accuracy metrics of this model.2
# Plot the history
# plot(track.model.3)
#
# # NN model loss on the training data
# plot(track.model.3$metrics$loss, main="Model Loss",
# xlab = "Epoch", ylab="Loss", col="green", type="l", ylim=c(0.54, 0.7))
#
# # NN model loss of the 20% validation data
# lines(track.model.3$metrics$val_loss, col="blue", type="l")
#
# # Add legend
# legend("top", c("Training", "testing"), col=c("green", "blue"), lty=c(1,1))
#
# # Plot the accuracy of the training data
# plot(track.model.3$metrics$acc, main="Model 3 (Extra Layer/More Hidden Units)",
# xlab = "Epoch", ylab="Accuracy", col="blue", type="l", ylim=c(0.65, 0.76))
#
# # Plot the accuracy of the validation data
# lines(track.model.3$metrics$val_acc, col="green")
#
# # Add Legend
# legend("top", c("Training", "Testing"), col=c("blue", "green"), lty=c(1,1))
## plot_ly
epochs <- 200
time <- 1:epochs
hist_df3 <- data.frame(time=time, loss=track.model.3$metrics$loss, acc=track.model.3$metrics$acc,
valid_loss=track.model.3$metrics$val_loss, valid_acc=track.model.3$metrics$val_acc)
plot_ly(hist_df3, x = ~time) %>%
add_trace(y = ~loss, name = 'training loss', mode = 'lines') %>%
add_trace(y = ~acc, name = 'training accuracy', mode = 'lines+markers') %>%
add_trace(y = ~valid_loss, name = 'validation loss',mode = 'lines+markers') %>%
add_trace(y = ~valid_acc, name = 'validation accuracy', mode = 'lines+markers') %>%
layout(title="Titanic (model.3) NN Model Performance",
legend = list(orientation = 'h'), yaxis=list(title="metric"))Finally, we can attempt to fine-tune the optimization parameters
provided to the compile() function. For instance, we can
experiment with alternative optimization algorithms, like the Stochastic
Gradient Descent (SGD), optimizer_sgd(), and adjust the
learning rate, learning_rate. In addition, we can
specify alternative learning rate to train the NN, typically by 10-fold
increase or decrease, which trades algorithmic accuracy, speed of
convergence, and avoidance of local minima.
model.4 <- keras_model_sequential()
# Add layers and Node-Units to model
model.4 %>%
layer_dense(units = 30, activation = 'relu', input_shape = c(4)) %>%
layer_dense(units = 15, activation = 'relu') %>%
layer_dense(units = 2, activation = 'softmax')
# Define an optimizer
SGD <- optimizer_sgd(learning_rate = 0.001)
# Compile the model
model.4 %>% compile(
optimizer=SGD,
loss = 'binary_crossentropy',
metrics = 'accuracy'
)
# Fit NN model to training data & Save the training history
set.seed(1234)
track.model.4 <- model.4 %>% fit(
train_dat2.X,
train_dat2.Y,
epochs = 200,
batch_size = 10,
validation_split = 0.1
)## Epoch 1/200
## 95/95 - 0s - loss: 0.6789 - accuracy: 0.6178 - val_loss: 0.6886 - val_accuracy: 0.5333 - 378ms/epoch - 4ms/step
## Epoch 2/200
## 95/95 - 0s - loss: 0.6772 - accuracy: 0.6178 - val_loss: 0.6879 - val_accuracy: 0.5333 - 94ms/epoch - 989us/step
## Epoch 3/200
## 95/95 - 0s - loss: 0.6757 - accuracy: 0.6178 - val_loss: 0.6873 - val_accuracy: 0.5333 - 95ms/epoch - 1ms/step
## Epoch 4/200
## 95/95 - 0s - loss: 0.6743 - accuracy: 0.6178 - val_loss: 0.6868 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 5/200
## 95/95 - 0s - loss: 0.6732 - accuracy: 0.6178 - val_loss: 0.6866 - val_accuracy: 0.5333 - 95ms/epoch - 997us/step
## Epoch 6/200
## 95/95 - 0s - loss: 0.6724 - accuracy: 0.6178 - val_loss: 0.6864 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 7/200
## 95/95 - 0s - loss: 0.6716 - accuracy: 0.6178 - val_loss: 0.6862 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 8/200
## 95/95 - 0s - loss: 0.6708 - accuracy: 0.6178 - val_loss: 0.6859 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 9/200
## 95/95 - 0s - loss: 0.6698 - accuracy: 0.6178 - val_loss: 0.6856 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 10/200
## 95/95 - 0s - loss: 0.6689 - accuracy: 0.6178 - val_loss: 0.6853 - val_accuracy: 0.5333 - 99ms/epoch - 1ms/step
## Epoch 11/200
## 95/95 - 0s - loss: 0.6679 - accuracy: 0.6178 - val_loss: 0.6849 - val_accuracy: 0.5333 - 128ms/epoch - 1ms/step
## Epoch 12/200
## 95/95 - 0s - loss: 0.6670 - accuracy: 0.6178 - val_loss: 0.6846 - val_accuracy: 0.5333 - 103ms/epoch - 1ms/step
## Epoch 13/200
## 95/95 - 0s - loss: 0.6661 - accuracy: 0.6178 - val_loss: 0.6843 - val_accuracy: 0.5333 - 100ms/epoch - 1ms/step
## Epoch 14/200
## 95/95 - 0s - loss: 0.6652 - accuracy: 0.6178 - val_loss: 0.6840 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 15/200
## 95/95 - 0s - loss: 0.6644 - accuracy: 0.6178 - val_loss: 0.6838 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 16/200
## 95/95 - 0s - loss: 0.6636 - accuracy: 0.6178 - val_loss: 0.6835 - val_accuracy: 0.5333 - 99ms/epoch - 1ms/step
## Epoch 17/200
## 95/95 - 0s - loss: 0.6628 - accuracy: 0.6178 - val_loss: 0.6833 - val_accuracy: 0.5333 - 100ms/epoch - 1ms/step
## Epoch 18/200
## 95/95 - 0s - loss: 0.6620 - accuracy: 0.6178 - val_loss: 0.6830 - val_accuracy: 0.5333 - 104ms/epoch - 1ms/step
## Epoch 19/200
## 95/95 - 0s - loss: 0.6613 - accuracy: 0.6178 - val_loss: 0.6828 - val_accuracy: 0.5333 - 100ms/epoch - 1ms/step
## Epoch 20/200
## 95/95 - 0s - loss: 0.6606 - accuracy: 0.6178 - val_loss: 0.6826 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 21/200
## 95/95 - 0s - loss: 0.6599 - accuracy: 0.6178 - val_loss: 0.6824 - val_accuracy: 0.5333 - 95ms/epoch - 1ms/step
## Epoch 22/200
## 95/95 - 0s - loss: 0.6592 - accuracy: 0.6178 - val_loss: 0.6822 - val_accuracy: 0.5333 - 94ms/epoch - 987us/step
## Epoch 23/200
## 95/95 - 0s - loss: 0.6586 - accuracy: 0.6178 - val_loss: 0.6820 - val_accuracy: 0.5333 - 95ms/epoch - 1ms/step
## Epoch 24/200
## 95/95 - 0s - loss: 0.6580 - accuracy: 0.6178 - val_loss: 0.6818 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 25/200
## 95/95 - 0s - loss: 0.6574 - accuracy: 0.6178 - val_loss: 0.6817 - val_accuracy: 0.5333 - 95ms/epoch - 1000us/step
## Epoch 26/200
## 95/95 - 0s - loss: 0.6568 - accuracy: 0.6178 - val_loss: 0.6816 - val_accuracy: 0.5333 - 101ms/epoch - 1ms/step
## Epoch 27/200
## 95/95 - 0s - loss: 0.6563 - accuracy: 0.6178 - val_loss: 0.6815 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 28/200
## 95/95 - 0s - loss: 0.6558 - accuracy: 0.6178 - val_loss: 0.6814 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 29/200
## 95/95 - 0s - loss: 0.6553 - accuracy: 0.6178 - val_loss: 0.6813 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 30/200
## 95/95 - 0s - loss: 0.6548 - accuracy: 0.6178 - val_loss: 0.6813 - val_accuracy: 0.5333 - 101ms/epoch - 1ms/step
## Epoch 31/200
## 95/95 - 0s - loss: 0.6544 - accuracy: 0.6178 - val_loss: 0.6812 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 32/200
## 95/95 - 0s - loss: 0.6540 - accuracy: 0.6178 - val_loss: 0.6811 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 33/200
## 95/95 - 0s - loss: 0.6536 - accuracy: 0.6178 - val_loss: 0.6811 - val_accuracy: 0.5333 - 99ms/epoch - 1ms/step
## Epoch 34/200
## 95/95 - 0s - loss: 0.6532 - accuracy: 0.6178 - val_loss: 0.6811 - val_accuracy: 0.5333 - 95ms/epoch - 997us/step
## Epoch 35/200
## 95/95 - 0s - loss: 0.6529 - accuracy: 0.6178 - val_loss: 0.6810 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 36/200
## 95/95 - 0s - loss: 0.6525 - accuracy: 0.6178 - val_loss: 0.6809 - val_accuracy: 0.5333 - 95ms/epoch - 997us/step
## Epoch 37/200
## 95/95 - 0s - loss: 0.6522 - accuracy: 0.6178 - val_loss: 0.6808 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 38/200
## 95/95 - 0s - loss: 0.6519 - accuracy: 0.6178 - val_loss: 0.6808 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 39/200
## 95/95 - 0s - loss: 0.6515 - accuracy: 0.6178 - val_loss: 0.6807 - val_accuracy: 0.5333 - 95ms/epoch - 998us/step
## Epoch 40/200
## 95/95 - 0s - loss: 0.6512 - accuracy: 0.6178 - val_loss: 0.6806 - val_accuracy: 0.5333 - 95ms/epoch - 1ms/step
## Epoch 41/200
## 95/95 - 0s - loss: 0.6509 - accuracy: 0.6178 - val_loss: 0.6805 - val_accuracy: 0.5333 - 94ms/epoch - 990us/step
## Epoch 42/200
## 95/95 - 0s - loss: 0.6506 - accuracy: 0.6178 - val_loss: 0.6804 - val_accuracy: 0.5333 - 104ms/epoch - 1ms/step
## Epoch 43/200
## 95/95 - 0s - loss: 0.6503 - accuracy: 0.6178 - val_loss: 0.6803 - val_accuracy: 0.5333 - 100ms/epoch - 1ms/step
## Epoch 44/200
## 95/95 - 0s - loss: 0.6500 - accuracy: 0.6178 - val_loss: 0.6802 - val_accuracy: 0.5333 - 95ms/epoch - 1ms/step
## Epoch 45/200
## 95/95 - 0s - loss: 0.6497 - accuracy: 0.6178 - val_loss: 0.6801 - val_accuracy: 0.5333 - 95ms/epoch - 997us/step
## Epoch 46/200
## 95/95 - 0s - loss: 0.6494 - accuracy: 0.6178 - val_loss: 0.6800 - val_accuracy: 0.5333 - 95ms/epoch - 996us/step
## Epoch 47/200
## 95/95 - 0s - loss: 0.6492 - accuracy: 0.6178 - val_loss: 0.6798 - val_accuracy: 0.5333 - 93ms/epoch - 976us/step
## Epoch 48/200
## 95/95 - 0s - loss: 0.6489 - accuracy: 0.6178 - val_loss: 0.6797 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 49/200
## 95/95 - 0s - loss: 0.6486 - accuracy: 0.6178 - val_loss: 0.6796 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 50/200
## 95/95 - 0s - loss: 0.6483 - accuracy: 0.6178 - val_loss: 0.6795 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 51/200
## 95/95 - 0s - loss: 0.6481 - accuracy: 0.6178 - val_loss: 0.6794 - val_accuracy: 0.5333 - 92ms/epoch - 972us/step
## Epoch 52/200
## 95/95 - 0s - loss: 0.6478 - accuracy: 0.6178 - val_loss: 0.6792 - val_accuracy: 0.5333 - 95ms/epoch - 1ms/step
## Epoch 53/200
## 95/95 - 0s - loss: 0.6476 - accuracy: 0.6178 - val_loss: 0.6791 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 54/200
## 95/95 - 0s - loss: 0.6473 - accuracy: 0.6178 - val_loss: 0.6790 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 55/200
## 95/95 - 0s - loss: 0.6470 - accuracy: 0.6178 - val_loss: 0.6789 - val_accuracy: 0.5333 - 94ms/epoch - 990us/step
## Epoch 56/200
## 95/95 - 0s - loss: 0.6468 - accuracy: 0.6178 - val_loss: 0.6787 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 57/200
## 95/95 - 0s - loss: 0.6465 - accuracy: 0.6178 - val_loss: 0.6786 - val_accuracy: 0.5333 - 99ms/epoch - 1ms/step
## Epoch 58/200
## 95/95 - 0s - loss: 0.6463 - accuracy: 0.6178 - val_loss: 0.6785 - val_accuracy: 0.5333 - 93ms/epoch - 978us/step
## Epoch 59/200
## 95/95 - 0s - loss: 0.6460 - accuracy: 0.6178 - val_loss: 0.6784 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 60/200
## 95/95 - 0s - loss: 0.6458 - accuracy: 0.6178 - val_loss: 0.6782 - val_accuracy: 0.5333 - 111ms/epoch - 1ms/step
## Epoch 61/200
## 95/95 - 0s - loss: 0.6456 - accuracy: 0.6178 - val_loss: 0.6781 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 62/200
## 95/95 - 0s - loss: 0.6453 - accuracy: 0.6178 - val_loss: 0.6779 - val_accuracy: 0.5333 - 95ms/epoch - 1ms/step
## Epoch 63/200
## 95/95 - 0s - loss: 0.6451 - accuracy: 0.6178 - val_loss: 0.6777 - val_accuracy: 0.5333 - 92ms/epoch - 964us/step
## Epoch 64/200
## 95/95 - 0s - loss: 0.6448 - accuracy: 0.6178 - val_loss: 0.6775 - val_accuracy: 0.5333 - 93ms/epoch - 974us/step
## Epoch 65/200
## 95/95 - 0s - loss: 0.6446 - accuracy: 0.6178 - val_loss: 0.6774 - val_accuracy: 0.5333 - 101ms/epoch - 1ms/step
## Epoch 66/200
## 95/95 - 0s - loss: 0.6444 - accuracy: 0.6178 - val_loss: 0.6772 - val_accuracy: 0.5333 - 95ms/epoch - 1ms/step
## Epoch 67/200
## 95/95 - 0s - loss: 0.6441 - accuracy: 0.6178 - val_loss: 0.6770 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 68/200
## 95/95 - 0s - loss: 0.6439 - accuracy: 0.6178 - val_loss: 0.6768 - val_accuracy: 0.5333 - 94ms/epoch - 992us/step
## Epoch 69/200
## 95/95 - 0s - loss: 0.6436 - accuracy: 0.6178 - val_loss: 0.6766 - val_accuracy: 0.5333 - 100ms/epoch - 1ms/step
## Epoch 70/200
## 95/95 - 0s - loss: 0.6434 - accuracy: 0.6178 - val_loss: 0.6764 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 71/200
## 95/95 - 0s - loss: 0.6431 - accuracy: 0.6178 - val_loss: 0.6762 - val_accuracy: 0.5333 - 102ms/epoch - 1ms/step
## Epoch 72/200
## 95/95 - 0s - loss: 0.6429 - accuracy: 0.6178 - val_loss: 0.6760 - val_accuracy: 0.5333 - 95ms/epoch - 1ms/step
## Epoch 73/200
## 95/95 - 0s - loss: 0.6427 - accuracy: 0.6178 - val_loss: 0.6759 - val_accuracy: 0.5333 - 95ms/epoch - 1ms/step
## Epoch 74/200
## 95/95 - 0s - loss: 0.6424 - accuracy: 0.6178 - val_loss: 0.6757 - val_accuracy: 0.5333 - 95ms/epoch - 1ms/step
## Epoch 75/200
## 95/95 - 0s - loss: 0.6422 - accuracy: 0.6178 - val_loss: 0.6755 - val_accuracy: 0.5333 - 95ms/epoch - 998us/step
## Epoch 76/200
## 95/95 - 0s - loss: 0.6419 - accuracy: 0.6178 - val_loss: 0.6753 - val_accuracy: 0.5333 - 93ms/epoch - 983us/step
## Epoch 77/200
## 95/95 - 0s - loss: 0.6417 - accuracy: 0.6178 - val_loss: 0.6751 - val_accuracy: 0.5333 - 95ms/epoch - 1000us/step
## Epoch 78/200
## 95/95 - 0s - loss: 0.6414 - accuracy: 0.6178 - val_loss: 0.6749 - val_accuracy: 0.5333 - 99ms/epoch - 1ms/step
## Epoch 79/200
## 95/95 - 0s - loss: 0.6412 - accuracy: 0.6178 - val_loss: 0.6746 - val_accuracy: 0.5333 - 95ms/epoch - 1ms/step
## Epoch 80/200
## 95/95 - 0s - loss: 0.6410 - accuracy: 0.6178 - val_loss: 0.6744 - val_accuracy: 0.5333 - 92ms/epoch - 973us/step
## Epoch 81/200
## 95/95 - 0s - loss: 0.6407 - accuracy: 0.6178 - val_loss: 0.6741 - val_accuracy: 0.5333 - 95ms/epoch - 1ms/step
## Epoch 82/200
## 95/95 - 0s - loss: 0.6405 - accuracy: 0.6178 - val_loss: 0.6740 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 83/200
## 95/95 - 0s - loss: 0.6402 - accuracy: 0.6178 - val_loss: 0.6738 - val_accuracy: 0.5333 - 92ms/epoch - 968us/step
## Epoch 84/200
## 95/95 - 0s - loss: 0.6400 - accuracy: 0.6178 - val_loss: 0.6736 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 85/200
## 95/95 - 0s - loss: 0.6398 - accuracy: 0.6178 - val_loss: 0.6734 - val_accuracy: 0.5333 - 95ms/epoch - 997us/step
## Epoch 86/200
## 95/95 - 0s - loss: 0.6395 - accuracy: 0.6178 - val_loss: 0.6732 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 87/200
## 95/95 - 0s - loss: 0.6393 - accuracy: 0.6178 - val_loss: 0.6730 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 88/200
## 95/95 - 0s - loss: 0.6390 - accuracy: 0.6178 - val_loss: 0.6728 - val_accuracy: 0.5333 - 94ms/epoch - 993us/step
## Epoch 89/200
## 95/95 - 0s - loss: 0.6388 - accuracy: 0.6178 - val_loss: 0.6724 - val_accuracy: 0.5333 - 94ms/epoch - 986us/step
## Epoch 90/200
## 95/95 - 0s - loss: 0.6386 - accuracy: 0.6178 - val_loss: 0.6722 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 91/200
## 95/95 - 0s - loss: 0.6383 - accuracy: 0.6178 - val_loss: 0.6719 - val_accuracy: 0.5333 - 99ms/epoch - 1ms/step
## Epoch 92/200
## 95/95 - 0s - loss: 0.6381 - accuracy: 0.6178 - val_loss: 0.6717 - val_accuracy: 0.5333 - 100ms/epoch - 1ms/step
## Epoch 93/200
## 95/95 - 0s - loss: 0.6379 - accuracy: 0.6178 - val_loss: 0.6715 - val_accuracy: 0.5333 - 95ms/epoch - 999us/step
## Epoch 94/200
## 95/95 - 0s - loss: 0.6376 - accuracy: 0.6178 - val_loss: 0.6713 - val_accuracy: 0.5333 - 95ms/epoch - 1000us/step
## Epoch 95/200
## 95/95 - 0s - loss: 0.6374 - accuracy: 0.6178 - val_loss: 0.6710 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 96/200
## 95/95 - 0s - loss: 0.6372 - accuracy: 0.6178 - val_loss: 0.6708 - val_accuracy: 0.5333 - 99ms/epoch - 1ms/step
## Epoch 97/200
## 95/95 - 0s - loss: 0.6369 - accuracy: 0.6178 - val_loss: 0.6705 - val_accuracy: 0.5333 - 95ms/epoch - 1ms/step
## Epoch 98/200
## 95/95 - 0s - loss: 0.6367 - accuracy: 0.6178 - val_loss: 0.6703 - val_accuracy: 0.5333 - 95ms/epoch - 998us/step
## Epoch 99/200
## 95/95 - 0s - loss: 0.6365 - accuracy: 0.6178 - val_loss: 0.6701 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 100/200
## 95/95 - 0s - loss: 0.6362 - accuracy: 0.6178 - val_loss: 0.6698 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 101/200
## 95/95 - 0s - loss: 0.6360 - accuracy: 0.6178 - val_loss: 0.6695 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 102/200
## 95/95 - 0s - loss: 0.6358 - accuracy: 0.6178 - val_loss: 0.6692 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 103/200
## 95/95 - 0s - loss: 0.6355 - accuracy: 0.6178 - val_loss: 0.6689 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 104/200
## 95/95 - 0s - loss: 0.6353 - accuracy: 0.6178 - val_loss: 0.6687 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 105/200
## 95/95 - 0s - loss: 0.6351 - accuracy: 0.6178 - val_loss: 0.6685 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 106/200
## 95/95 - 0s - loss: 0.6349 - accuracy: 0.6178 - val_loss: 0.6682 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 107/200
## 95/95 - 0s - loss: 0.6347 - accuracy: 0.6178 - val_loss: 0.6679 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 108/200
## 95/95 - 0s - loss: 0.6344 - accuracy: 0.6178 - val_loss: 0.6678 - val_accuracy: 0.5333 - 94ms/epoch - 992us/step
## Epoch 109/200
## 95/95 - 0s - loss: 0.6342 - accuracy: 0.6178 - val_loss: 0.6676 - val_accuracy: 0.5333 - 99ms/epoch - 1ms/step
## Epoch 110/200
## 95/95 - 0s - loss: 0.6340 - accuracy: 0.6178 - val_loss: 0.6674 - val_accuracy: 0.5333 - 112ms/epoch - 1ms/step
## Epoch 111/200
## 95/95 - 0s - loss: 0.6338 - accuracy: 0.6178 - val_loss: 0.6672 - val_accuracy: 0.5333 - 116ms/epoch - 1ms/step
## Epoch 112/200
## 95/95 - 0s - loss: 0.6336 - accuracy: 0.6178 - val_loss: 0.6670 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 113/200
## 95/95 - 0s - loss: 0.6334 - accuracy: 0.6178 - val_loss: 0.6668 - val_accuracy: 0.5333 - 100ms/epoch - 1ms/step
## Epoch 114/200
## 95/95 - 0s - loss: 0.6332 - accuracy: 0.6178 - val_loss: 0.6666 - val_accuracy: 0.5333 - 103ms/epoch - 1ms/step
## Epoch 115/200
## 95/95 - 0s - loss: 0.6331 - accuracy: 0.6178 - val_loss: 0.6664 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 116/200
## 95/95 - 0s - loss: 0.6329 - accuracy: 0.6178 - val_loss: 0.6661 - val_accuracy: 0.5333 - 99ms/epoch - 1ms/step
## Epoch 117/200
## 95/95 - 0s - loss: 0.6327 - accuracy: 0.6178 - val_loss: 0.6659 - val_accuracy: 0.5333 - 93ms/epoch - 981us/step
## Epoch 118/200
## 95/95 - 0s - loss: 0.6325 - accuracy: 0.6178 - val_loss: 0.6658 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 119/200
## 95/95 - 0s - loss: 0.6323 - accuracy: 0.6178 - val_loss: 0.6656 - val_accuracy: 0.5333 - 93ms/epoch - 978us/step
## Epoch 120/200
## 95/95 - 0s - loss: 0.6321 - accuracy: 0.6178 - val_loss: 0.6654 - val_accuracy: 0.5333 - 101ms/epoch - 1ms/step
## Epoch 121/200
## 95/95 - 0s - loss: 0.6319 - accuracy: 0.6178 - val_loss: 0.6653 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 122/200
## 95/95 - 0s - loss: 0.6318 - accuracy: 0.6178 - val_loss: 0.6652 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 123/200
## 95/95 - 0s - loss: 0.6316 - accuracy: 0.6178 - val_loss: 0.6650 - val_accuracy: 0.5333 - 101ms/epoch - 1ms/step
## Epoch 124/200
## 95/95 - 0s - loss: 0.6314 - accuracy: 0.6178 - val_loss: 0.6648 - val_accuracy: 0.5333 - 102ms/epoch - 1ms/step
## Epoch 125/200
## 95/95 - 0s - loss: 0.6312 - accuracy: 0.6178 - val_loss: 0.6647 - val_accuracy: 0.5333 - 106ms/epoch - 1ms/step
## Epoch 126/200
## 95/95 - 0s - loss: 0.6310 - accuracy: 0.6178 - val_loss: 0.6645 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 127/200
## 95/95 - 0s - loss: 0.6309 - accuracy: 0.6178 - val_loss: 0.6643 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 128/200
## 95/95 - 0s - loss: 0.6307 - accuracy: 0.6178 - val_loss: 0.6641 - val_accuracy: 0.5333 - 100ms/epoch - 1ms/step
## Epoch 129/200
## 95/95 - 0s - loss: 0.6305 - accuracy: 0.6178 - val_loss: 0.6639 - val_accuracy: 0.5333 - 93ms/epoch - 978us/step
## Epoch 130/200
## 95/95 - 0s - loss: 0.6304 - accuracy: 0.6178 - val_loss: 0.6636 - val_accuracy: 0.5333 - 95ms/epoch - 996us/step
## Epoch 131/200
## 95/95 - 0s - loss: 0.6302 - accuracy: 0.6178 - val_loss: 0.6634 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 132/200
## 95/95 - 0s - loss: 0.6300 - accuracy: 0.6178 - val_loss: 0.6631 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 133/200
## 95/95 - 0s - loss: 0.6299 - accuracy: 0.6178 - val_loss: 0.6629 - val_accuracy: 0.5333 - 99ms/epoch - 1ms/step
## Epoch 134/200
## 95/95 - 0s - loss: 0.6297 - accuracy: 0.6178 - val_loss: 0.6628 - val_accuracy: 0.5333 - 140ms/epoch - 1ms/step
## Epoch 135/200
## 95/95 - 0s - loss: 0.6295 - accuracy: 0.6178 - val_loss: 0.6627 - val_accuracy: 0.5333 - 102ms/epoch - 1ms/step
## Epoch 136/200
## 95/95 - 0s - loss: 0.6293 - accuracy: 0.6178 - val_loss: 0.6625 - val_accuracy: 0.5333 - 99ms/epoch - 1ms/step
## Epoch 137/200
## 95/95 - 0s - loss: 0.6292 - accuracy: 0.6178 - val_loss: 0.6623 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 138/200
## 95/95 - 0s - loss: 0.6290 - accuracy: 0.6178 - val_loss: 0.6621 - val_accuracy: 0.5333 - 101ms/epoch - 1ms/step
## Epoch 139/200
## 95/95 - 0s - loss: 0.6288 - accuracy: 0.6178 - val_loss: 0.6619 - val_accuracy: 0.5333 - 91ms/epoch - 962us/step
## Epoch 140/200
## 95/95 - 0s - loss: 0.6287 - accuracy: 0.6178 - val_loss: 0.6618 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 141/200
## 95/95 - 0s - loss: 0.6285 - accuracy: 0.6178 - val_loss: 0.6615 - val_accuracy: 0.5333 - 95ms/epoch - 996us/step
## Epoch 142/200
## 95/95 - 0s - loss: 0.6284 - accuracy: 0.6178 - val_loss: 0.6613 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 143/200
## 95/95 - 0s - loss: 0.6282 - accuracy: 0.6178 - val_loss: 0.6611 - val_accuracy: 0.5333 - 92ms/epoch - 970us/step
## Epoch 144/200
## 95/95 - 0s - loss: 0.6281 - accuracy: 0.6178 - val_loss: 0.6610 - val_accuracy: 0.5333 - 94ms/epoch - 992us/step
## Epoch 145/200
## 95/95 - 0s - loss: 0.6279 - accuracy: 0.6178 - val_loss: 0.6609 - val_accuracy: 0.5333 - 99ms/epoch - 1ms/step
## Epoch 146/200
## 95/95 - 0s - loss: 0.6278 - accuracy: 0.6178 - val_loss: 0.6607 - val_accuracy: 0.5333 - 92ms/epoch - 970us/step
## Epoch 147/200
## 95/95 - 0s - loss: 0.6276 - accuracy: 0.6178 - val_loss: 0.6605 - val_accuracy: 0.5333 - 99ms/epoch - 1ms/step
## Epoch 148/200
## 95/95 - 0s - loss: 0.6274 - accuracy: 0.6178 - val_loss: 0.6604 - val_accuracy: 0.5333 - 103ms/epoch - 1ms/step
## Epoch 149/200
## 95/95 - 0s - loss: 0.6273 - accuracy: 0.6178 - val_loss: 0.6602 - val_accuracy: 0.5333 - 93ms/epoch - 984us/step
## Epoch 150/200
## 95/95 - 0s - loss: 0.6271 - accuracy: 0.6178 - val_loss: 0.6600 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 151/200
## 95/95 - 0s - loss: 0.6270 - accuracy: 0.6178 - val_loss: 0.6598 - val_accuracy: 0.5333 - 94ms/epoch - 992us/step
## Epoch 152/200
## 95/95 - 0s - loss: 0.6269 - accuracy: 0.6178 - val_loss: 0.6596 - val_accuracy: 0.5333 - 94ms/epoch - 991us/step
## Epoch 153/200
## 95/95 - 0s - loss: 0.6267 - accuracy: 0.6178 - val_loss: 0.6594 - val_accuracy: 0.5333 - 95ms/epoch - 1000us/step
## Epoch 154/200
## 95/95 - 0s - loss: 0.6265 - accuracy: 0.6178 - val_loss: 0.6592 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 155/200
## 95/95 - 0s - loss: 0.6264 - accuracy: 0.6178 - val_loss: 0.6591 - val_accuracy: 0.5333 - 93ms/epoch - 976us/step
## Epoch 156/200
## 95/95 - 0s - loss: 0.6262 - accuracy: 0.6178 - val_loss: 0.6590 - val_accuracy: 0.5333 - 105ms/epoch - 1ms/step
## Epoch 157/200
## 95/95 - 0s - loss: 0.6261 - accuracy: 0.6178 - val_loss: 0.6588 - val_accuracy: 0.5333 - 94ms/epoch - 986us/step
## Epoch 158/200
## 95/95 - 0s - loss: 0.6260 - accuracy: 0.6178 - val_loss: 0.6587 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 159/200
## 95/95 - 0s - loss: 0.6258 - accuracy: 0.6178 - val_loss: 0.6585 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 160/200
## 95/95 - 0s - loss: 0.6257 - accuracy: 0.6178 - val_loss: 0.6583 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 161/200
## 95/95 - 0s - loss: 0.6255 - accuracy: 0.6178 - val_loss: 0.6581 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 162/200
## 95/95 - 0s - loss: 0.6254 - accuracy: 0.6178 - val_loss: 0.6579 - val_accuracy: 0.5333 - 99ms/epoch - 1ms/step
## Epoch 163/200
## 95/95 - 0s - loss: 0.6253 - accuracy: 0.6178 - val_loss: 0.6577 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 164/200
## 95/95 - 0s - loss: 0.6251 - accuracy: 0.6178 - val_loss: 0.6576 - val_accuracy: 0.5333 - 99ms/epoch - 1ms/step
## Epoch 165/200
## 95/95 - 0s - loss: 0.6250 - accuracy: 0.6178 - val_loss: 0.6574 - val_accuracy: 0.5333 - 94ms/epoch - 991us/step
## Epoch 166/200
## 95/95 - 0s - loss: 0.6248 - accuracy: 0.6178 - val_loss: 0.6572 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 167/200
## 95/95 - 0s - loss: 0.6247 - accuracy: 0.6178 - val_loss: 0.6571 - val_accuracy: 0.5333 - 94ms/epoch - 988us/step
## Epoch 168/200
## 95/95 - 0s - loss: 0.6245 - accuracy: 0.6178 - val_loss: 0.6569 - val_accuracy: 0.5333 - 93ms/epoch - 975us/step
## Epoch 169/200
## 95/95 - 0s - loss: 0.6244 - accuracy: 0.6178 - val_loss: 0.6568 - val_accuracy: 0.5333 - 95ms/epoch - 1ms/step
## Epoch 170/200
## 95/95 - 0s - loss: 0.6243 - accuracy: 0.6178 - val_loss: 0.6567 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 171/200
## 95/95 - 0s - loss: 0.6241 - accuracy: 0.6178 - val_loss: 0.6565 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 172/200
## 95/95 - 0s - loss: 0.6240 - accuracy: 0.6178 - val_loss: 0.6564 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 173/200
## 95/95 - 0s - loss: 0.6239 - accuracy: 0.6178 - val_loss: 0.6562 - val_accuracy: 0.5333 - 95ms/epoch - 1ms/step
## Epoch 174/200
## 95/95 - 0s - loss: 0.6237 - accuracy: 0.6178 - val_loss: 0.6561 - val_accuracy: 0.5333 - 99ms/epoch - 1ms/step
## Epoch 175/200
## 95/95 - 0s - loss: 0.6236 - accuracy: 0.6178 - val_loss: 0.6560 - val_accuracy: 0.5333 - 103ms/epoch - 1ms/step
## Epoch 176/200
## 95/95 - 0s - loss: 0.6234 - accuracy: 0.6178 - val_loss: 0.6557 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 177/200
## 95/95 - 0s - loss: 0.6233 - accuracy: 0.6178 - val_loss: 0.6556 - val_accuracy: 0.5333 - 98ms/epoch - 1ms/step
## Epoch 178/200
## 95/95 - 0s - loss: 0.6232 - accuracy: 0.6178 - val_loss: 0.6555 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 179/200
## 95/95 - 0s - loss: 0.6230 - accuracy: 0.6178 - val_loss: 0.6554 - val_accuracy: 0.5333 - 94ms/epoch - 992us/step
## Epoch 180/200
## 95/95 - 0s - loss: 0.6229 - accuracy: 0.6178 - val_loss: 0.6551 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 181/200
## 95/95 - 0s - loss: 0.6228 - accuracy: 0.6178 - val_loss: 0.6548 - val_accuracy: 0.5333 - 93ms/epoch - 983us/step
## Epoch 182/200
## 95/95 - 0s - loss: 0.6226 - accuracy: 0.6178 - val_loss: 0.6547 - val_accuracy: 0.5333 - 93ms/epoch - 978us/step
## Epoch 183/200
## 95/95 - 0s - loss: 0.6225 - accuracy: 0.6178 - val_loss: 0.6546 - val_accuracy: 0.5333 - 93ms/epoch - 982us/step
## Epoch 184/200
## 95/95 - 0s - loss: 0.6224 - accuracy: 0.6178 - val_loss: 0.6545 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 185/200
## 95/95 - 0s - loss: 0.6223 - accuracy: 0.6178 - val_loss: 0.6542 - val_accuracy: 0.5333 - 96ms/epoch - 1ms/step
## Epoch 186/200
## 95/95 - 0s - loss: 0.6221 - accuracy: 0.6178 - val_loss: 0.6540 - val_accuracy: 0.5333 - 97ms/epoch - 1ms/step
## Epoch 187/200
## 95/95 - 0s - loss: 0.6220 - accuracy: 0.6189 - val_loss: 0.6537 - val_accuracy: 0.5333 - 95ms/epoch - 998us/step
## Epoch 188/200
## 95/95 - 0s - loss: 0.6219 - accuracy: 0.6200 - val_loss: 0.6536 - val_accuracy: 0.5333 - 94ms/epoch - 991us/step
## Epoch 189/200
## 95/95 - 0s - loss: 0.6217 - accuracy: 0.6200 - val_loss: 0.6535 - val_accuracy: 0.5333 - 94ms/epoch - 992us/step
## Epoch 190/200
## 95/95 - 0s - loss: 0.6216 - accuracy: 0.6200 - val_loss: 0.6533 - val_accuracy: 0.5333 - 95ms/epoch - 1ms/step
## Epoch 191/200
## 95/95 - 0s - loss: 0.6215 - accuracy: 0.6200 - val_loss: 0.6531 - val_accuracy: 0.5333 - 92ms/epoch - 972us/step
## Epoch 192/200
## 95/95 - 0s - loss: 0.6214 - accuracy: 0.6200 - val_loss: 0.6530 - val_accuracy: 0.5333 - 95ms/epoch - 998us/step
## Epoch 193/200
## 95/95 - 0s - loss: 0.6212 - accuracy: 0.6200 - val_loss: 0.6528 - val_accuracy: 0.5333 - 125ms/epoch - 1ms/step
## Epoch 194/200
## 95/95 - 0s - loss: 0.6211 - accuracy: 0.6200 - val_loss: 0.6526 - val_accuracy: 0.5429 - 96ms/epoch - 1ms/step
## Epoch 195/200
## 95/95 - 0s - loss: 0.6210 - accuracy: 0.6200 - val_loss: 0.6525 - val_accuracy: 0.5429 - 101ms/epoch - 1ms/step
## Epoch 196/200
## 95/95 - 0s - loss: 0.6208 - accuracy: 0.6189 - val_loss: 0.6523 - val_accuracy: 0.5429 - 95ms/epoch - 1ms/step
## Epoch 197/200
## 95/95 - 0s - loss: 0.6207 - accuracy: 0.6253 - val_loss: 0.6521 - val_accuracy: 0.5429 - 94ms/epoch - 986us/step
## Epoch 198/200
## 95/95 - 0s - loss: 0.6206 - accuracy: 0.6274 - val_loss: 0.6518 - val_accuracy: 0.5714 - 96ms/epoch - 1ms/step
## Epoch 199/200
## 95/95 - 0s - loss: 0.6205 - accuracy: 0.6444 - val_loss: 0.6516 - val_accuracy: 0.5714 - 96ms/epoch - 1ms/step
## Epoch 200/200
## 95/95 - 0s - loss: 0.6204 - accuracy: 0.6497 - val_loss: 0.6514 - val_accuracy: 0.5810 - 97ms/epoch - 1ms/step## 9/9 - 0s - loss: 0.6141 - accuracy: 0.6679 - 21ms/epoch - 2ms/step## loss accuracy
## 0.6141219 0.6679389# EDA on the loss and accuracy metrics of this model.2
# Plot the history
# plot(track.model.4)
#
# # NN model loss on the training data
# plot(track.model.4$metrics$loss, main="Model 4 Loss",
# xlab = "Epoch", ylab="Loss", col="green", type="l", ylim=c(0.54, 0.7))
#
# # NN model loss of the 20% validation data
# lines(track.model.4$metrics$val_loss, col="blue", type="l")
#
# # Add legend
# legend("top", c("Training", "Testing"), col=c("green", "blue"), lty=c(1,1))
#
# # Plot the accuracy of the training data
# plot(track.model.4$metrics$acc, main="Model 4 (Extra Layer/More Hidden Units/SGD)",
# xlab = "Epoch", ylab="Accuracy", col="blue", type="l", ylim=c(0.65, 0.76))
#
# # Plot the accuracy of the validation data
# lines(track.model.4$metrics$val_acc, col="green")
#
# # Add Legend
# legend("top", c("Training", "Testing"), col=c("blue", "green"), lty=c(1,1))
epochs <- 200
time <- 1:epochs
hist_df4 <- data.frame(time=time, loss=track.model.4$metrics$loss, acc=track.model.4$metrics$acc,
valid_loss=track.model.4$metrics$val_loss, valid_acc=track.model.4$metrics$val_acc)
plot_ly(hist_df4, x = ~time) %>%
add_trace(y = ~loss, name = 'training loss', mode = 'lines') %>%
add_trace(y = ~acc, name = 'training accuracy', mode = 'lines+markers') %>%
add_trace(y = ~valid_loss, name = 'validation loss',mode = 'lines+markers') %>%
add_trace(y = ~valid_acc, name = 'validation accuracy', mode = 'lines+markers') %>%
layout(title="Titanic (model.4) NN Model Performance",
legend = list(orientation = 'h'), yaxis=list(title="metric"))5.11 Model Export and Import
Intermediate and final NN models may be saved, (re)loaded, and
exported using of save_model_hdf5() and
load_model_hdf5() based on the HDF5 file
format (h5). We can operate on complete models on just on
the model weights. the models can also be exported in JSON or YAML formats using
model_to_json() and model_to_yaml(), and their
load counterparts model_from_json() and
model_from yaml().
save_model_hdf5(model.4, "model.4.h5")
model.new <- load_model_hdf5("model.4.h5")
save_model_weights_hdf5("model_weights.h5")
model.old %>% load_model_weights_hdf5("model_weights.h5")
json_string <- model_to_json(model.old)
model.new <- model_from_json(json_string)
yaml_string <- model_to_yaml(model.old)
model.new <- model_from_yaml(yaml_string)Let’s demonstrate loading several pre-trained models, (resnet50), VGG16, VGG19, and using them for simple out-of-the-box image classification and automated labeling of an image of New Zealand’s Lake Mapourika. This image recognition example will be expanded later. For now, we will simply illustrate the quick and efficient utilization of an existing pretrained neural network to qualitatively describe an image in a narative form.
{kind=link}
library(keras)
library(tensorflow)
# get info about local version of Python installation
# reticulate::py_config()
# The first time you run this install Pillow!
# tensorflow::install_tensorflow(extra_packages='pillow')
# load the image
if (!file.exists(paste(getwd(),"results", sep="/"))) {
dir.create(paste(getwd(),"results", sep="/"), recursive = TRUE)
}
download.file("https://upload.wikimedia.org/wikipedia/commons/2/23/Lake_mapourika_NZ.jpeg", paste(getwd(),"results/image.png", sep="/"), mode = 'wb')
img <- image_load(paste(getwd(),"results/image.png", sep="/"), target_size = c(224,224))
# Preprocess input image
x <- image_to_array(img)
# ensure we have a 4d tensor with single element in the batch dimension,
# the preprocess the input for prediction using resnet50
x <- array_reshape(x, c(1, dim(x)))
x <- imagenet_preprocess_input(x)
# Specify and compare Predictions based on different Pre-trained Models
# Model 1: resnet50
model_resnet50 <- application_resnet50(weights = 'imagenet')
# make predictions then decode and print them
preds_resnet50 <- model_resnet50 %>% predict(x)## 1/1 - 1s - 593ms/epoch - 593ms/step## [[1]]
## class_name class_description score
## 1 n09332890 lakeside 0.6543879509
## 2 n02859443 boathouse 0.1122934818
## 3 n03216828 dock 0.0768113956
## 4 n02894605 breakwater 0.0713918880
## 5 n02951358 canoe 0.0646000579
## 6 n03873416 paddle 0.0125367241
## 7 n03160309 dam 0.0042035156
## 8 n09421951 sandbar 0.0010209975
## 9 n02980441 castle 0.0004615768
## 10 n03028079 church 0.0003251515# Model2: VGG19
model_vgg19 <- application_vgg19(weights = 'imagenet')
preds_vgg19 <- model_vgg19 %>% predict(x)## 1/1 - 0s - 179ms/epoch - 179ms/step## class_name class_description score
## 1 n09332890 lakeside 0.7257623076
## 2 n02894605 breakwater 0.2156526744
## 3 n02859443 boathouse 0.0240014996
## 4 n03216828 dock 0.0103707537
## 5 n03160309 dam 0.0092136264
## 6 n02951358 canoe 0.0068325307
## 7 n09421951 sandbar 0.0011575023
## 8 n04592741 wing 0.0009790066
## 9 n02814860 beacon 0.0005801014
## 10 n03873416 paddle 0.0004235524# Model 3: VGG16
model_vgg16 <- application_vgg16(weights = 'imagenet')
preds_vgg16 <- model_vgg16 %>% predict(x)## 1/1 - 0s - 145ms/epoch - 145ms/step## class_name class_description score
## 1 n09332890 lakeside 0.656819403
## 2 n02894605 breakwater 0.201263770
## 3 n03216828 dock 0.062172864
## 4 n02951358 canoe 0.021647597
## 5 n02859443 boathouse 0.016535964
## 6 n03160309 dam 0.014571159
## 7 n03873416 paddle 0.002511310
## 8 n04606251 wreck 0.001823977
## 9 n03874293 paddlewheel 0.001813032
## 10 n09421951 sandbar 0.0017994226 Classification examples
6.1 Sonar data example
Let’s load the mlbench packages which includes a Sonar
data mlbench::Sonar containing information about sonar
signals bouncing off a metal cylinder or a roughly cylindrical rock.
Each of 208 observations includes a set of 60 numbers (features) in the
range 0.0 to 1.0, and a label M (metal) or R (rock). Each feature
represents the energy within a particular frequency band, integrated
over a certain period of time. The M and R labels associated with each
observation classify the record as rock or mine (metal) cylinder. The
numbers in the labels are in increasing order of aspect angle, but they
do not encode the angle directly.
##
## M R
## 111 97Sonar[,61] = as.numeric(Sonar[,61])-1 # R = "1", "M" = "0"
set.seed(123)
train.ind = sample(1:nrow(Sonar),0.7*nrow(Sonar))
train.x = data.matrix(Sonar[train.ind, 1:60])
train.y = Sonar[train.ind, 61]
test.x = data.matrix(Sonar[-train.ind, 1:60])
test.y = Sonar[-train.ind, 61]Let’s start by using a multi-layer perceptron as a classifier using a general multi-layer neural network that can be utilized to do classification or regression modeling. It relies on the following parameters:
- Training data and labels,
- Number of hidden nodes in each hidden layer,
- Number of nodes in the output layer,
- Type of activation,
- Type of output loss.
Here is one example using the training and testing data we defined above:
## [1] 145 60## [1] 63 60model <- keras_model_sequential()
model %>%
layer_dense(units = 256, activation = 'relu', input_shape = ncol(train.x)) %>%
layer_dropout(rate = 0.4) %>%
layer_dense(units = 128, activation = 'relu') %>%
layer_dropout(rate = 0.3) %>%
layer_dense(units = 2, activation = 'sigmoid')
model %>% compile(
loss = 'binary_crossentropy',
optimizer = 'adam',
metrics = c('accuracy')
)
one_hot_labels <- to_categorical(train.y, num_classes = 2)
# Train the model, iterating on the data in batches of 25 samples
history <- model %>% fit(
train.x, one_hot_labels,
epochs = 100,
batch_size = 5,
validation_split = 0.3
)## Epoch 1/100
## 21/21 - 1s - loss: 0.7096 - accuracy: 0.4752 - val_loss: 0.7045 - val_accuracy: 0.4773 - 519ms/epoch - 25ms/step
## Epoch 2/100
## 21/21 - 0s - loss: 0.6654 - accuracy: 0.6040 - val_loss: 0.6617 - val_accuracy: 0.5682 - 49ms/epoch - 2ms/step
## Epoch 3/100
## 21/21 - 0s - loss: 0.6390 - accuracy: 0.5941 - val_loss: 0.6409 - val_accuracy: 0.6136 - 51ms/epoch - 2ms/step
## Epoch 4/100
## 21/21 - 0s - loss: 0.6388 - accuracy: 0.6436 - val_loss: 0.6309 - val_accuracy: 0.6364 - 51ms/epoch - 2ms/step
## Epoch 5/100
## 21/21 - 0s - loss: 0.5780 - accuracy: 0.6634 - val_loss: 0.5938 - val_accuracy: 0.6591 - 47ms/epoch - 2ms/step
## Epoch 6/100
## 21/21 - 0s - loss: 0.5431 - accuracy: 0.7723 - val_loss: 0.5815 - val_accuracy: 0.6818 - 59ms/epoch - 3ms/step
## Epoch 7/100
## 21/21 - 0s - loss: 0.5124 - accuracy: 0.7822 - val_loss: 0.5342 - val_accuracy: 0.7045 - 45ms/epoch - 2ms/step
## Epoch 8/100
## 21/21 - 0s - loss: 0.4979 - accuracy: 0.7327 - val_loss: 0.5040 - val_accuracy: 0.7955 - 47ms/epoch - 2ms/step
## Epoch 9/100
## 21/21 - 0s - loss: 0.4829 - accuracy: 0.7624 - val_loss: 0.5642 - val_accuracy: 0.6818 - 51ms/epoch - 2ms/step
## Epoch 10/100
## 21/21 - 0s - loss: 0.4365 - accuracy: 0.8218 - val_loss: 0.4780 - val_accuracy: 0.7045 - 47ms/epoch - 2ms/step
## Epoch 11/100
## 21/21 - 0s - loss: 0.3798 - accuracy: 0.8416 - val_loss: 0.4539 - val_accuracy: 0.7045 - 47ms/epoch - 2ms/step
## Epoch 12/100
## 21/21 - 0s - loss: 0.3950 - accuracy: 0.8119 - val_loss: 0.5699 - val_accuracy: 0.6591 - 45ms/epoch - 2ms/step
## Epoch 13/100
## 21/21 - 0s - loss: 0.3664 - accuracy: 0.8317 - val_loss: 0.5532 - val_accuracy: 0.6818 - 46ms/epoch - 2ms/step
## Epoch 14/100
## 21/21 - 0s - loss: 0.4342 - accuracy: 0.8218 - val_loss: 0.6226 - val_accuracy: 0.6591 - 46ms/epoch - 2ms/step
## Epoch 15/100
## 21/21 - 0s - loss: 0.3388 - accuracy: 0.8317 - val_loss: 0.4333 - val_accuracy: 0.7955 - 47ms/epoch - 2ms/step
## Epoch 16/100
## 21/21 - 0s - loss: 0.3164 - accuracy: 0.9109 - val_loss: 0.5619 - val_accuracy: 0.6818 - 46ms/epoch - 2ms/step
## Epoch 17/100
## 21/21 - 0s - loss: 0.3101 - accuracy: 0.9010 - val_loss: 0.4345 - val_accuracy: 0.7045 - 50ms/epoch - 2ms/step
## Epoch 18/100
## 21/21 - 0s - loss: 0.2840 - accuracy: 0.9109 - val_loss: 0.8222 - val_accuracy: 0.6364 - 46ms/epoch - 2ms/step
## Epoch 19/100
## 21/21 - 0s - loss: 0.3171 - accuracy: 0.8614 - val_loss: 0.3848 - val_accuracy: 0.8636 - 46ms/epoch - 2ms/step
## Epoch 20/100
## 21/21 - 0s - loss: 0.2961 - accuracy: 0.8812 - val_loss: 0.6148 - val_accuracy: 0.6818 - 49ms/epoch - 2ms/step
## Epoch 21/100
## 21/21 - 0s - loss: 0.3321 - accuracy: 0.8218 - val_loss: 0.5137 - val_accuracy: 0.7045 - 48ms/epoch - 2ms/step
## Epoch 22/100
## 21/21 - 0s - loss: 0.3602 - accuracy: 0.8416 - val_loss: 0.3913 - val_accuracy: 0.8636 - 49ms/epoch - 2ms/step
## Epoch 23/100
## 21/21 - 0s - loss: 0.3106 - accuracy: 0.9010 - val_loss: 0.3900 - val_accuracy: 0.8182 - 47ms/epoch - 2ms/step
## Epoch 24/100
## 21/21 - 0s - loss: 0.2655 - accuracy: 0.8713 - val_loss: 0.3746 - val_accuracy: 0.8409 - 48ms/epoch - 2ms/step
## Epoch 25/100
## 21/21 - 0s - loss: 0.2535 - accuracy: 0.9010 - val_loss: 0.6127 - val_accuracy: 0.6364 - 48ms/epoch - 2ms/step
## Epoch 26/100
## 21/21 - 0s - loss: 0.2556 - accuracy: 0.8812 - val_loss: 0.3687 - val_accuracy: 0.8636 - 45ms/epoch - 2ms/step
## Epoch 27/100
## 21/21 - 0s - loss: 0.2426 - accuracy: 0.8911 - val_loss: 0.4739 - val_accuracy: 0.7727 - 46ms/epoch - 2ms/step
## Epoch 28/100
## 21/21 - 0s - loss: 0.2280 - accuracy: 0.9010 - val_loss: 0.3901 - val_accuracy: 0.8182 - 46ms/epoch - 2ms/step
## Epoch 29/100
## 21/21 - 0s - loss: 0.2196 - accuracy: 0.8911 - val_loss: 0.4510 - val_accuracy: 0.7273 - 47ms/epoch - 2ms/step
## Epoch 30/100
## 21/21 - 0s - loss: 0.2000 - accuracy: 0.9505 - val_loss: 0.3757 - val_accuracy: 0.8182 - 46ms/epoch - 2ms/step
## Epoch 31/100
## 21/21 - 0s - loss: 0.2327 - accuracy: 0.9109 - val_loss: 0.4698 - val_accuracy: 0.7500 - 47ms/epoch - 2ms/step
## Epoch 32/100
## 21/21 - 0s - loss: 0.2389 - accuracy: 0.8713 - val_loss: 0.6130 - val_accuracy: 0.6818 - 46ms/epoch - 2ms/step
## Epoch 33/100
## 21/21 - 0s - loss: 0.2001 - accuracy: 0.9010 - val_loss: 0.4216 - val_accuracy: 0.7500 - 46ms/epoch - 2ms/step
## Epoch 34/100
## 21/21 - 0s - loss: 0.1821 - accuracy: 0.9307 - val_loss: 0.3882 - val_accuracy: 0.7955 - 46ms/epoch - 2ms/step
## Epoch 35/100
## 21/21 - 0s - loss: 0.2128 - accuracy: 0.9010 - val_loss: 0.6772 - val_accuracy: 0.7045 - 46ms/epoch - 2ms/step
## Epoch 36/100
## 21/21 - 0s - loss: 0.1752 - accuracy: 0.9505 - val_loss: 0.3594 - val_accuracy: 0.8182 - 46ms/epoch - 2ms/step
## Epoch 37/100
## 21/21 - 0s - loss: 0.2193 - accuracy: 0.8911 - val_loss: 0.4771 - val_accuracy: 0.7500 - 47ms/epoch - 2ms/step
## Epoch 38/100
## 21/21 - 0s - loss: 0.1970 - accuracy: 0.9208 - val_loss: 0.5597 - val_accuracy: 0.7045 - 46ms/epoch - 2ms/step
## Epoch 39/100
## 21/21 - 0s - loss: 0.1412 - accuracy: 0.9604 - val_loss: 0.3794 - val_accuracy: 0.8636 - 55ms/epoch - 3ms/step
## Epoch 40/100
## 21/21 - 0s - loss: 0.1997 - accuracy: 0.9307 - val_loss: 0.6884 - val_accuracy: 0.6591 - 48ms/epoch - 2ms/step
## Epoch 41/100
## 21/21 - 0s - loss: 0.1684 - accuracy: 0.9208 - val_loss: 0.3543 - val_accuracy: 0.8409 - 45ms/epoch - 2ms/step
## Epoch 42/100
## 21/21 - 0s - loss: 0.1670 - accuracy: 0.9208 - val_loss: 0.6162 - val_accuracy: 0.7045 - 48ms/epoch - 2ms/step
## Epoch 43/100
## 21/21 - 0s - loss: 0.1589 - accuracy: 0.9208 - val_loss: 0.3389 - val_accuracy: 0.8636 - 47ms/epoch - 2ms/step
## Epoch 44/100
## 21/21 - 0s - loss: 0.1391 - accuracy: 0.9604 - val_loss: 0.3287 - val_accuracy: 0.8636 - 46ms/epoch - 2ms/step
## Epoch 45/100
## 21/21 - 0s - loss: 0.2295 - accuracy: 0.8812 - val_loss: 0.4655 - val_accuracy: 0.7273 - 48ms/epoch - 2ms/step
## Epoch 46/100
## 21/21 - 0s - loss: 0.1653 - accuracy: 0.9406 - val_loss: 0.4390 - val_accuracy: 0.7500 - 46ms/epoch - 2ms/step
## Epoch 47/100
## 21/21 - 0s - loss: 0.1432 - accuracy: 0.9307 - val_loss: 0.4376 - val_accuracy: 0.7727 - 47ms/epoch - 2ms/step
## Epoch 48/100
## 21/21 - 0s - loss: 0.1510 - accuracy: 0.9307 - val_loss: 0.5215 - val_accuracy: 0.7500 - 47ms/epoch - 2ms/step
## Epoch 49/100
## 21/21 - 0s - loss: 0.1299 - accuracy: 0.9406 - val_loss: 0.3487 - val_accuracy: 0.8409 - 49ms/epoch - 2ms/step
## Epoch 50/100
## 21/21 - 0s - loss: 0.1436 - accuracy: 0.9406 - val_loss: 0.5215 - val_accuracy: 0.7045 - 47ms/epoch - 2ms/step
## Epoch 51/100
## 21/21 - 0s - loss: 0.1383 - accuracy: 0.9307 - val_loss: 0.4297 - val_accuracy: 0.7955 - 45ms/epoch - 2ms/step
## Epoch 52/100
## 21/21 - 0s - loss: 0.1213 - accuracy: 0.9505 - val_loss: 0.4416 - val_accuracy: 0.7955 - 48ms/epoch - 2ms/step
## Epoch 53/100
## 21/21 - 0s - loss: 0.1146 - accuracy: 0.9604 - val_loss: 0.4266 - val_accuracy: 0.8182 - 47ms/epoch - 2ms/step
## Epoch 54/100
## 21/21 - 0s - loss: 0.0986 - accuracy: 0.9604 - val_loss: 0.5840 - val_accuracy: 0.7045 - 48ms/epoch - 2ms/step
## Epoch 55/100
## 21/21 - 0s - loss: 0.1327 - accuracy: 0.9406 - val_loss: 0.5621 - val_accuracy: 0.7273 - 47ms/epoch - 2ms/step
## Epoch 56/100
## 21/21 - 0s - loss: 0.1002 - accuracy: 0.9802 - val_loss: 0.3321 - val_accuracy: 0.8409 - 66ms/epoch - 3ms/step
## Epoch 57/100
## 21/21 - 0s - loss: 0.0978 - accuracy: 0.9703 - val_loss: 0.6146 - val_accuracy: 0.7273 - 65ms/epoch - 3ms/step
## Epoch 58/100
## 21/21 - 0s - loss: 0.0852 - accuracy: 0.9703 - val_loss: 0.3852 - val_accuracy: 0.8409 - 62ms/epoch - 3ms/step
## Epoch 59/100
## 21/21 - 0s - loss: 0.0888 - accuracy: 0.9703 - val_loss: 0.5612 - val_accuracy: 0.7500 - 70ms/epoch - 3ms/step
## Epoch 60/100
## 21/21 - 0s - loss: 0.0664 - accuracy: 0.9901 - val_loss: 0.6283 - val_accuracy: 0.7727 - 60ms/epoch - 3ms/step
## Epoch 61/100
## 21/21 - 0s - loss: 0.1132 - accuracy: 0.9505 - val_loss: 0.4940 - val_accuracy: 0.7727 - 61ms/epoch - 3ms/step
## Epoch 62/100
## 21/21 - 0s - loss: 0.2138 - accuracy: 0.9208 - val_loss: 0.3142 - val_accuracy: 0.8636 - 62ms/epoch - 3ms/step
## Epoch 63/100
## 21/21 - 0s - loss: 0.1082 - accuracy: 0.9703 - val_loss: 0.5295 - val_accuracy: 0.7727 - 61ms/epoch - 3ms/step
## Epoch 64/100
## 21/21 - 0s - loss: 0.1004 - accuracy: 0.9703 - val_loss: 0.3296 - val_accuracy: 0.8636 - 60ms/epoch - 3ms/step
## Epoch 65/100
## 21/21 - 0s - loss: 0.1006 - accuracy: 0.9703 - val_loss: 0.4196 - val_accuracy: 0.8409 - 59ms/epoch - 3ms/step
## Epoch 66/100
## 21/21 - 0s - loss: 0.0550 - accuracy: 0.9901 - val_loss: 0.5113 - val_accuracy: 0.8182 - 63ms/epoch - 3ms/step
## Epoch 67/100
## 21/21 - 0s - loss: 0.0633 - accuracy: 0.9802 - val_loss: 0.4241 - val_accuracy: 0.8409 - 62ms/epoch - 3ms/step
## Epoch 68/100
## 21/21 - 0s - loss: 0.0618 - accuracy: 0.9901 - val_loss: 0.7083 - val_accuracy: 0.6818 - 64ms/epoch - 3ms/step
## Epoch 69/100
## 21/21 - 0s - loss: 0.0930 - accuracy: 0.9703 - val_loss: 0.5310 - val_accuracy: 0.7955 - 65ms/epoch - 3ms/step
## Epoch 70/100
## 21/21 - 0s - loss: 0.0943 - accuracy: 0.9505 - val_loss: 0.7292 - val_accuracy: 0.7273 - 61ms/epoch - 3ms/step
## Epoch 71/100
## 21/21 - 0s - loss: 0.0767 - accuracy: 0.9703 - val_loss: 0.3117 - val_accuracy: 0.8864 - 59ms/epoch - 3ms/step
## Epoch 72/100
## 21/21 - 0s - loss: 0.1305 - accuracy: 0.9703 - val_loss: 0.4506 - val_accuracy: 0.7955 - 51ms/epoch - 2ms/step
## Epoch 73/100
## 21/21 - 0s - loss: 0.0772 - accuracy: 1.0000 - val_loss: 0.6947 - val_accuracy: 0.7045 - 46ms/epoch - 2ms/step
## Epoch 74/100
## 21/21 - 0s - loss: 0.1061 - accuracy: 0.9604 - val_loss: 0.3935 - val_accuracy: 0.7727 - 46ms/epoch - 2ms/step
## Epoch 75/100
## 21/21 - 0s - loss: 0.1990 - accuracy: 0.9406 - val_loss: 0.3857 - val_accuracy: 0.8409 - 45ms/epoch - 2ms/step
## Epoch 76/100
## 21/21 - 0s - loss: 0.0676 - accuracy: 0.9703 - val_loss: 0.4041 - val_accuracy: 0.8409 - 54ms/epoch - 3ms/step
## Epoch 77/100
## 21/21 - 0s - loss: 0.0658 - accuracy: 0.9703 - val_loss: 0.5249 - val_accuracy: 0.7727 - 46ms/epoch - 2ms/step
## Epoch 78/100
## 21/21 - 0s - loss: 0.0454 - accuracy: 0.9802 - val_loss: 0.5499 - val_accuracy: 0.7955 - 47ms/epoch - 2ms/step
## Epoch 79/100
## 21/21 - 0s - loss: 0.0484 - accuracy: 0.9901 - val_loss: 0.4999 - val_accuracy: 0.8182 - 45ms/epoch - 2ms/step
## Epoch 80/100
## 21/21 - 0s - loss: 0.0403 - accuracy: 0.9901 - val_loss: 0.5856 - val_accuracy: 0.7727 - 46ms/epoch - 2ms/step
## Epoch 81/100
## 21/21 - 0s - loss: 0.0671 - accuracy: 0.9802 - val_loss: 0.4901 - val_accuracy: 0.7955 - 46ms/epoch - 2ms/step
## Epoch 82/100
## 21/21 - 0s - loss: 0.0502 - accuracy: 0.9802 - val_loss: 0.5167 - val_accuracy: 0.7955 - 46ms/epoch - 2ms/step
## Epoch 83/100
## 21/21 - 0s - loss: 0.0476 - accuracy: 0.9901 - val_loss: 0.5405 - val_accuracy: 0.8182 - 46ms/epoch - 2ms/step
## Epoch 84/100
## 21/21 - 0s - loss: 0.0762 - accuracy: 0.9703 - val_loss: 0.8443 - val_accuracy: 0.6818 - 47ms/epoch - 2ms/step
## Epoch 85/100
## 21/21 - 0s - loss: 0.0446 - accuracy: 0.9901 - val_loss: 0.3702 - val_accuracy: 0.8864 - 49ms/epoch - 2ms/step
## Epoch 86/100
## 21/21 - 0s - loss: 0.0452 - accuracy: 0.9802 - val_loss: 0.7421 - val_accuracy: 0.7500 - 47ms/epoch - 2ms/step
## Epoch 87/100
## 21/21 - 0s - loss: 0.0567 - accuracy: 0.9703 - val_loss: 0.4092 - val_accuracy: 0.8864 - 46ms/epoch - 2ms/step
## Epoch 88/100
## 21/21 - 0s - loss: 0.0601 - accuracy: 0.9802 - val_loss: 0.6876 - val_accuracy: 0.7500 - 47ms/epoch - 2ms/step
## Epoch 89/100
## 21/21 - 0s - loss: 0.0442 - accuracy: 0.9802 - val_loss: 0.4647 - val_accuracy: 0.8409 - 47ms/epoch - 2ms/step
## Epoch 90/100
## 21/21 - 0s - loss: 0.0417 - accuracy: 0.9901 - val_loss: 0.4993 - val_accuracy: 0.8182 - 46ms/epoch - 2ms/step
## Epoch 91/100
## 21/21 - 0s - loss: 0.0310 - accuracy: 1.0000 - val_loss: 0.5736 - val_accuracy: 0.8409 - 47ms/epoch - 2ms/step
## Epoch 92/100
## 21/21 - 0s - loss: 0.0260 - accuracy: 1.0000 - val_loss: 0.4793 - val_accuracy: 0.8636 - 47ms/epoch - 2ms/step
## Epoch 93/100
## 21/21 - 0s - loss: 0.0311 - accuracy: 0.9901 - val_loss: 0.4812 - val_accuracy: 0.7955 - 45ms/epoch - 2ms/step
## Epoch 94/100
## 21/21 - 0s - loss: 0.0412 - accuracy: 0.9901 - val_loss: 0.5044 - val_accuracy: 0.8182 - 47ms/epoch - 2ms/step
## Epoch 95/100
## 21/21 - 0s - loss: 0.0592 - accuracy: 0.9703 - val_loss: 0.6229 - val_accuracy: 0.7955 - 48ms/epoch - 2ms/step
## Epoch 96/100
## 21/21 - 0s - loss: 0.0201 - accuracy: 0.9901 - val_loss: 0.5341 - val_accuracy: 0.8182 - 45ms/epoch - 2ms/step
## Epoch 97/100
## 21/21 - 0s - loss: 0.0386 - accuracy: 0.9802 - val_loss: 0.3993 - val_accuracy: 0.7955 - 61ms/epoch - 3ms/step
## Epoch 98/100
## 21/21 - 0s - loss: 0.0440 - accuracy: 0.9901 - val_loss: 0.4557 - val_accuracy: 0.8182 - 51ms/epoch - 2ms/step
## Epoch 99/100
## 21/21 - 0s - loss: 0.0640 - accuracy: 0.9703 - val_loss: 0.7445 - val_accuracy: 0.7727 - 46ms/epoch - 2ms/step
## Epoch 100/100
## 21/21 - 0s - loss: 0.0539 - accuracy: 0.9802 - val_loss: 0.4390 - val_accuracy: 0.8182 - 48ms/epoch - 2ms/step## 2/2 - 0s - loss: 0.8885 - accuracy: 0.7619 - 15ms/epoch - 7ms/step## loss accuracy
## 0.8885291 0.7619048epochs <- 100
time <- 1:epochs
hist_df <- data.frame(time=time, loss=history$metrics$loss, acc=history$metrics$accuracy,
valid_loss=history$metrics$val_loss, valid_acc=history$metrics$val_accuracy)
plot_ly(hist_df, x = ~time) %>%
add_trace(y = ~loss, name = 'training loss', type="scatter", mode = 'lines') %>%
add_trace(y = ~acc, name = 'training accuracy', type="scatter", mode = 'lines+markers') %>%
add_trace(y = ~valid_loss, name = 'validation loss', type="scatter",mode = 'lines+markers') %>%
add_trace(y = ~valid_acc, name = 'validation accuracy', type="scatter", mode = 'lines+markers') %>%
layout(title="Sonar Data NN Model Performance",
legend = list(orientation = 'h'), yaxis=list(title="metric"))# Finally prediction of binary class labels and Confusion Matrix
predictions <- model %>% predict(test.x) %>% k_argmax()## 2/2 - 0s - 36ms/epoch - 18ms/step##
## 0 1
## 0 30 9
## 1 6 18# We can also inspect the corresponding probabilities of the automated binary classification labels
prediction_probabilities <- model %>% predict(test.x)## 2/2 - 0s - 15ms/epoch - 7ms/step## [,1] [,2]
## [1,] 5.708213e-01 4.174415e-01
## [2,] 9.994012e-01 5.770656e-04
## [3,] 2.562191e-01 7.206706e-01
## [4,] 1.677408e-05 9.999818e-01
## [5,] 1.571647e-01 8.306012e-01
## [6,] 6.567127e-01 3.266767e-01
## [7,] 9.730149e-01 2.402785e-02
## [8,] 5.103256e-05 9.999499e-01
## [9,] 9.993746e-01 5.533607e-04
## [10,] 4.155107e-03 9.956214e-01
## [11,] 8.917477e-01 1.001557e-01
## [12,] 1.289995e-02 9.869066e-01
## [13,] 3.590115e-02 9.604644e-01
## [14,] 9.950034e-05 9.998997e-01
## [15,] 7.393596e-01 2.168651e-01
## [16,] 7.864046e-01 2.047392e-01
## [17,] 2.156453e-02 9.764880e-01
## [18,] 9.358757e-01 5.593306e-02
## [19,] 2.017542e-04 9.997709e-01
## [20,] 2.985346e-05 9.999669e-01
## [21,] 1.167627e-04 9.998712e-01
## [22,] 5.656449e-07 9.999993e-01
## [23,] 1.547952e-06 9.999983e-01
## [24,] 1.052646e-04 9.998729e-01
## [25,] 3.675635e-04 9.996369e-01
## [26,] 1.173023e-02 9.870809e-01
## [27,] 1.254599e-02 9.866159e-01
## [28,] 3.104275e-01 6.820272e-01
## [29,] 9.383342e-01 5.971909e-02
## [30,] 3.252724e-01 6.663389e-01
## [31,] 9.018200e-01 9.063973e-02
## [32,] 9.775051e-01 2.021595e-02
## [33,] 9.745535e-01 2.359261e-02
## [34,] 9.921376e-01 7.166964e-03
## [35,] 9.815909e-01 1.676576e-02
## [36,] 9.411597e-01 5.543869e-02
## [37,] 9.372837e-01 5.748381e-02
## [38,] 6.540043e-01 3.307842e-01
## [39,] 6.734979e-01 3.175023e-01
## [40,] 6.491591e-01 3.409265e-01
## [41,] 9.986193e-01 1.230886e-03
## [42,] 9.983345e-01 1.461237e-03
## [43,] 9.998866e-01 1.084723e-04
## [44,] 9.633647e-01 3.236535e-02
## [45,] 9.809143e-01 1.692346e-02
## [46,] 9.999712e-01 2.562275e-05
## [47,] 9.944534e-01 5.024703e-03
## [48,] 7.422960e-03 9.921721e-01
## [49,] 5.567839e-01 4.313883e-01
## [50,] 1.972492e-02 9.804150e-01
## [51,] 9.997365e-01 2.039883e-04
## [52,] 9.978609e-01 1.525584e-03
## [53,] 9.571643e-01 3.313835e-02
## [54,] 9.998717e-01 9.403015e-05
## [55,] 2.222534e-03 9.973775e-01
## [56,] 6.106936e-04 9.993004e-01
## [57,] 9.093056e-01 7.318385e-02
## [58,] 9.998873e-01 9.998980e-05
## [59,] 9.999993e-01 5.540303e-07
## [60,] 9.999984e-01 1.292271e-06
## [61,] 9.999951e-01 3.956951e-06
## [62,] 9.890865e-01 9.370043e-03
## [63,] 9.846837e-01 1.280173e-02Note that you may need to specify
crossval::confusionMatrix(), in case you also have the
caret package loaded, as caret also has a
function called confusionMatrix().
library("crossval")
diagnosticErrors(crossval::confusionMatrix(predictions$numpy(),test.y, negative = 0))## acc sens spec ppv npv lor
## 0.7619048 0.7500000 0.7692308 0.6666667 0.8333333 2.3025851
## attr(,"negative")
## [1] 0We can plot the ROC curve and calculate the AUC (Area under the curve). Specifically, we will show computing the area under the curve (AUC) and drawing the receiver operating characteristic (ROC) curve. Assuming ‘positive’ ranks higher than ‘negative’, the AUC quantifies the probability that a classifier will rank a randomly chosen positive instance higher than a randomly chosen negative instance. For binary classification, interpreting the AUC values, \(0\leq AUC\leq 1\), corresponds with (poor) uninformative classifiers when \(AUC=0.5\) and perfect classifiers when \(AUC\to 1^-\).
# install.packages("pROC"); install.packages("plotROC"); install.packages("reshape2")
library(pROC); library(plotROC); library(reshape2); ## Type 'citation("pROC")' for a citation.##
## Attaching package: 'pROC'## The following objects are masked from 'package:stats':
##
## cov, smooth, var##
## Attaching package: 'plotROC'## The following object is masked from 'package:pROC':
##
## ggroc# compute AUC
get_roc = function(preds){
roc_obj <- roc(test.y, preds, quiet=TRUE)
auc(roc_obj)
}
get_roc(predictions$numpy())## Area under the curve: 0.75predictions <- predictions$numpy()
#plot roc
dt <- data.frame(test.y, predictions)
colnames(dt) <- c("class","scored.probability")
# basicplot <- ggplot(dt, aes(d = class, m = scored.probability)) +
# geom_roc(labels = FALSE, size = 0.5, alpha.line = 0.6, linejoin = "mitre") +
# theme_bw() + coord_fixed(ratio = 1) + style_roc() + ggtitle("ROC CURVE")+
# ggplot2::annotate("rect", xmin = 0.4, xmax = 0.9, ymin = 0.1, ymax = 0.5,
# alpha = 0.2)+
# ggplot2::annotate("text", x = 0.65, y = 0.32, size = 3,
# label = paste0("AUC: ", round(get_roc(predictions)[[1]], 3)))
# basicplot
# Compute the AUC and draw the ROC curve
roc_curve <- function(df) {
x <- c()
y <- c()
true_class = df[, "class"]
probabilities = df[, "scored.probability"]
thresholds = seq(0, 1, 0.01)
rx <- 0
ry <- 0
for (threshold in thresholds) {
predicted_class <- c()
for (val in probabilities) {
if (val > threshold) {
predicted_class <- c(predicted_class, 1)
}
else { predicted_class <- c(predicted_class, 0) }
}
df2 <- as.data.frame(cbind(true_class, predicted_class))
TP <- nrow(filter(df2, true_class == 1 & predicted_class == 1))
TN <- nrow(filter(df2, true_class == 0 & predicted_class == 0))
FP <- nrow(filter(df2, true_class == 0 & predicted_class == 1))
FN <- nrow(filter(df2, true_class == 1 & predicted_class == 0))
specm1 <- 1 - ((TN) / (TN + FP))
sens <- (TP) / (TP + FN)
x <- append(x, specm1)
y <- append(y, sens)
}
dfr <- as.data.frame(cbind(x, y))
plot_ly(dfr, x = ~ x, y = ~ y, type = 'scatter', mode = 'lines') %>%
layout(title = paste0("ROC Curve and AUC"), annotations = list(
text = paste0("Area Under Curve = ", round(get_roc(predictions)[[1]], 3)),
x = 0.75, y = 0.25, showarrow = FALSE),
xaxis = list(showgrid = FALSE, title = "1-Specificity (false positive rate)"),
yaxis = list(showgrid = FALSE, title = "Sensitivity (true positive rate)"),
legend = list(orientation = 'h')
)
}
roc_curve(data.frame(class=test.y, scored.probability=prediction_probabilities[,2]))7 Case-Studies
Let’s demonstrate deep neural network regression-modeling and classification-prediction using several biomedical case-studies.
7.1 Schizophrenia Neuroimaging Study
The SOCR Schizo Dataset is available here.
library("XML"); library("xml2")
library("rvest");
# Schizophrenia Data
# UCLA Data is available here:
# wiki_url <- read_html("http://wiki.stat.ucla.edu/socr/index.php/SOCR_Data_Oct2009_ID_NI")
# html_nodes(wiki_url, "#content")
# SchizoData<- html_table(html_nodes(wiki_url, "table")[[2]])
# UMich Data is available here
wiki_url <- read_html("https://wiki.socr.umich.edu/index.php/SOCR_Data_Oct2009_ID_NI")
html_nodes(wiki_url, "#content")## {xml_nodeset (1)}
## [1] <div id="content" class="mw-body" role="main">\n\t\t\t<a id="top"></a>\n\ ...SchizoData<- html_table(html_nodes(wiki_url, "table")[[1]])
# View (SchizoData): Select an outcome response "DX"(3), "FS_IQ" (5)
set.seed(1234)
test.ind = sample(1:63, 10, replace = F) # select 10/63 of cases for testing, train on remaining (63-10)/63 cases
train.x = scale(data.matrix(SchizoData[-test.ind, c(2, 4:9)])) #, 11:66)]) # exclude outcome
train.y = ifelse(SchizoData[-test.ind, 3] < 2, 0, 1) # Binarize the outcome, Controls=0
test.x = scale(data.matrix(SchizoData[test.ind, c(2, 4:9)])) #, 11:66)])
test.y = ifelse(SchizoData[test.ind, 3] < 2, 0, 1)
# View(data.frame(test.x, test.y))
# View(data.frame(train.x, train.y))
model <- keras_model_sequential()
model %>%
layer_dense(units = 256, activation = 'relu', input_shape = ncol(train.x)) %>%
layer_dropout(rate = 0.4) %>%
layer_dense(units = 128, activation = 'relu') %>%
layer_dropout(rate = 0.3) %>%
layer_dense(units = 64, activation = 'relu') %>%
layer_dropout(rate = 0.1) %>%
layer_dense(units = 32, activation = 'relu') %>%
layer_dropout(rate = 0.1) %>%
layer_dense(units = 2, activation = 'sigmoid')
model %>% compile(
loss = 'binary_crossentropy',
optimizer = 'adam',
metrics = c('accuracy')
)
one_hot_labels <- to_categorical(train.y[,1])
# Train the model, iterating on the data in batches of 25 samples
history <- model %>% fit(
train.x, one_hot_labels,
epochs = 100,
batch_size = 5,
validation_split = 0.1
)## Epoch 1/100
## 10/10 - 1s - loss: 0.6927 - accuracy: 0.5106 - val_loss: 0.7358 - val_accuracy: 0.1667 - 670ms/epoch - 67ms/step
## Epoch 2/100
## 10/10 - 0s - loss: 0.6411 - accuracy: 0.6809 - val_loss: 0.7490 - val_accuracy: 0.1667 - 34ms/epoch - 3ms/step
## Epoch 3/100
## 10/10 - 0s - loss: 0.6017 - accuracy: 0.6383 - val_loss: 0.7306 - val_accuracy: 0.3333 - 33ms/epoch - 3ms/step
## Epoch 4/100
## 10/10 - 0s - loss: 0.5754 - accuracy: 0.7234 - val_loss: 0.7256 - val_accuracy: 0.3333 - 34ms/epoch - 3ms/step
## Epoch 5/100
## 10/10 - 0s - loss: 0.5260 - accuracy: 0.7872 - val_loss: 0.6804 - val_accuracy: 0.6667 - 33ms/epoch - 3ms/step
## Epoch 6/100
## 10/10 - 0s - loss: 0.4753 - accuracy: 0.8298 - val_loss: 0.5958 - val_accuracy: 0.6667 - 34ms/epoch - 3ms/step
## Epoch 7/100
## 10/10 - 0s - loss: 0.4072 - accuracy: 0.8298 - val_loss: 0.4915 - val_accuracy: 0.6667 - 34ms/epoch - 3ms/step
## Epoch 8/100
## 10/10 - 0s - loss: 0.3790 - accuracy: 0.8511 - val_loss: 0.5328 - val_accuracy: 0.6667 - 34ms/epoch - 3ms/step
## Epoch 9/100
## 10/10 - 0s - loss: 0.2887 - accuracy: 0.9362 - val_loss: 0.4832 - val_accuracy: 0.6667 - 33ms/epoch - 3ms/step
## Epoch 10/100
## 10/10 - 0s - loss: 0.3559 - accuracy: 0.8511 - val_loss: 0.4573 - val_accuracy: 0.6667 - 35ms/epoch - 3ms/step
## Epoch 11/100
## 10/10 - 0s - loss: 0.2222 - accuracy: 0.9149 - val_loss: 0.6622 - val_accuracy: 0.5000 - 33ms/epoch - 3ms/step
## Epoch 12/100
## 10/10 - 0s - loss: 0.2884 - accuracy: 0.9149 - val_loss: 0.7009 - val_accuracy: 0.5000 - 34ms/epoch - 3ms/step
## Epoch 13/100
## 10/10 - 0s - loss: 0.2420 - accuracy: 0.9149 - val_loss: 0.5666 - val_accuracy: 0.6667 - 35ms/epoch - 3ms/step
## Epoch 14/100
## 10/10 - 0s - loss: 0.1372 - accuracy: 0.9574 - val_loss: 0.5959 - val_accuracy: 0.6667 - 33ms/epoch - 3ms/step
## Epoch 15/100
## 10/10 - 0s - loss: 0.1545 - accuracy: 0.9574 - val_loss: 0.5605 - val_accuracy: 0.6667 - 32ms/epoch - 3ms/step
## Epoch 16/100
## 10/10 - 0s - loss: 0.2840 - accuracy: 0.8723 - val_loss: 0.7225 - val_accuracy: 0.6667 - 33ms/epoch - 3ms/step
## Epoch 17/100
## 10/10 - 0s - loss: 0.2683 - accuracy: 0.9149 - val_loss: 0.5565 - val_accuracy: 0.6667 - 32ms/epoch - 3ms/step
## Epoch 18/100
## 10/10 - 0s - loss: 0.1605 - accuracy: 0.9574 - val_loss: 0.6485 - val_accuracy: 0.6667 - 32ms/epoch - 3ms/step
## Epoch 19/100
## 10/10 - 0s - loss: 0.1893 - accuracy: 0.9574 - val_loss: 0.7182 - val_accuracy: 0.6667 - 35ms/epoch - 3ms/step
## Epoch 20/100
## 10/10 - 0s - loss: 0.1678 - accuracy: 0.9362 - val_loss: 0.6644 - val_accuracy: 0.6667 - 32ms/epoch - 3ms/step
## Epoch 21/100
## 10/10 - 0s - loss: 0.1273 - accuracy: 0.9787 - val_loss: 0.6309 - val_accuracy: 0.6667 - 32ms/epoch - 3ms/step
## Epoch 22/100
## 10/10 - 0s - loss: 0.1648 - accuracy: 0.9574 - val_loss: 0.7860 - val_accuracy: 0.6667 - 34ms/epoch - 3ms/step
## Epoch 23/100
## 10/10 - 0s - loss: 0.1073 - accuracy: 0.9787 - val_loss: 0.7300 - val_accuracy: 0.6667 - 33ms/epoch - 3ms/step
## Epoch 24/100
## 10/10 - 0s - loss: 0.1049 - accuracy: 0.9574 - val_loss: 0.7912 - val_accuracy: 0.6667 - 31ms/epoch - 3ms/step
## Epoch 25/100
## 10/10 - 0s - loss: 0.0927 - accuracy: 0.9574 - val_loss: 0.8075 - val_accuracy: 0.6667 - 32ms/epoch - 3ms/step
## Epoch 26/100
## 10/10 - 0s - loss: 0.1339 - accuracy: 0.9362 - val_loss: 0.6061 - val_accuracy: 0.8333 - 33ms/epoch - 3ms/step
## Epoch 27/100
## 10/10 - 0s - loss: 0.1391 - accuracy: 0.9149 - val_loss: 0.4026 - val_accuracy: 0.8333 - 33ms/epoch - 3ms/step
## Epoch 28/100
## 10/10 - 0s - loss: 0.0858 - accuracy: 0.9574 - val_loss: 0.8236 - val_accuracy: 0.6667 - 32ms/epoch - 3ms/step
## Epoch 29/100
## 10/10 - 0s - loss: 0.1271 - accuracy: 0.9574 - val_loss: 1.0681 - val_accuracy: 0.6667 - 33ms/epoch - 3ms/step
## Epoch 30/100
## 10/10 - 0s - loss: 0.0885 - accuracy: 0.9574 - val_loss: 1.2823 - val_accuracy: 0.6667 - 32ms/epoch - 3ms/step
## Epoch 31/100
## 10/10 - 0s - loss: 0.0997 - accuracy: 0.9362 - val_loss: 1.1215 - val_accuracy: 0.6667 - 33ms/epoch - 3ms/step
## Epoch 32/100
## 10/10 - 0s - loss: 0.1047 - accuracy: 0.9574 - val_loss: 1.1813 - val_accuracy: 0.6667 - 32ms/epoch - 3ms/step
## Epoch 33/100
## 10/10 - 0s - loss: 0.0569 - accuracy: 0.9787 - val_loss: 1.1981 - val_accuracy: 0.6667 - 37ms/epoch - 4ms/step
## Epoch 34/100
## 10/10 - 0s - loss: 0.0981 - accuracy: 0.9574 - val_loss: 1.0689 - val_accuracy: 0.6667 - 39ms/epoch - 4ms/step
## Epoch 35/100
## 10/10 - 0s - loss: 0.0923 - accuracy: 0.9787 - val_loss: 0.9469 - val_accuracy: 0.6667 - 37ms/epoch - 4ms/step
## Epoch 36/100
## 10/10 - 0s - loss: 0.0832 - accuracy: 0.9574 - val_loss: 0.9109 - val_accuracy: 0.6667 - 34ms/epoch - 3ms/step
## Epoch 37/100
## 10/10 - 0s - loss: 0.0456 - accuracy: 0.9787 - val_loss: 1.0111 - val_accuracy: 0.6667 - 32ms/epoch - 3ms/step
## Epoch 38/100
## 10/10 - 0s - loss: 0.0878 - accuracy: 0.9574 - val_loss: 1.0486 - val_accuracy: 0.6667 - 35ms/epoch - 3ms/step
## Epoch 39/100
## 10/10 - 0s - loss: 0.0512 - accuracy: 0.9787 - val_loss: 0.7471 - val_accuracy: 0.6667 - 32ms/epoch - 3ms/step
## Epoch 40/100
## 10/10 - 0s - loss: 0.0964 - accuracy: 0.9149 - val_loss: 0.9936 - val_accuracy: 0.6667 - 35ms/epoch - 3ms/step
## Epoch 41/100
## 10/10 - 0s - loss: 0.0534 - accuracy: 0.9574 - val_loss: 1.1936 - val_accuracy: 0.6667 - 32ms/epoch - 3ms/step
## Epoch 42/100
## 10/10 - 0s - loss: 0.0396 - accuracy: 0.9787 - val_loss: 1.0424 - val_accuracy: 0.6667 - 33ms/epoch - 3ms/step
## Epoch 43/100
## 10/10 - 0s - loss: 0.0337 - accuracy: 0.9787 - val_loss: 1.0710 - val_accuracy: 0.6667 - 34ms/epoch - 3ms/step
## Epoch 44/100
## 10/10 - 0s - loss: 0.0571 - accuracy: 0.9574 - val_loss: 1.2002 - val_accuracy: 0.6667 - 32ms/epoch - 3ms/step
## Epoch 45/100
## 10/10 - 0s - loss: 0.0299 - accuracy: 1.0000 - val_loss: 1.2681 - val_accuracy: 0.6667 - 32ms/epoch - 3ms/step
## Epoch 46/100
## 10/10 - 0s - loss: 0.0907 - accuracy: 0.9787 - val_loss: 1.1502 - val_accuracy: 0.6667 - 35ms/epoch - 3ms/step
## Epoch 47/100
## 10/10 - 0s - loss: 0.0233 - accuracy: 1.0000 - val_loss: 1.1045 - val_accuracy: 0.6667 - 33ms/epoch - 3ms/step
## Epoch 48/100
## 10/10 - 0s - loss: 0.0909 - accuracy: 0.9574 - val_loss: 1.0070 - val_accuracy: 0.6667 - 32ms/epoch - 3ms/step
## Epoch 49/100
## 10/10 - 0s - loss: 0.0238 - accuracy: 0.9787 - val_loss: 1.1664 - val_accuracy: 0.6667 - 36ms/epoch - 4ms/step
## Epoch 50/100
## 10/10 - 0s - loss: 0.0712 - accuracy: 0.9787 - val_loss: 1.7014 - val_accuracy: 0.6667 - 33ms/epoch - 3ms/step
## Epoch 51/100
## 10/10 - 0s - loss: 0.0889 - accuracy: 0.9574 - val_loss: 1.0001 - val_accuracy: 0.6667 - 33ms/epoch - 3ms/step
## Epoch 52/100
## 10/10 - 0s - loss: 0.0624 - accuracy: 0.9574 - val_loss: 1.1848 - val_accuracy: 0.6667 - 32ms/epoch - 3ms/step
## Epoch 53/100
## 10/10 - 0s - loss: 0.0475 - accuracy: 0.9787 - val_loss: 0.8279 - val_accuracy: 0.6667 - 32ms/epoch - 3ms/step
## Epoch 54/100
## 10/10 - 0s - loss: 0.0912 - accuracy: 0.9574 - val_loss: 0.1000 - val_accuracy: 1.0000 - 33ms/epoch - 3ms/step
## Epoch 55/100
## 10/10 - 0s - loss: 0.0628 - accuracy: 0.9787 - val_loss: 0.1250 - val_accuracy: 1.0000 - 33ms/epoch - 3ms/step
## Epoch 56/100
## 10/10 - 0s - loss: 0.0678 - accuracy: 0.9787 - val_loss: 2.4853 - val_accuracy: 0.6667 - 32ms/epoch - 3ms/step
## Epoch 57/100
## 10/10 - 0s - loss: 0.0655 - accuracy: 0.9574 - val_loss: 2.9881 - val_accuracy: 0.6667 - 32ms/epoch - 3ms/step
## Epoch 58/100
## 10/10 - 0s - loss: 0.0194 - accuracy: 1.0000 - val_loss: 2.6739 - val_accuracy: 0.6667 - 33ms/epoch - 3ms/step
## Epoch 59/100
## 10/10 - 0s - loss: 0.0714 - accuracy: 0.9574 - val_loss: 2.2933 - val_accuracy: 0.6667 - 33ms/epoch - 3ms/step
## Epoch 60/100
## 10/10 - 0s - loss: 0.0683 - accuracy: 0.9574 - val_loss: 2.4591 - val_accuracy: 0.6667 - 33ms/epoch - 3ms/step
## Epoch 61/100
## 10/10 - 0s - loss: 0.0477 - accuracy: 0.9787 - val_loss: 2.5077 - val_accuracy: 0.6667 - 33ms/epoch - 3ms/step
## Epoch 62/100
## 10/10 - 0s - loss: 0.1013 - accuracy: 0.9574 - val_loss: 0.3503 - val_accuracy: 0.8333 - 34ms/epoch - 3ms/step
## Epoch 63/100
## 10/10 - 0s - loss: 0.0359 - accuracy: 0.9787 - val_loss: 0.1411 - val_accuracy: 0.8333 - 32ms/epoch - 3ms/step
## Epoch 64/100
## 10/10 - 0s - loss: 0.0324 - accuracy: 1.0000 - val_loss: 0.4545 - val_accuracy: 0.8333 - 32ms/epoch - 3ms/step
## Epoch 65/100
## 10/10 - 0s - loss: 0.0302 - accuracy: 0.9787 - val_loss: 0.6468 - val_accuracy: 0.8333 - 31ms/epoch - 3ms/step
## Epoch 66/100
## 10/10 - 0s - loss: 0.1040 - accuracy: 0.9362 - val_loss: 1.0445 - val_accuracy: 0.8333 - 31ms/epoch - 3ms/step
## Epoch 67/100
## 10/10 - 0s - loss: 0.0380 - accuracy: 0.9787 - val_loss: 1.1797 - val_accuracy: 0.8333 - 31ms/epoch - 3ms/step
## Epoch 68/100
## 10/10 - 0s - loss: 0.0161 - accuracy: 1.0000 - val_loss: 1.2633 - val_accuracy: 0.8333 - 31ms/epoch - 3ms/step
## Epoch 69/100
## 10/10 - 0s - loss: 0.0467 - accuracy: 0.9787 - val_loss: 1.1842 - val_accuracy: 0.8333 - 35ms/epoch - 3ms/step
## Epoch 70/100
## 10/10 - 0s - loss: 0.0541 - accuracy: 0.9574 - val_loss: 1.1312 - val_accuracy: 0.8333 - 32ms/epoch - 3ms/step
## Epoch 71/100
## 10/10 - 0s - loss: 0.0399 - accuracy: 0.9787 - val_loss: 1.0636 - val_accuracy: 0.8333 - 33ms/epoch - 3ms/step
## Epoch 72/100
## 10/10 - 0s - loss: 0.0337 - accuracy: 0.9787 - val_loss: 0.9871 - val_accuracy: 0.8333 - 35ms/epoch - 3ms/step
## Epoch 73/100
## 10/10 - 0s - loss: 0.0444 - accuracy: 0.9787 - val_loss: 1.0448 - val_accuracy: 0.8333 - 33ms/epoch - 3ms/step
## Epoch 74/100
## 10/10 - 0s - loss: 0.0539 - accuracy: 0.9574 - val_loss: 0.6615 - val_accuracy: 0.8333 - 33ms/epoch - 3ms/step
## Epoch 75/100
## 10/10 - 0s - loss: 0.0059 - accuracy: 1.0000 - val_loss: 0.5219 - val_accuracy: 0.8333 - 34ms/epoch - 3ms/step
## Epoch 76/100
## 10/10 - 0s - loss: 0.0962 - accuracy: 0.9787 - val_loss: 1.0152 - val_accuracy: 0.8333 - 33ms/epoch - 3ms/step
## Epoch 77/100
## 10/10 - 0s - loss: 0.0062 - accuracy: 1.0000 - val_loss: 1.1250 - val_accuracy: 0.8333 - 34ms/epoch - 3ms/step
## Epoch 78/100
## 10/10 - 0s - loss: 0.0177 - accuracy: 1.0000 - val_loss: 1.1419 - val_accuracy: 0.8333 - 33ms/epoch - 3ms/step
## Epoch 79/100
## 10/10 - 0s - loss: 0.0108 - accuracy: 1.0000 - val_loss: 1.0840 - val_accuracy: 0.8333 - 40ms/epoch - 4ms/step
## Epoch 80/100
## 10/10 - 0s - loss: 0.0170 - accuracy: 1.0000 - val_loss: 1.0274 - val_accuracy: 0.8333 - 32ms/epoch - 3ms/step
## Epoch 81/100
## 10/10 - 0s - loss: 0.0290 - accuracy: 0.9787 - val_loss: 0.9772 - val_accuracy: 0.8333 - 32ms/epoch - 3ms/step
## Epoch 82/100
## 10/10 - 0s - loss: 0.0400 - accuracy: 0.9787 - val_loss: 0.9306 - val_accuracy: 0.8333 - 34ms/epoch - 3ms/step
## Epoch 83/100
## 10/10 - 0s - loss: 0.0045 - accuracy: 1.0000 - val_loss: 0.9213 - val_accuracy: 0.8333 - 32ms/epoch - 3ms/step
## Epoch 84/100
## 10/10 - 0s - loss: 0.0087 - accuracy: 1.0000 - val_loss: 0.8675 - val_accuracy: 0.8333 - 33ms/epoch - 3ms/step
## Epoch 85/100
## 10/10 - 0s - loss: 0.0294 - accuracy: 0.9787 - val_loss: 0.8558 - val_accuracy: 0.8333 - 33ms/epoch - 3ms/step
## Epoch 86/100
## 10/10 - 0s - loss: 0.0140 - accuracy: 1.0000 - val_loss: 0.7559 - val_accuracy: 0.8333 - 32ms/epoch - 3ms/step
## Epoch 87/100
## 10/10 - 0s - loss: 0.0249 - accuracy: 1.0000 - val_loss: 0.6834 - val_accuracy: 0.8333 - 30ms/epoch - 3ms/step
## Epoch 88/100
## 10/10 - 0s - loss: 0.0255 - accuracy: 0.9787 - val_loss: 1.5780 - val_accuracy: 0.8333 - 32ms/epoch - 3ms/step
## Epoch 89/100
## 10/10 - 0s - loss: 0.0080 - accuracy: 1.0000 - val_loss: 1.7661 - val_accuracy: 0.8333 - 32ms/epoch - 3ms/step
## Epoch 90/100
## 10/10 - 0s - loss: 0.0217 - accuracy: 0.9787 - val_loss: 1.7724 - val_accuracy: 0.8333 - 31ms/epoch - 3ms/step
## Epoch 91/100
## 10/10 - 0s - loss: 0.0030 - accuracy: 1.0000 - val_loss: 1.6213 - val_accuracy: 0.8333 - 32ms/epoch - 3ms/step
## Epoch 92/100
## 10/10 - 0s - loss: 0.0127 - accuracy: 1.0000 - val_loss: 1.5605 - val_accuracy: 0.8333 - 32ms/epoch - 3ms/step
## Epoch 93/100
## 10/10 - 0s - loss: 0.0219 - accuracy: 0.9787 - val_loss: 1.5205 - val_accuracy: 0.8333 - 32ms/epoch - 3ms/step
## Epoch 94/100
## 10/10 - 0s - loss: 0.0608 - accuracy: 0.9574 - val_loss: 1.5350 - val_accuracy: 0.8333 - 33ms/epoch - 3ms/step
## Epoch 95/100
## 10/10 - 0s - loss: 0.0790 - accuracy: 0.9574 - val_loss: 1.5877 - val_accuracy: 0.8333 - 33ms/epoch - 3ms/step
## Epoch 96/100
## 10/10 - 0s - loss: 0.0834 - accuracy: 0.9574 - val_loss: 1.5244 - val_accuracy: 0.8333 - 32ms/epoch - 3ms/step
## Epoch 97/100
## 10/10 - 0s - loss: 0.0082 - accuracy: 1.0000 - val_loss: 1.1799 - val_accuracy: 0.8333 - 31ms/epoch - 3ms/step
## Epoch 98/100
## 10/10 - 0s - loss: 0.0193 - accuracy: 1.0000 - val_loss: 0.9656 - val_accuracy: 0.8333 - 33ms/epoch - 3ms/step
## Epoch 99/100
## 10/10 - 0s - loss: 0.0070 - accuracy: 1.0000 - val_loss: 0.8162 - val_accuracy: 0.8333 - 33ms/epoch - 3ms/step
## Epoch 100/100
## 10/10 - 0s - loss: 0.0263 - accuracy: 0.9787 - val_loss: 1.0017 - val_accuracy: 0.8333 - 185ms/epoch - 19ms/step## 1/1 - 0s - loss: 1.7572 - accuracy: 0.8000 - 15ms/epoch - 15ms/step## loss accuracy
## 1.757172 0.800000
epochs <- 100
time <- 1:epochs
hist_df <- data.frame(time=time, loss=history$metrics$loss, acc=history$metrics$accuracy,
valid_loss=history$metrics$val_loss, valid_acc=history$metrics$val_accuracy)
plot_ly(hist_df, x = ~time) %>%
add_trace(y = ~loss, name = 'training loss', type="scatter", mode = 'lines') %>%
add_trace(y = ~acc, name = 'training accuracy', type="scatter", mode = 'lines+markers') %>%
add_trace(y = ~valid_loss, name = 'validation loss', type="scatter",mode = 'lines+markers') %>%
add_trace(y = ~valid_acc, name = 'validation accuracy', type="scatter", mode = 'lines+markers') %>%
layout(title="Schizophrenia Study NN Model Performance",
legend = list(orientation = 'h'), yaxis=list(title="metric"))# Finally prediction of binary class labels and Confusion Matrix
predictions <- model %>% predict(test.x) %>% k_argmax()## 1/1 - 0s - 42ms/epoch - 42ms/step# We can also inspect the corresponding probabilities of the automated binary classification labels
# prediction_probabilities <- model %>% predict(test.x) %>% `>`(0.5) %>% k_cast("int32")
# prediction_probabilities$numpy()
prediction_probabilities <- model %>% predict(test.x)## 1/1 - 0s - 13ms/epoch - 13ms/step## [,1] [,2]
## [1,] 7.493485e-05 9.998537e-01
## [2,] 1.000000e+00 6.397688e-10
## [3,] 9.997872e-01 2.378268e-04
## [4,] 1.000000e+00 2.399321e-17
## [5,] 2.347544e-07 9.999990e-01
## [6,] 1.412127e-03 9.971300e-01
## [7,] 1.011244e-03 9.984629e-01
## [8,] 9.999916e-01 1.313227e-05
## [9,] 9.961121e-01 4.962111e-03
## [10,] 2.721610e-06 9.999926e-01##
## 0 1
## 0 4 1
## 1 1 4To get a visual representation of the deep learning network we can display the computation graph (this code is suppressed).
7.2 ALS regression example
The second example demonstrates a deep learning regression using the
ALS
data to predict ALSFRS_slope. Note that in this case
the clinical feature we are predicting, \(Y=ALSFRS_{slope}\) (ALS functional rating
scale progression over time), is a continuous outcome. Hence, we have a
regression problem, which requires a different
keras network formulation from the categorical or
binary classification problem above.
In general, normalizing all data features ensures the model is scale-
and range-invariant. Feature normalization may not be always necessary,
but it helps with improving the network training and ensures the
resulting network prediction is more robust. The function
tfdatasets::feature_spec() provides tensorflow data
normalization for tabular data.
library(tfdatasets)
als <- read.csv("https://umich.instructure.com/files/1789624/download?download_frd=1")
ALSFRS_slope <- als[,7]
als <- as.data.frame(als[,-c(1,7,94)])
colnames(als)## [1] "Age_mean" "Albumin_max"
## [3] "Albumin_median" "Albumin_min"
## [5] "Albumin_range" "ALSFRS_Total_max"
## [7] "ALSFRS_Total_median" "ALSFRS_Total_min"
## [9] "ALSFRS_Total_range" "ALT.SGPT._max"
## [11] "ALT.SGPT._median" "ALT.SGPT._min"
## [13] "ALT.SGPT._range" "AST.SGOT._max"
## [15] "AST.SGOT._median" "AST.SGOT._min"
## [17] "AST.SGOT._range" "Bicarbonate_max"
## [19] "Bicarbonate_median" "Bicarbonate_min"
## [21] "Bicarbonate_range" "Blood.Urea.Nitrogen..BUN._max"
## [23] "Blood.Urea.Nitrogen..BUN._median" "Blood.Urea.Nitrogen..BUN._min"
## [25] "Blood.Urea.Nitrogen..BUN._range" "bp_diastolic_max"
## [27] "bp_diastolic_median" "bp_diastolic_min"
## [29] "bp_diastolic_range" "bp_systolic_max"
## [31] "bp_systolic_median" "bp_systolic_min"
## [33] "bp_systolic_range" "Calcium_max"
## [35] "Calcium_median" "Calcium_min"
## [37] "Calcium_range" "Chloride_max"
## [39] "Chloride_median" "Chloride_min"
## [41] "Chloride_range" "Creatinine_max"
## [43] "Creatinine_median" "Creatinine_min"
## [45] "Creatinine_range" "Gender_mean"
## [47] "Glucose_max" "Glucose_median"
## [49] "Glucose_min" "Glucose_range"
## [51] "hands_max" "hands_median"
## [53] "hands_min" "hands_range"
## [55] "Hematocrit_max" "Hematocrit_median"
## [57] "Hematocrit_min" "Hematocrit_range"
## [59] "Hemoglobin_max" "Hemoglobin_median"
## [61] "Hemoglobin_min" "Hemoglobin_range"
## [63] "leg_max" "leg_median"
## [65] "leg_min" "leg_range"
## [67] "mouth_max" "mouth_median"
## [69] "mouth_min" "mouth_range"
## [71] "onset_delta_mean" "onset_site_mean"
## [73] "Platelets_max" "Platelets_median"
## [75] "Platelets_min" "Potassium_max"
## [77] "Potassium_median" "Potassium_min"
## [79] "Potassium_range" "pulse_max"
## [81] "pulse_median" "pulse_min"
## [83] "pulse_range" "respiratory_max"
## [85] "respiratory_median" "respiratory_min"
## [87] "respiratory_range" "Sodium_max"
## [89] "Sodium_median" "Sodium_min"
## [91] "Sodium_range" "trunk_max"
## [93] "trunk_median" "trunk_min"
## [95] "trunk_range" "Urine.Ph_max"
## [97] "Urine.Ph_median" "Urine.Ph_min"spec <- feature_spec(als, ALSFRS_slope ~ . ) %>%
step_numeric_column(all_numeric(), normalizer_fn = scaler_standard()) %>%
fit()
spec## ── Feature Spec ────────────────────────────────────────────────────────────────
## A feature_spec with 98 steps.
## Fitted: TRUE
## ── Steps ───────────────────────────────────────────────────────────────────────
## The feature_spec has 1 dense features.
## StepNumericColumn: Age_mean, Albumin_max, Albumin_median, Albumin_min, Albumin_range, ALSFRS_Total_max, ALSFRS_Total_median, ALSFRS_Total_min, ALSFRS_Total_range, ALT.SGPT._max, ALT.SGPT._median, ALT.SGPT._min, ALT.SGPT._range, AST.SGOT._max, AST.SGOT._median, AST.SGOT._min, AST.SGOT._range, Bicarbonate_max, Bicarbonate_median, Bicarbonate_min, Bicarbonate_range, Blood.Urea.Nitrogen..BUN._max, Blood.Urea.Nitrogen..BUN._median, Blood.Urea.Nitrogen..BUN._min, Blood.Urea.Nitrogen..BUN._range, bp_diastolic_max, bp_diastolic_median, bp_diastolic_min, bp_diastolic_range, bp_systolic_max, bp_systolic_median, bp_systolic_min, bp_systolic_range, Calcium_max, Calcium_median, Calcium_min, Calcium_range, Chloride_max, Chloride_median, Chloride_min, Chloride_range, Creatinine_max, Creatinine_median, Creatinine_min, Creatinine_range, Gender_mean, Glucose_max, Glucose_median, Glucose_min, Glucose_range, hands_max, hands_median, hands_min, hands_range, Hematocrit_max, Hematocrit_median, Hematocrit_min, Hematocrit_range, Hemoglobin_max, Hemoglobin_median, Hemoglobin_min, Hemoglobin_range, leg_max, leg_median, leg_min, leg_range, mouth_max, mouth_median, mouth_min, mouth_range, onset_delta_mean, onset_site_mean, Platelets_max, Platelets_median, Platelets_min, Potassium_max, Potassium_median, Potassium_min, Potassium_range, pulse_max, pulse_median, pulse_min, pulse_range, respiratory_max, respiratory_median, respiratory_min, respiratory_range, Sodium_max, Sodium_median, Sodium_min, Sodium_range, trunk_max, trunk_median, trunk_min, trunk_range, Urine.Ph_max, Urine.Ph_median, Urine.Ph_min
## ── Dense features ──────────────────────────────────────────────────────────────The feature_spec output spec is used together
with the keras::layer_dense_features() method to directly
perform pre-processing in the TensorFlow graph. We can take a look at
the output of a dense-features layer created by the
feature_spec, which is a matrix (2D tensor) with scaled
values.
layer <- layer_dense_features(feature_columns = dense_features(spec), dtype = tf$float32)
# layer(als)Next, we design the network architecture model using the
feature_spec API by passing the dense_features
from the new spec object.
input <- layer_input_from_dataset(als)
output <- input %>%
layer_dense_features(dense_features(spec)) %>%
layer_dense(units = 256, activation = "relu") %>%
layer_dense(units = 128, activation = "relu") %>%
layer_dense(units = 64, activation = "relu") %>%
layer_dense(units = 16, activation = "relu") %>%
layer_dense(units = 1)
model <- keras_model(input, output)
# summary(model)It’s time to compile the deep network model and wrap it into a
function build_model() that can be reused for different
experiments. Remember that keras::fit() modifies the model
in-place.
model %>% compile(loss = "mse", optimizer = optimizer_rmsprop(), metrics = list("mean_absolute_error"))
build_model <- function() {
input <- layer_input_from_dataset(als)
output <- input %>%
layer_dense_features(dense_features(spec)) %>%
layer_dense(units = 256, activation = "relu") %>%
layer_dense(units = 128, activation = "relu") %>%
layer_dense(units = 64, activation = "relu") %>%
layer_dense(units = 16, activation = "relu") %>%
layer_dense(units = 1)
model <- keras_model(input, output)
model %>% compile(loss = "mse", optimizer = optimizer_rmsprop(), metrics = list("mean_absolute_error"))
model
}Model training follows with 200 epochs where we record the training and validation accuracy in a keras_training_history object. For tracking the learning progress, we use a custom callback to replace the default training output at each epoch by a single dot (period) printed in the console .
# Display training progress by printing a single dot for each completed epoch.
print_dot_callback <- callback_lambda(
on_epoch_end = function(epoch, logs) {
if (epoch %% 80 == 0) cat("\n")
cat(".")
}
)
model <- build_model()
history <- model %>% fit(
x = als,
y = ALSFRS_slope,
epochs = 200,
validation_split = 0.2,
verbose = 0,
callbacks = list(print_dot_callback)
)##
## ................................................................................
## ................................................................................
## ........................................Let’s visualize the model’s training data performance using the metrics stored in the history object. This graph provides clues to determine training duration and confirm model performance convergence.
This graph shows little improvement in the model after about 200 epochs. Let’s update the fit method to automatically stop training when the validation score doesn’t improve. We’ll use a callback that tests a training condition for every epoch. If a set number of epochs elapses without showing improvement, it automatically stops the training.
#plot(history)
epochs <- 200
time <- 1:epochs
hist_df <- data.frame(time=time, loss=history$metrics$loss, mae=history$metrics$mean_absolute_error,
valid_loss=history$metrics$val_loss, valid_mae=history$metrics$val_mean_absolute_error)
plot_ly(hist_df, x = ~time) %>%
add_trace(y = ~loss, name = 'training loss', type="scatter", mode = 'lines') %>%
add_trace(y = ~mae, name = 'training MAE', type="scatter", mode = 'lines+markers') %>%
add_trace(y = ~valid_loss, name = 'validation loss', type="scatter", mode = 'lines+markers') %>%
add_trace(y = ~valid_mae, name = 'validation MAE', type="scatter", mode = 'lines+markers') %>%
layout(title="ALS Study NN Model Performance",
legend = list(orientation = 'h'), yaxis=list(title="metric"))# # Note that this graph shows little improvement in the model after about 100 epochs.
# # hence, we can update the fit method to automatically *stop training* when the validation score
# # doesn’t improve. The callback that tests a training condition for every epoch.
# # If a set amount of epochs elapses without showing improvement, it automatically stops the training.
#
# # The patience parameter is the amount of epochs to check for improvement.
# early_stop <- callback_early_stopping(monitor = "val_loss", patience = 20)
#
# model <- build_model()
#
# history <- model %>% fit(
# x = train_df %>% select(-label),
# y = train_df$label,
# epochs = 500,
# validation_split = 0.2,
# verbose = 0,
# callbacks = list(early_stop)
# )
# library(deepviz)
# model %>% plot_model()Have a look at the Google TensorFlow API. It shows the importance of learning rate and the number of rounds. You should test different sets of parameters.
- Too small learning rate may lead to long computations.
- Too large learning rate may cause the algorithm to fail to converge, as large step size (learning rate) may by-pass the optimal solution and then oscillate or even diverge.
Finally, we can forecast and predict the ALSFRS_slope using data in the testing set:
cases <- 100
test_sample <- sample(1:dim(als)[1], size=cases)
test_predictions <- model %>% predict(als[test_sample, ])## 4/4 - 1s - 904ms/epoch - 226ms/step# test_predictions[ , 1]
print(paste0("Corr(real_ALSFRS_Slope, predicted_ALSFRS_Slope)=",
round(cor(test_predictions, ALSFRS_slope[test_sample]), 3)))## [1] "Corr(real_ALSFRS_Slope, predicted_ALSFRS_Slope)=0.985"cases <- 1:cases
hist_df <- data.frame(cases=cases, real=ALSFRS_slope[test_sample], predicted=test_predictions)
corr1 <- round(cor(hist_df$real, hist_df$predicted), 2)
plot_ly(hist_df, x = ~real) %>%
add_trace(y = ~predicted, name = 'Scatter (Real vs. Predicted ALSFRS_Slope)', type="scatter", mode = 'markers') %>%
add_lines(x = ~real, y = ~fitted(lm(predicted ~ real, hist_df)), name="LM(Pred ~ Real)") %>%
layout(title=paste0("ALS Study NN Model Prediction (ALSFRS-slope correlation=", corr1,")"),
legend = list(orientation = 'h'), yaxis=list(title="predicted"))7.3 IBS Study
Let’s try another example using the IBS NI Study data. Again, we will use deep neural network learning to predict a categorical/binary classification label (diagnosis, DX).
# IBS NI Data
library(xml2)
library(rvest)
# UCLA Data
# wiki_url <- read_html("http://wiki.stat.ucla.edu/socr/index.php/SOCR_Data_April2011_NI_IBS_Pain")
# UMich Data
wiki_url <- read_html("https://wiki.socr.umich.edu/index.php/SOCR_Data_April2011_NI_IBS_Pain")
IBSData <- html_table(html_nodes(wiki_url, "table")[[2]]) # table 2
set.seed(1234)
test.ind = sample(1:354, 50, replace = F) # select 50/354 of cases for testing, train on remaining (354-50)/354 cases
# UMich Data (includes MISSING data): use `mice` to impute missing data with mean: newData <- mice(data,m=5,maxit=50,meth='pmm',seed=500); summary(newData)
# wiki_url <- read_html("https://wiki.socr.umich.edu/index.php/SOCR_Data_April2011_NI_IBS_Pain")
# IBSData<- html_table(html_nodes(wiki_url, "table")[[1]]) # load Table 1
# set.seed(1234)
# test.ind = sample(1:337, 50, replace = F) # select 50/337 of cases for testing, train on remaining (337-50)/337 cases
# summary(IBSData); IBSData[IBSData=="."] <- NA; newData <- mice(IBSData,m=5,maxit=50,meth='pmm',seed=500); summary(newData)
html_nodes(wiki_url, "#content")## {xml_nodeset (1)}
## [1] <div id="content" class="mw-body" role="main">\n\t\t\t<a id="top"></a>\n\ ...# View (IBSData); dim(IBSData): Select an outcome response "DX"(3), "FS_IQ" (5)
# scale/normalize all input variables
IBSData <- na.omit(IBSData)
IBSData[,4:66] <- scale(IBSData[,4:66]) # scale the entire dataset
train.x = data.matrix(IBSData[-test.ind, c(4:66)]) # exclude outcome
train.y = IBSData[-test.ind, 3]-1
test.x = data.matrix(IBSData[test.ind, c(4:66)])
test.y = IBSData[test.ind, 3]-1
train.y <- train.y$Group
test.y <- test.y$Group
# View(data.frame(test.x, test.y))
# View(data.frame(train.x, train.y))
model <- keras_model_sequential()
model %>%
layer_dense(units = 256, activation = 'relu', input_shape = ncol(train.x)) %>%
layer_dropout(rate = 0.4) %>%
layer_dense(units = 128, activation = 'relu') %>%
layer_dropout(rate = 0.3) %>%
layer_dense(units = 64, activation = 'relu') %>%
layer_dropout(rate = 0.1) %>%
layer_dense(units = 32, activation = 'relu') %>%
layer_dropout(rate = 0.1) %>%
layer_dense(units = 16, activation = 'relu') %>%
layer_dropout(rate = 0.1) %>%
layer_dense(units = 2, activation = 'sigmoid')
model %>% compile(
loss = 'binary_crossentropy',
optimizer = 'adam',
metrics = c('accuracy')
)
one_hot_labels <- to_categorical(train.y, num_classes = 2)
# Train the model, iterating on the data in batches of 25 samples
history <- model %>% fit(
train.x, one_hot_labels,
epochs = 100,
batch_size = 5,
validation_split = 0.1
)## Epoch 1/100
## 55/55 - 1s - loss: 0.6903 - accuracy: 0.5751 - val_loss: 0.9114 - val_accuracy: 0.0000e+00 - 753ms/epoch - 14ms/step
## Epoch 2/100
## 55/55 - 0s - loss: 0.6432 - accuracy: 0.6667 - val_loss: 1.3447 - val_accuracy: 0.0000e+00 - 85ms/epoch - 2ms/step
## Epoch 3/100
## 55/55 - 0s - loss: 0.6477 - accuracy: 0.6703 - val_loss: 1.3154 - val_accuracy: 0.0000e+00 - 83ms/epoch - 2ms/step
## Epoch 4/100
## 55/55 - 0s - loss: 0.6160 - accuracy: 0.6703 - val_loss: 1.2212 - val_accuracy: 0.0000e+00 - 86ms/epoch - 2ms/step
## Epoch 5/100
## 55/55 - 0s - loss: 0.6007 - accuracy: 0.6777 - val_loss: 1.1915 - val_accuracy: 0.0000e+00 - 85ms/epoch - 2ms/step
## Epoch 6/100
## 55/55 - 0s - loss: 0.5678 - accuracy: 0.6886 - val_loss: 1.5945 - val_accuracy: 0.0000e+00 - 85ms/epoch - 2ms/step
## Epoch 7/100
## 55/55 - 0s - loss: 0.5295 - accuracy: 0.7070 - val_loss: 2.4045 - val_accuracy: 0.0000e+00 - 89ms/epoch - 2ms/step
## Epoch 8/100
## 55/55 - 0s - loss: 0.5406 - accuracy: 0.7106 - val_loss: 2.9199 - val_accuracy: 0.0000e+00 - 84ms/epoch - 2ms/step
## Epoch 9/100
## 55/55 - 0s - loss: 0.4762 - accuracy: 0.7692 - val_loss: 2.9685 - val_accuracy: 0.0323 - 83ms/epoch - 2ms/step
## Epoch 10/100
## 55/55 - 0s - loss: 0.4277 - accuracy: 0.8022 - val_loss: 3.9760 - val_accuracy: 0.0645 - 90ms/epoch - 2ms/step
## Epoch 11/100
## 55/55 - 0s - loss: 0.4939 - accuracy: 0.7839 - val_loss: 3.1731 - val_accuracy: 0.0000e+00 - 86ms/epoch - 2ms/step
## Epoch 12/100
## 55/55 - 0s - loss: 0.4219 - accuracy: 0.8022 - val_loss: 3.2873 - val_accuracy: 0.0000e+00 - 85ms/epoch - 2ms/step
## Epoch 13/100
## 55/55 - 0s - loss: 0.3632 - accuracy: 0.8242 - val_loss: 5.4941 - val_accuracy: 0.0000e+00 - 85ms/epoch - 2ms/step
## Epoch 14/100
## 55/55 - 0s - loss: 0.3816 - accuracy: 0.8315 - val_loss: 3.9060 - val_accuracy: 0.0645 - 84ms/epoch - 2ms/step
## Epoch 15/100
## 55/55 - 0s - loss: 0.3960 - accuracy: 0.8498 - val_loss: 3.6063 - val_accuracy: 0.0968 - 86ms/epoch - 2ms/step
## Epoch 16/100
## 55/55 - 0s - loss: 0.3649 - accuracy: 0.8791 - val_loss: 4.2806 - val_accuracy: 0.1290 - 85ms/epoch - 2ms/step
## Epoch 17/100
## 55/55 - 0s - loss: 0.3380 - accuracy: 0.8315 - val_loss: 3.8078 - val_accuracy: 0.0968 - 101ms/epoch - 2ms/step
## Epoch 18/100
## 55/55 - 0s - loss: 0.2900 - accuracy: 0.8864 - val_loss: 5.8833 - val_accuracy: 0.0323 - 87ms/epoch - 2ms/step
## Epoch 19/100
## 55/55 - 0s - loss: 0.3213 - accuracy: 0.8718 - val_loss: 5.7972 - val_accuracy: 0.0323 - 85ms/epoch - 2ms/step
## Epoch 20/100
## 55/55 - 0s - loss: 0.3222 - accuracy: 0.8864 - val_loss: 4.6742 - val_accuracy: 0.0645 - 86ms/epoch - 2ms/step
## Epoch 21/100
## 55/55 - 0s - loss: 0.2426 - accuracy: 0.9084 - val_loss: 5.7994 - val_accuracy: 0.0645 - 88ms/epoch - 2ms/step
## Epoch 22/100
## 55/55 - 0s - loss: 0.2900 - accuracy: 0.8755 - val_loss: 5.7080 - val_accuracy: 0.0323 - 91ms/epoch - 2ms/step
## Epoch 23/100
## 55/55 - 0s - loss: 0.3315 - accuracy: 0.8864 - val_loss: 4.1147 - val_accuracy: 0.1290 - 91ms/epoch - 2ms/step
## Epoch 24/100
## 55/55 - 0s - loss: 0.1904 - accuracy: 0.9194 - val_loss: 7.2940 - val_accuracy: 0.0000e+00 - 86ms/epoch - 2ms/step
## Epoch 25/100
## 55/55 - 0s - loss: 0.2681 - accuracy: 0.8718 - val_loss: 9.5444 - val_accuracy: 0.0000e+00 - 88ms/epoch - 2ms/step
## Epoch 26/100
## 55/55 - 0s - loss: 0.3051 - accuracy: 0.8974 - val_loss: 5.4156 - val_accuracy: 0.0323 - 83ms/epoch - 2ms/step
## Epoch 27/100
## 55/55 - 0s - loss: 0.2119 - accuracy: 0.9158 - val_loss: 7.2999 - val_accuracy: 0.0323 - 83ms/epoch - 2ms/step
## Epoch 28/100
## 55/55 - 0s - loss: 0.2332 - accuracy: 0.9084 - val_loss: 8.0987 - val_accuracy: 0.0000e+00 - 81ms/epoch - 1ms/step
## Epoch 29/100
## 55/55 - 0s - loss: 0.1846 - accuracy: 0.9231 - val_loss: 8.5910 - val_accuracy: 0.0645 - 80ms/epoch - 1ms/step
## Epoch 30/100
## 55/55 - 0s - loss: 0.1957 - accuracy: 0.9231 - val_loss: 9.9489 - val_accuracy: 0.0000e+00 - 80ms/epoch - 1ms/step
## Epoch 31/100
## 55/55 - 0s - loss: 0.1416 - accuracy: 0.9341 - val_loss: 9.2311 - val_accuracy: 0.0323 - 78ms/epoch - 1ms/step
## Epoch 32/100
## 55/55 - 0s - loss: 0.2990 - accuracy: 0.9084 - val_loss: 7.5238 - val_accuracy: 0.0323 - 80ms/epoch - 1ms/step
## Epoch 33/100
## 55/55 - 0s - loss: 0.2017 - accuracy: 0.9267 - val_loss: 7.9874 - val_accuracy: 0.0323 - 79ms/epoch - 1ms/step
## Epoch 34/100
## 55/55 - 0s - loss: 0.2317 - accuracy: 0.9451 - val_loss: 7.2813 - val_accuracy: 0.0323 - 88ms/epoch - 2ms/step
## Epoch 35/100
## 55/55 - 0s - loss: 0.2009 - accuracy: 0.9414 - val_loss: 6.3986 - val_accuracy: 0.1290 - 84ms/epoch - 2ms/step
## Epoch 36/100
## 55/55 - 0s - loss: 0.1521 - accuracy: 0.9377 - val_loss: 9.2472 - val_accuracy: 0.0000e+00 - 80ms/epoch - 1ms/step
## Epoch 37/100
## 55/55 - 0s - loss: 0.1513 - accuracy: 0.9451 - val_loss: 6.2962 - val_accuracy: 0.1613 - 82ms/epoch - 1ms/step
## Epoch 38/100
## 55/55 - 0s - loss: 0.1818 - accuracy: 0.9231 - val_loss: 8.3283 - val_accuracy: 0.0645 - 80ms/epoch - 1ms/step
## Epoch 39/100
## 55/55 - 0s - loss: 0.1354 - accuracy: 0.9304 - val_loss: 9.3264 - val_accuracy: 0.0968 - 80ms/epoch - 1ms/step
## Epoch 40/100
## 55/55 - 0s - loss: 0.1578 - accuracy: 0.9084 - val_loss: 9.5949 - val_accuracy: 0.0968 - 78ms/epoch - 1ms/step
## Epoch 41/100
## 55/55 - 0s - loss: 0.1890 - accuracy: 0.9304 - val_loss: 10.4144 - val_accuracy: 0.0000e+00 - 79ms/epoch - 1ms/step
## Epoch 42/100
## 55/55 - 0s - loss: 0.1260 - accuracy: 0.9377 - val_loss: 10.2521 - val_accuracy: 0.0000e+00 - 80ms/epoch - 1ms/step
## Epoch 43/100
## 55/55 - 0s - loss: 0.1123 - accuracy: 0.9377 - val_loss: 13.8243 - val_accuracy: 0.0000e+00 - 79ms/epoch - 1ms/step
## Epoch 44/100
## 55/55 - 0s - loss: 0.1896 - accuracy: 0.9377 - val_loss: 8.1844 - val_accuracy: 0.0645 - 76ms/epoch - 1ms/step
## Epoch 45/100
## 55/55 - 0s - loss: 0.1102 - accuracy: 0.9524 - val_loss: 10.1354 - val_accuracy: 0.0000e+00 - 82ms/epoch - 1ms/step
## Epoch 46/100
## 55/55 - 0s - loss: 0.0999 - accuracy: 0.9560 - val_loss: 12.7456 - val_accuracy: 0.0000e+00 - 79ms/epoch - 1ms/step
## Epoch 47/100
## 55/55 - 0s - loss: 0.1021 - accuracy: 0.9634 - val_loss: 10.5475 - val_accuracy: 0.0323 - 88ms/epoch - 2ms/step
## Epoch 48/100
## 55/55 - 0s - loss: 0.1654 - accuracy: 0.9341 - val_loss: 11.4524 - val_accuracy: 0.0000e+00 - 81ms/epoch - 1ms/step
## Epoch 49/100
## 55/55 - 0s - loss: 0.3115 - accuracy: 0.9267 - val_loss: 7.8790 - val_accuracy: 0.0000e+00 - 80ms/epoch - 1ms/step
## Epoch 50/100
## 55/55 - 0s - loss: 0.1105 - accuracy: 0.9487 - val_loss: 9.6096 - val_accuracy: 0.0000e+00 - 80ms/epoch - 1ms/step
## Epoch 51/100
## 55/55 - 0s - loss: 0.0985 - accuracy: 0.9451 - val_loss: 10.5584 - val_accuracy: 0.0645 - 81ms/epoch - 1ms/step
## Epoch 52/100
## 55/55 - 0s - loss: 0.1255 - accuracy: 0.9377 - val_loss: 10.8039 - val_accuracy: 0.0323 - 80ms/epoch - 1ms/step
## Epoch 53/100
## 55/55 - 0s - loss: 0.1215 - accuracy: 0.9524 - val_loss: 10.0162 - val_accuracy: 0.0323 - 79ms/epoch - 1ms/step
## Epoch 54/100
## 55/55 - 0s - loss: 0.1482 - accuracy: 0.9341 - val_loss: 9.0184 - val_accuracy: 0.0323 - 79ms/epoch - 1ms/step
## Epoch 55/100
## 55/55 - 0s - loss: 0.1315 - accuracy: 0.9267 - val_loss: 10.0325 - val_accuracy: 0.0000e+00 - 78ms/epoch - 1ms/step
## Epoch 56/100
## 55/55 - 0s - loss: 0.0948 - accuracy: 0.9597 - val_loss: 12.4201 - val_accuracy: 0.0000e+00 - 77ms/epoch - 1ms/step
## Epoch 57/100
## 55/55 - 0s - loss: 0.1073 - accuracy: 0.9597 - val_loss: 9.1830 - val_accuracy: 0.0645 - 83ms/epoch - 2ms/step
## Epoch 58/100
## 55/55 - 0s - loss: 0.1164 - accuracy: 0.9487 - val_loss: 11.8631 - val_accuracy: 0.0000e+00 - 81ms/epoch - 1ms/step
## Epoch 59/100
## 55/55 - 0s - loss: 0.2204 - accuracy: 0.9377 - val_loss: 8.5886 - val_accuracy: 0.0000e+00 - 76ms/epoch - 1ms/step
## Epoch 60/100
## 55/55 - 0s - loss: 0.0924 - accuracy: 0.9634 - val_loss: 11.5138 - val_accuracy: 0.0323 - 80ms/epoch - 1ms/step
## Epoch 61/100
## 55/55 - 0s - loss: 0.1378 - accuracy: 0.9451 - val_loss: 15.6015 - val_accuracy: 0.0000e+00 - 79ms/epoch - 1ms/step
## Epoch 62/100
## 55/55 - 0s - loss: 0.1620 - accuracy: 0.9267 - val_loss: 11.1127 - val_accuracy: 0.0000e+00 - 86ms/epoch - 2ms/step
## Epoch 63/100
## 55/55 - 0s - loss: 0.0788 - accuracy: 0.9560 - val_loss: 12.3979 - val_accuracy: 0.0000e+00 - 79ms/epoch - 1ms/step
## Epoch 64/100
## 55/55 - 0s - loss: 0.0557 - accuracy: 0.9780 - val_loss: 14.0089 - val_accuracy: 0.0000e+00 - 80ms/epoch - 1ms/step
## Epoch 65/100
## 55/55 - 0s - loss: 0.0806 - accuracy: 0.9597 - val_loss: 13.8860 - val_accuracy: 0.0000e+00 - 78ms/epoch - 1ms/step
## Epoch 66/100
## 55/55 - 0s - loss: 0.0945 - accuracy: 0.9524 - val_loss: 15.2727 - val_accuracy: 0.0000e+00 - 83ms/epoch - 2ms/step
## Epoch 67/100
## 55/55 - 0s - loss: 0.0674 - accuracy: 0.9707 - val_loss: 15.4522 - val_accuracy: 0.0000e+00 - 82ms/epoch - 1ms/step
## Epoch 68/100
## 55/55 - 0s - loss: 0.0834 - accuracy: 0.9670 - val_loss: 16.3372 - val_accuracy: 0.0000e+00 - 81ms/epoch - 1ms/step
## Epoch 69/100
## 55/55 - 0s - loss: 0.0744 - accuracy: 0.9597 - val_loss: 12.8756 - val_accuracy: 0.0323 - 78ms/epoch - 1ms/step
## Epoch 70/100
## 55/55 - 0s - loss: 0.0628 - accuracy: 0.9634 - val_loss: 14.0646 - val_accuracy: 0.0000e+00 - 79ms/epoch - 1ms/step
## Epoch 71/100
## 55/55 - 0s - loss: 0.0816 - accuracy: 0.9707 - val_loss: 16.5797 - val_accuracy: 0.0000e+00 - 82ms/epoch - 1ms/step
## Epoch 72/100
## 55/55 - 0s - loss: 0.1247 - accuracy: 0.9524 - val_loss: 14.0024 - val_accuracy: 0.0645 - 87ms/epoch - 2ms/step
## Epoch 73/100
## 55/55 - 0s - loss: 0.0701 - accuracy: 0.9597 - val_loss: 15.8688 - val_accuracy: 0.0323 - 79ms/epoch - 1ms/step
## Epoch 74/100
## 55/55 - 0s - loss: 0.1092 - accuracy: 0.9634 - val_loss: 14.4066 - val_accuracy: 0.0645 - 80ms/epoch - 1ms/step
## Epoch 75/100
## 55/55 - 0s - loss: 0.0746 - accuracy: 0.9634 - val_loss: 14.5796 - val_accuracy: 0.0323 - 80ms/epoch - 1ms/step
## Epoch 76/100
## 55/55 - 0s - loss: 0.0608 - accuracy: 0.9780 - val_loss: 17.4531 - val_accuracy: 0.0323 - 82ms/epoch - 1ms/step
## Epoch 77/100
## 55/55 - 0s - loss: 0.0812 - accuracy: 0.9634 - val_loss: 15.5935 - val_accuracy: 0.0645 - 80ms/epoch - 1ms/step
## Epoch 78/100
## 55/55 - 0s - loss: 0.0486 - accuracy: 0.9744 - val_loss: 18.0817 - val_accuracy: 0.0323 - 83ms/epoch - 2ms/step
## Epoch 79/100
## 55/55 - 0s - loss: 0.0602 - accuracy: 0.9634 - val_loss: 15.8360 - val_accuracy: 0.0968 - 80ms/epoch - 1ms/step
## Epoch 80/100
## 55/55 - 0s - loss: 0.1264 - accuracy: 0.9634 - val_loss: 15.2281 - val_accuracy: 0.0000e+00 - 82ms/epoch - 1ms/step
## Epoch 81/100
## 55/55 - 0s - loss: 0.0766 - accuracy: 0.9597 - val_loss: 20.0874 - val_accuracy: 0.0000e+00 - 79ms/epoch - 1ms/step
## Epoch 82/100
## 55/55 - 0s - loss: 0.0924 - accuracy: 0.9597 - val_loss: 19.0611 - val_accuracy: 0.0000e+00 - 80ms/epoch - 1ms/step
## Epoch 83/100
## 55/55 - 0s - loss: 0.1493 - accuracy: 0.9560 - val_loss: 10.9905 - val_accuracy: 0.0323 - 79ms/epoch - 1ms/step
## Epoch 84/100
## 55/55 - 0s - loss: 0.0778 - accuracy: 0.9634 - val_loss: 15.0828 - val_accuracy: 0.0000e+00 - 80ms/epoch - 1ms/step
## Epoch 85/100
## 55/55 - 0s - loss: 0.1939 - accuracy: 0.9414 - val_loss: 8.7264 - val_accuracy: 0.0000e+00 - 81ms/epoch - 1ms/step
## Epoch 86/100
## 55/55 - 0s - loss: 0.1404 - accuracy: 0.9451 - val_loss: 10.4815 - val_accuracy: 0.0645 - 80ms/epoch - 1ms/step
## Epoch 87/100
## 55/55 - 0s - loss: 0.0806 - accuracy: 0.9597 - val_loss: 18.8560 - val_accuracy: 0.0000e+00 - 81ms/epoch - 1ms/step
## Epoch 88/100
## 55/55 - 0s - loss: 0.1732 - accuracy: 0.9524 - val_loss: 11.2922 - val_accuracy: 0.0323 - 77ms/epoch - 1ms/step
## Epoch 89/100
## 55/55 - 0s - loss: 0.0993 - accuracy: 0.9414 - val_loss: 11.9314 - val_accuracy: 0.0323 - 83ms/epoch - 2ms/step
## Epoch 90/100
## 55/55 - 0s - loss: 0.1000 - accuracy: 0.9451 - val_loss: 13.2716 - val_accuracy: 0.0323 - 79ms/epoch - 1ms/step
## Epoch 91/100
## 55/55 - 0s - loss: 0.1377 - accuracy: 0.9377 - val_loss: 12.1723 - val_accuracy: 0.0645 - 83ms/epoch - 2ms/step
## Epoch 92/100
## 55/55 - 0s - loss: 0.0824 - accuracy: 0.9560 - val_loss: 13.8579 - val_accuracy: 0.0323 - 83ms/epoch - 2ms/step
## Epoch 93/100
## 55/55 - 0s - loss: 0.0782 - accuracy: 0.9744 - val_loss: 18.0617 - val_accuracy: 0.0323 - 83ms/epoch - 2ms/step
## Epoch 94/100
## 55/55 - 0s - loss: 0.0734 - accuracy: 0.9670 - val_loss: 14.7903 - val_accuracy: 0.0323 - 79ms/epoch - 1ms/step
## Epoch 95/100
## 55/55 - 0s - loss: 0.1466 - accuracy: 0.9524 - val_loss: 11.2545 - val_accuracy: 0.0000e+00 - 81ms/epoch - 1ms/step
## Epoch 96/100
## 55/55 - 0s - loss: 0.0927 - accuracy: 0.9597 - val_loss: 12.3747 - val_accuracy: 0.0323 - 81ms/epoch - 1ms/step
## Epoch 97/100
## 55/55 - 0s - loss: 0.0927 - accuracy: 0.9634 - val_loss: 13.6698 - val_accuracy: 0.0323 - 90ms/epoch - 2ms/step
## Epoch 98/100
## 55/55 - 0s - loss: 0.0558 - accuracy: 0.9670 - val_loss: 14.8537 - val_accuracy: 0.0323 - 81ms/epoch - 1ms/step
## Epoch 99/100
## 55/55 - 0s - loss: 0.1267 - accuracy: 0.9707 - val_loss: 10.8353 - val_accuracy: 0.0323 - 82ms/epoch - 1ms/step
## Epoch 100/100
## 55/55 - 0s - loss: 0.0951 - accuracy: 0.9634 - val_loss: 14.6050 - val_accuracy: 0.0323 - 78ms/epoch - 1ms/step## 2/2 - 0s - loss: 4.1163 - accuracy: 0.6200 - 15ms/epoch - 7ms/step## loss accuracy
## 4.116336 0.620000
epochs <- 100
time <- 1:epochs
hist_df <- data.frame(time=time, loss=history$metrics$loss, acc=history$metrics$accuracy,
valid_loss=history$metrics$val_loss, valid_acc=history$metrics$val_accuracy)
plot_ly(hist_df, x = ~time) %>%
add_trace(y = ~loss, name = 'training loss', type="scatter", mode = 'lines') %>%
add_trace(y = ~acc, name = 'training accuracy', type="scatter", mode = 'lines+markers') %>%
add_trace(y = ~valid_loss, name = 'validation loss', type="scatter",mode = 'lines+markers') %>%
add_trace(y = ~valid_acc, name = 'validation accuracy', type="scatter", mode = 'lines+markers') %>%
layout(title="IBS Study NN Model Performance",
legend = list(orientation = 'h'), yaxis=list(title="metric"))# Finally prediction of binary class labels and Confusion Matrix
predictions <- model %>% predict(test.x) %>% k_argmax()## 2/2 - 0s - 44ms/epoch - 22ms/step##
## 0 1
## 0 29 18
## 1 1 2# We can also inspect the corresponding probabilities of the automated binary classification labels
# prediction_probabilities <- model %>% predict(test.x)These results suggest that the DNN classification of IBS diagnosis is not good (at least under the specific network topology and training conditions).
7.4 Country QoL Ranking Data
Another case-study we have seen before is the country quality of life (QoL) dataset. Let’s try to fit a network model and use it to predict the overall QoL. This is another binary classification problem categorizing countries as either developed or developing.
# install.packages("xml2")
# install.packages("rvest")
# Load the rvest package
library(rvest)
# Load the xml2 package
library(xml2)
library(plotly)
# wiki_url <- read_html("http://wiki.stat.ucla.edu/socr/index.php/SOCR_Data_2008_World_CountriesRankings")
wiki_url <- read_html("https://wiki.socr.umich.edu/index.php/SOCR_Data_2008_World_CountriesRankings")
html_nodes(wiki_url, "#content")## {xml_nodeset (1)}
## [1] <div id="content" class="mw-body" role="main">\n\t\t\t<a id="top"></a>\n\ ...CountryRankingData <- html_table(html_nodes(wiki_url, "table")[[1]])
# View (CountryRankingData); dim(CountryRankingData): Select an appropriate
# outcome "OA": Overall country ranking (13)
# Dichotomize outcome, Top-countries OA<20, bottom countries OA>=20
set.seed(1234)
test.ind = sample(1:100, 30, replace = F) # select 15/100 of cases for testing, train on remaining 85/100 cases
CountryRankingData[,c(8:12,14)] <- scale(CountryRankingData[,c(8:12,14)])
# scale/normalize all input variables
train.x = data.matrix(CountryRankingData[-test.ind, c(8:12,14)]) # exclude outcome
train.y = ifelse(CountryRankingData[-test.ind, 13] < 50, 1, 0)
test.x = data.matrix(CountryRankingData[test.ind, c(8:12,14)])
test.y = ifelse(CountryRankingData[test.ind, 13] < 50, 1, 0) # developed (high OA rank) country
model <- keras_model_sequential()
model %>%
layer_dense(units = 16, activation = 'relu', input_shape = ncol(train.x)) %>%
layer_dropout(rate = 0.4) %>%
layer_dense(units = 4, activation = 'relu') %>%
layer_dropout(rate = 0.1) %>%
layer_dense(units = 2, activation = 'sigmoid')
model %>% compile(
loss = 'binary_crossentropy',
optimizer = 'adam',
metrics = c('accuracy')
)
one_hot_labels <- to_categorical(train.y, num_classes = 2)
# Train the model, iterating on the data in batches of 25 samples
history <- model %>% fit(
train.x, one_hot_labels,
epochs = 50,
batch_size = 5,
validation_split = 0.1
)## Epoch 1/50
## 13/13 - 0s - loss: 0.7411 - accuracy: 0.3968 - val_loss: 0.6725 - val_accuracy: 0.5714 - 448ms/epoch - 34ms/step
## Epoch 2/50
## 13/13 - 0s - loss: 0.7073 - accuracy: 0.5238 - val_loss: 0.6364 - val_accuracy: 0.7143 - 31ms/epoch - 2ms/step
## Epoch 3/50
## 13/13 - 0s - loss: 0.6746 - accuracy: 0.5714 - val_loss: 0.6092 - val_accuracy: 0.7143 - 33ms/epoch - 3ms/step
## Epoch 4/50
## 13/13 - 0s - loss: 0.6596 - accuracy: 0.6190 - val_loss: 0.5788 - val_accuracy: 0.8571 - 34ms/epoch - 3ms/step
## Epoch 5/50
## 13/13 - 0s - loss: 0.6480 - accuracy: 0.6984 - val_loss: 0.5508 - val_accuracy: 0.8571 - 36ms/epoch - 3ms/step
## Epoch 6/50
## 13/13 - 0s - loss: 0.6340 - accuracy: 0.6984 - val_loss: 0.5290 - val_accuracy: 0.8571 - 35ms/epoch - 3ms/step
## Epoch 7/50
## 13/13 - 0s - loss: 0.6148 - accuracy: 0.7619 - val_loss: 0.5055 - val_accuracy: 0.8571 - 31ms/epoch - 2ms/step
## Epoch 8/50
## 13/13 - 0s - loss: 0.5961 - accuracy: 0.7778 - val_loss: 0.4839 - val_accuracy: 0.8571 - 30ms/epoch - 2ms/step
## Epoch 9/50
## 13/13 - 0s - loss: 0.5784 - accuracy: 0.7302 - val_loss: 0.4562 - val_accuracy: 0.8571 - 33ms/epoch - 3ms/step
## Epoch 10/50
## 13/13 - 0s - loss: 0.5596 - accuracy: 0.7460 - val_loss: 0.4299 - val_accuracy: 1.0000 - 32ms/epoch - 2ms/step
## Epoch 11/50
## 13/13 - 0s - loss: 0.5380 - accuracy: 0.8571 - val_loss: 0.4032 - val_accuracy: 1.0000 - 35ms/epoch - 3ms/step
## Epoch 12/50
## 13/13 - 0s - loss: 0.5388 - accuracy: 0.8571 - val_loss: 0.3812 - val_accuracy: 1.0000 - 32ms/epoch - 2ms/step
## Epoch 13/50
## 13/13 - 0s - loss: 0.5426 - accuracy: 0.7778 - val_loss: 0.3601 - val_accuracy: 1.0000 - 29ms/epoch - 2ms/step
## Epoch 14/50
## 13/13 - 0s - loss: 0.5091 - accuracy: 0.8095 - val_loss: 0.3385 - val_accuracy: 1.0000 - 34ms/epoch - 3ms/step
## Epoch 15/50
## 13/13 - 0s - loss: 0.4894 - accuracy: 0.8413 - val_loss: 0.3210 - val_accuracy: 1.0000 - 30ms/epoch - 2ms/step
## Epoch 16/50
## 13/13 - 0s - loss: 0.4621 - accuracy: 0.9048 - val_loss: 0.3026 - val_accuracy: 1.0000 - 31ms/epoch - 2ms/step
## Epoch 17/50
## 13/13 - 0s - loss: 0.4347 - accuracy: 0.8730 - val_loss: 0.2849 - val_accuracy: 1.0000 - 30ms/epoch - 2ms/step
## Epoch 18/50
## 13/13 - 0s - loss: 0.4652 - accuracy: 0.8571 - val_loss: 0.2677 - val_accuracy: 1.0000 - 27ms/epoch - 2ms/step
## Epoch 19/50
## 13/13 - 0s - loss: 0.4557 - accuracy: 0.8254 - val_loss: 0.2532 - val_accuracy: 1.0000 - 34ms/epoch - 3ms/step
## Epoch 20/50
## 13/13 - 0s - loss: 0.4380 - accuracy: 0.8413 - val_loss: 0.2393 - val_accuracy: 1.0000 - 28ms/epoch - 2ms/step
## Epoch 21/50
## 13/13 - 0s - loss: 0.4564 - accuracy: 0.8571 - val_loss: 0.2253 - val_accuracy: 1.0000 - 34ms/epoch - 3ms/step
## Epoch 22/50
## 13/13 - 0s - loss: 0.3825 - accuracy: 0.8889 - val_loss: 0.2140 - val_accuracy: 1.0000 - 29ms/epoch - 2ms/step
## Epoch 23/50
## 13/13 - 0s - loss: 0.4126 - accuracy: 0.8889 - val_loss: 0.2025 - val_accuracy: 1.0000 - 30ms/epoch - 2ms/step
## Epoch 24/50
## 13/13 - 0s - loss: 0.3856 - accuracy: 0.9048 - val_loss: 0.1916 - val_accuracy: 1.0000 - 29ms/epoch - 2ms/step
## Epoch 25/50
## 13/13 - 0s - loss: 0.3739 - accuracy: 0.8889 - val_loss: 0.1795 - val_accuracy: 1.0000 - 32ms/epoch - 2ms/step
## Epoch 26/50
## 13/13 - 0s - loss: 0.3649 - accuracy: 0.8889 - val_loss: 0.1691 - val_accuracy: 1.0000 - 31ms/epoch - 2ms/step
## Epoch 27/50
## 13/13 - 0s - loss: 0.3717 - accuracy: 0.8730 - val_loss: 0.1593 - val_accuracy: 1.0000 - 29ms/epoch - 2ms/step
## Epoch 28/50
## 13/13 - 0s - loss: 0.3426 - accuracy: 0.9048 - val_loss: 0.1508 - val_accuracy: 1.0000 - 30ms/epoch - 2ms/step
## Epoch 29/50
## 13/13 - 0s - loss: 0.3434 - accuracy: 0.9048 - val_loss: 0.1415 - val_accuracy: 1.0000 - 30ms/epoch - 2ms/step
## Epoch 30/50
## 13/13 - 0s - loss: 0.2936 - accuracy: 0.8889 - val_loss: 0.1331 - val_accuracy: 1.0000 - 30ms/epoch - 2ms/step
## Epoch 31/50
## 13/13 - 0s - loss: 0.3330 - accuracy: 0.8730 - val_loss: 0.1252 - val_accuracy: 1.0000 - 30ms/epoch - 2ms/step
## Epoch 32/50
## 13/13 - 0s - loss: 0.3295 - accuracy: 0.9206 - val_loss: 0.1178 - val_accuracy: 1.0000 - 26ms/epoch - 2ms/step
## Epoch 33/50
## 13/13 - 0s - loss: 0.2671 - accuracy: 0.9524 - val_loss: 0.1104 - val_accuracy: 1.0000 - 29ms/epoch - 2ms/step
## Epoch 34/50
## 13/13 - 0s - loss: 0.2963 - accuracy: 0.9365 - val_loss: 0.1029 - val_accuracy: 1.0000 - 30ms/epoch - 2ms/step
## Epoch 35/50
## 13/13 - 0s - loss: 0.2871 - accuracy: 0.9206 - val_loss: 0.0958 - val_accuracy: 1.0000 - 31ms/epoch - 2ms/step
## Epoch 36/50
## 13/13 - 0s - loss: 0.2744 - accuracy: 0.9048 - val_loss: 0.0887 - val_accuracy: 1.0000 - 32ms/epoch - 2ms/step
## Epoch 37/50
## 13/13 - 0s - loss: 0.2582 - accuracy: 0.9524 - val_loss: 0.0816 - val_accuracy: 1.0000 - 27ms/epoch - 2ms/step
## Epoch 38/50
## 13/13 - 0s - loss: 0.2509 - accuracy: 0.9365 - val_loss: 0.0755 - val_accuracy: 1.0000 - 32ms/epoch - 2ms/step
## Epoch 39/50
## 13/13 - 0s - loss: 0.2357 - accuracy: 0.9683 - val_loss: 0.0705 - val_accuracy: 1.0000 - 32ms/epoch - 2ms/step
## Epoch 40/50
## 13/13 - 0s - loss: 0.2214 - accuracy: 0.9524 - val_loss: 0.0642 - val_accuracy: 1.0000 - 30ms/epoch - 2ms/step
## Epoch 41/50
## 13/13 - 0s - loss: 0.2272 - accuracy: 0.9206 - val_loss: 0.0581 - val_accuracy: 1.0000 - 30ms/epoch - 2ms/step
## Epoch 42/50
## 13/13 - 0s - loss: 0.2213 - accuracy: 0.9206 - val_loss: 0.0530 - val_accuracy: 1.0000 - 29ms/epoch - 2ms/step
## Epoch 43/50
## 13/13 - 0s - loss: 0.2394 - accuracy: 0.9048 - val_loss: 0.0491 - val_accuracy: 1.0000 - 30ms/epoch - 2ms/step
## Epoch 44/50
## 13/13 - 0s - loss: 0.2446 - accuracy: 0.9365 - val_loss: 0.0457 - val_accuracy: 1.0000 - 27ms/epoch - 2ms/step
## Epoch 45/50
## 13/13 - 0s - loss: 0.1889 - accuracy: 0.9524 - val_loss: 0.0421 - val_accuracy: 1.0000 - 30ms/epoch - 2ms/step
## Epoch 46/50
## 13/13 - 0s - loss: 0.2064 - accuracy: 0.9206 - val_loss: 0.0382 - val_accuracy: 1.0000 - 32ms/epoch - 2ms/step
## Epoch 47/50
## 13/13 - 0s - loss: 0.2016 - accuracy: 0.9206 - val_loss: 0.0358 - val_accuracy: 1.0000 - 29ms/epoch - 2ms/step
## Epoch 48/50
## 13/13 - 0s - loss: 0.2214 - accuracy: 0.9206 - val_loss: 0.0331 - val_accuracy: 1.0000 - 28ms/epoch - 2ms/step
## Epoch 49/50
## 13/13 - 0s - loss: 0.2062 - accuracy: 0.9524 - val_loss: 0.0302 - val_accuracy: 1.0000 - 28ms/epoch - 2ms/step
## Epoch 50/50
## 13/13 - 0s - loss: 0.2100 - accuracy: 0.9365 - val_loss: 0.0277 - val_accuracy: 1.0000 - 30ms/epoch - 2ms/step## 1/1 - 0s - loss: 0.1725 - accuracy: 0.9333 - 14ms/epoch - 14ms/step## loss accuracy
## 0.1724905 0.9333333# plot(history)
epochs <- 50
time <- 1:epochs
hist_df <- data.frame(time=time, loss=history$metrics$loss, acc=history$metrics$accuracy,
valid_loss=history$metrics$val_loss, valid_acc=history$metrics$val_accuracy)
plot_ly(hist_df, x = ~time) %>%
add_trace(y = ~loss, name = 'training loss', type="scatter", mode = 'lines') %>%
add_trace(y = ~acc, name = 'training accuracy', type="scatter", mode = 'lines+markers') %>%
add_trace(y = ~valid_loss, name = 'validation loss', type="scatter", mode = 'lines+markers') %>%
add_trace(y = ~valid_acc, name = 'validation accuracy', type="scatter", mode = 'lines+markers') %>%
layout(title="Country QoL Ranking NN Model Performance",
legend = list(orientation = 'h'), yaxis=list(title="metric"))# Finally prediction of binary class labels and Confusion Matrix
predictions <- model %>% predict(test.x) %>% k_argmax()## 1/1 - 0s - 27ms/epoch - 27ms/step##
## 0 1
## 0 13 2
## 1 0 15# We can also inspect the corresponding probabilities of the automated binary classification labels
# prediction_probabilities <- model %>% predict(test.x)Note that even a simple DNN network rapidly converges to an accurate model.
7.5 Handwritten Digits Classification
In Chapter 6 (ML, NN, SVM Classification) we discussed Optical Character Recognition (OCR). Specifically, we analyzed handwritten notes (unstructured text) and converted it to printed text.
The Modified National Institute of Standards and Technology (MNIST) database includes a large handwritten digits imaging dataset with human annotated labels. Every digit is represented by a \(28\times 28\) thumbnail image. You can download the training and testing data from Kaggle.
The train.csv and test.csv data files
contain gray-scale images of hand-drawn digits, \(0, 1, 2, \ldots, 9\). Each 2D image is
\(28\times 28\) in size and each of the
\(784\) pixels has a single
pixel-intensity representing the lightness or darkness of that pixel
(stored as a 1 byte integer \([0,255]\)). Higher intensities correspond
to darker pixels.
The training data, train.csv, has 785 columns, where the
first column, label, codes the actual digit drawn by
the user. The remaining \(784\) columns
contain the \(28\times 28=784\)
pixel-intensities of the associated 2D image. Columns in the training
set have \(pixel_K\) names, where \(0\leq K\leq 783\). To reconstruct a 2D
image out of each row in the training data we use this relation between
pixel-index (\(K\)) and \(X,Y\) image coordinates:
\[K = Y \times 28 + X,\] where \(0\leq X, Y\leq 27\). Thus, \(pixel_K\) is located on row \(Y\) and column \(X\) of the corresponding 2D Image of size \(28\times 28\). For instance, \(pixel_{60=(2\times 28 + 4)} \longleftrightarrow (X=4,Y=2)\) represents the pixel on the 3-rd row and 5-th column in the image. Diagrammatically, omitting the “pixel” prefix, the pixels may be ordered to reconstruct the 2D image as follows:
| Row | Col0 | Col1 | Col2 | Col3 | Col4 | … | Col26 | Co27 |
|---|---|---|---|---|---|---|---|---|
| Row0 | 000 | 001 | 002 | 003 | 004 | … | 026 | 027 |
| Row1 | 028 | 029 | 030 | 031 | 032 | … | 054 | 055 |
| Row2 | 056 | 057 | 058 | 059 | 060 | … | 082 | 083 |
| RowK | … | … | … | … | … | … | … | … |
| Row26 | 728 | 729 | 730 | 731 | 732 | … | 754 | 755 |
| Row27 | 756 | 757 | 758 | 759 | 760 | … | 782 | 783 |
Note that the point-to-pixelID transformation (\(K = Y \times 28 + X\)) may easily be inverted as a pixelID-to-point mapping: \(X= K\ mod\ 28\) (remainder of the integer division (\(K/28\)) and \(Y=K %/%28\) (integer part of the division \(K/28\))). For example:
K <- 60
X <- K %% 28 # X= K mod 28, remainder of integer division 60/28
Y <- K%/%28 # integer part of the division
# This validates that the application of both, the back and forth transformations, leads to an identity
K; X; Y; Y * 28 + X## [1] 60## [1] 4## [1] 2## [1] 60The test data (test.csv) has the same organization as
the training data, except that it does not contain the first
label column. It includes 28,000 images and we can
predict image labels that can be stored as \(ImageId,Label\) pairs, which can be
visually compared to the 2D images for validation/inspection.
# train.csv
pathToZip <- tempfile()
download.file("https://www.socr.umich.edu/people/dinov/2017/Spring/DSPA_HS650/data/DigitRecognizer_TrainingData.zip", pathToZip)
train <- read.csv(unzip(pathToZip))
dim(train)## [1] 42000 785unlink(pathToZip)
# test.csv
pathToZip <- tempfile()
download.file("https://www.socr.umich.edu/people/dinov/2017/Spring/DSPA_HS650/data/DigitRecognizer_TestingData.zip", pathToZip)
test <- read.csv(unzip(pathToZip))
dim(test)## [1] 28000 784unlink(pathToZip)
train <- data.matrix(train)
test <- data.matrix(test)
train.x <- train[,-1]
train.y <- train[,1]
# Scaling will be discussed below
train.x <- t(train.x/255)
test <- t(test/255)
# Note that you can also load the MNIST dataset (training & testing directly from keras)
# mnist <- dataset_mnist()
# train.x <- mnist$train$x
# train.y <- mnist$train$y
# test <- mnist$test$x
# test.y <- mnist$test$yLet’s look at some of these example images:
library("imager")
# first convert the CSV data (one row per image, 28,000 rows)
array_3D <- array(test, c(28, 28, 28000))
mat_2D <- matrix(array_3D[,,1], nrow = 28, ncol = 28)
plot(as.cimg(mat_2D))
# extract all N=28,000 images
N <- 28000
img_3D <- as.cimg(array_3D[,,], 28, 28, N)
# plot the k-th image (1<=k<=N)
k <- 5
plot(img_3D, k)
# Plot a collage of the first 4 images
imappend(list(image_2D(img_3D, 1), image_2D(img_3D, 2), image_2D(img_3D, 3), image_2D(img_3D, 4)),"y") %>% plot
In these CSV data files, each \(28\times
28\) image is represented as a single row. Gray-scale images are
\(1\) byte, in the range \([0, 255]\), which we linearly transformed
into \([0,1]\). Note that we only scale
the \(X\) input, not the output
(labels). Also, we don’t have manual gold-standard validation labels for
the testing data, i.e., test.y is not available for the
handwritten digits data.
Next, we can transpose the input matrix to \(n\ (pixels) \times m\ (examples)\), as the column major format required by the classifiers. The image labels are evenly distributed:
## train.y
## 0 1 2 3 4 5 6 7 8 9
## 4132 4684 4177 4351 4072 3795 4137 4401 4063 4188## train.y
## 0 1 2 3 4 5 6
## 0.09838095 0.11152381 0.09945238 0.10359524 0.09695238 0.09035714 0.09850000
## 7 8 9
## 0.10478571 0.09673810 0.09971429The majority class (1) in the training set includes
11.2% of the observations.
7.5.1 Configuring the Neural Network
The neural network model is trained by feeding the training data, i.e., training images (train.x) and training labels (train.y). The network learns to associate specific images with concrete labels. Then, the network generates label predictions for (new) testing images that can be compared to the true labels of test-images (if these are available) or visually inspected to confirm correct auto-classification.
The magrittr package pipe operator, %>%,
is commonly used for short-hand notation to allow left-and-right
feed-and-assignment that can be interpreted as “do
Nodes and layers represent the basic building-blocks of all artificial neural networks. Both are generalizations of brain neuron and network data processing that effectively transform, compress, or filter the input data. Inputs go in a node or a layer, and outputs come out. Network layers learn to extract effective representations of the inputs that are coded as meaningful outputs that can be connected by chaining together multiple layers that progressive distill the information into compressed generic knowledge (patterns) that can be used to predict, forecast, classify, or model the mechanistic relations in the process. That is, we use data as a proxy of observable processes for which we don;t have explicit closed-form probability distribution models (typically complex multivariate processes).
The network below chains a pair of layers densely connected (i.e.,
fully connected neural layers). The
keras_model_sequential() method specifies the network
architecture before we start with training (i.e., estimating the
weights). The loss function specifies how the network measures
its performance on the training data to adjust the network weights
(using train.x and train.y) to optimize the loss. The optimizer
specifies the mechanism for updating the network weight coefficients
using the training data relative to the specified loss function.
Different metrics can be used to track the performance during the
iterative training and testing process. For instance, accuracy
represents the fraction of the images that were correctly classified.
The second layer is a 10-way softmax layer that returns a
vector of 10 probability scalars (all positive and summing to 1) each
representing the probability that the current hand-written image
represents any of the 10 digits (\(0, 1, 2,
\cdots,9\)). The compile() function modifies the
network in place to specify the optimization strategy, the loss function
and the assessment metric that will be used in the learning process.
In this network example, we chain two dense layers to each layer and
apply simple tensor operations (tensor-dot-product/matrix multiplication
and tensor addition) to the input data to estimate the weight parameter
tensors, i.e., attributes of the layers encoding the persistent
knowledge of the network. The categorical_crossentropy is
the specific loss function that is optimized in the training phase to
provide a feedback signal for learning the weight tensors. The loss
optimization relies on mini-batch stochastic gradient descent, which is
defined by the rmsprop optimizer argument.
network <- keras_model_sequential() %>%
layer_dense(units = 512, activation = "relu", input_shape = c(28 * 28)) %>%
layer_dense(units = 10, activation = "softmax")
network %>% compile(optimizer = "rmsprop", loss = "categorical_crossentropy", metrics = c("accuracy"))Concatenating dense layers allows us to build a neural network whose
depth is determined by the number of layers that are specified by a
version of layer_dense(units = 512, activation = "relu"),
which represents a function of the input (2D tensor) and output a
different 2D tensor that may be fed as input tensor to the next layer.
Let \(ReLu(x)=\max(x, 0)\). \(W\) and \(b\) represent two of the attributes of the
layer (trainable weight parameters of the layer), i.e., the 2D kernel
tensor and the bias vector. Then the layer-output \(O\) is:
\[O= ReLu( W\times Input + b).\]
Deep learning network models are represented as directed, acyclic graphs of layers. Often, these networks constitute a linear stack of layers mapping a single input to a single output. Different types of network layers are appropriate for different kinds of data tensors:
- Simple vector data, stored in 2D tensors of shape \((samples,features)\), are often modeled
using densely connected layers, i.e., fully connected dense layers
(
keras::layer_dense function()). - Sequence data, stored in 3D tensors of shape \((samples, timesteps, features)\), are
typically modeled by recurrent layers such as
keras::layer_lstm(). - Image data, stored in 4D tensors, is usually processed by
2D convolution layers (
keras::layer_conv_2d()).
7.5.2 Training
We are ready to start the network training process. At the
initialization step of the learning process, the weight matrices are
filled with random values (random initialization). At the start, when
\(W\) and \(b\) are random, the output
relu(W*Input) + b is likely going to be meaningless.
However, the subsequent iterative process optimizing the objective
(loss) function will gradually adapt to these weights (training process)
by repeating the following steps until certain stopping criterion is
met:
- Draw a (random) batch of training samples \(x\) and their corresponding targets \(y\).
- Forward pass: Run the network on \(x\) to obtain predictions \(y_{pred}\).
- Estimate the loss of the network on the batch data assessing the mismatch between \(y\) and \(y_{pred}\).
- Update all weights (\(W\) and \(b\)) of the network to reduce the overall loss on this batch.
Iterating this process eventually yields a network that has a low loss on its training data indicating good fidelity (match between predictions \(y_{pred}\) and expected targets \(y\)). This reflects the network learning process progressed and accurately maps inputs to correct targets. See the BPAD Mathematical Foundations Chapter for more information on calculus of differentiation and integration, gradient minimization, and loss optimization.
Stochastic gradient descent (SGD) is a powerful function optimization strategy for differentiable multivariate functions. Recall that function’s extrema are attained at points where the derivative (gradient, \(\nabla (f)\)) is trivial (\(0\)) or at the domain boundary. Hence, to minimize the loss, we need to find all points (parameter vectors/tensors) that correspond to trivial derivatives/gradients of the objective function \(f\). Then, pick the parameter vectors/tensors/points leading to the smallest values of the loss. In neural network learning, this means analytically finding the combination of weight values corresponding to the smallest possible loss values.
This optimization is achieved at \(W_o\) when \(\nabla (f)(W_o) = 0\). Often, this gradient equation is a polynomial equation of \(N\) parameters (variables) corresponding to the number of coefficients (\(W\) and \(b\)) in the network. For large networks (with millions of parameters), this optimization is difficult. An approximate solution may be derived using alternative numerical solutions. This involves incrementally modifying the parameters and assuming the loss function is differentiable. We can then compute its gradient, which points the direction of the fastest growth or decay of the objective function.
- Draw a (random) batch of training samples \(x\) and their corresponding targets \(y\).
- Forward pass: Run the network on \(x\) to obtain predictions \(y_{pred}\).
- Estimate the loss of the network on the batch data assessing the mismatch between \(y\) and \(y_{pred}\).
- Compute the gradient of the loss \(\nabla (f)\) with regard to the network’s parameters (a backward pass).
- Slightly update/adjust the parameters in the opposite direction of the gradient, e.g., \(W = W-(step \times gradient)\), which reduces the loss function value on the batch data.
In practice, neural network learning depends on chaining many tensor operations. For instance, a network \(f\) composed of three tensor operations \(a\), \(b\), and \(c\), with weight matrices \(W_1\), \(W_2\), and \(W_3\) can be expressed as \(f(W_1, W_2, W_3) = a(W_1, b(W_2, c(W_3)))\). The chain-rule for differentiation yields that \(f(g(x)) = f'(g(x)) \times g'(x)\) leads to a corresponding neural network optimization algorithm (backpropagation), which starts with the final loss value and works backward from the top layers to the bottom layers, sequentially applying the chain rule to compute the contribution of each parameter to the aggregate loss value.
train_images <- t(train.x) # (42000, 28 * 28))
test_images <- t(test) # (28000, 28 * 28))
# Note: we can also use the `array_reshape()` tensor-reshaping function to reshape the array.
# categorically encode the training-image labels
train_labels <- to_categorical(train.y)Let’s now train (fit or estimate) the neural network model using
keras. In general, the first mode (axis) in the data
tensors is typically the sample axis (sample dimension). Often, it’s
difficult to process all data at the same time, breaking the data into
small batches, e.g., batch_size=128, allows for more
effective, efficient, and tractable processing (learning). The MNIST
tensor consists of images, saved as 3D color arrays indexed by height,
width, and depth, where gray-scale images (like the MNIST digits) have
only one color channel. In general, image tensors are always 3D. Hence,
a batch of 128 gray-scale images of size \(256\times 256\) is stored in a tensor of
shape \((128, 256, 256, 1)\),
whereas a batch of 128 color (RGB) images is stored as a \((128, 256, 256, 3)\) tensor.
## Epoch 1/10
## 329/329 - 1s - loss: 0.3066 - accuracy: 0.9106 - 1s/epoch - 3ms/step
## Epoch 2/10
## 329/329 - 1s - loss: 0.1282 - accuracy: 0.9629 - 823ms/epoch - 3ms/step
## Epoch 3/10
## 329/329 - 1s - loss: 0.0845 - accuracy: 0.9748 - 880ms/epoch - 3ms/step
## Epoch 4/10
## 329/329 - 1s - loss: 0.0604 - accuracy: 0.9829 - 897ms/epoch - 3ms/step
## Epoch 5/10
## 329/329 - 1s - loss: 0.0453 - accuracy: 0.9865 - 894ms/epoch - 3ms/step
## Epoch 6/10
## 329/329 - 1s - loss: 0.0337 - accuracy: 0.9904 - 872ms/epoch - 3ms/step
## Epoch 7/10
## 329/329 - 1s - loss: 0.0266 - accuracy: 0.9925 - 863ms/epoch - 3ms/step
## Epoch 8/10
## 329/329 - 1s - loss: 0.0199 - accuracy: 0.9947 - 860ms/epoch - 3ms/step
## Epoch 9/10
## 329/329 - 1s - loss: 0.0143 - accuracy: 0.9965 - 875ms/epoch - 3ms/step
## Epoch 10/10
## 329/329 - 1s - loss: 0.0106 - accuracy: 0.9977 - 865ms/epoch - 3ms/stepInvoking the method fit() launches the iterative network
learning on the training data using mini-batches of 128 samples. Each
iteration over all the training data is called an
epoch. Here we use epoch=10 to indicate looping 10
times over. At each iteration, the network computes the gradients of the
weights with regard to the loss on the batch and updates the tensor
weights. After completing 10 epochs, the network learning performed
3,290 gradient updates (329 per epoch), which progressively reduced the
loss of the network from \(10^{-2}\) to
\(10^{-4}\). This low loss indicates
the network learned to classify handwritten digits with high accuracy
(0.99).
During the training process, two graphs are dynamically shown that illustrate the parity between the network loss function (expected to decrease) and the accuracy of the network, using the training data. Note that the accuracy approaches 0.99, but remember, this is training-data sample-accuracy, which is biased. To get a more realistic performance estimate, we can test the model on an independent set of 10,000 testing data images.
# Load and preprocess the testing data
mnist <- dataset_mnist()
test_images <- mnist$test$x
test_labels <- mnist$test$y
dim(test_images) # [1] 10000 28 28## [1] 10000 28 28## [1] 10000test_images <- array_reshape(test_images, c(10000, 28 * 28))
test_images <- test_images / 255
test_labels <- to_categorical(test_labels)
metrics <- network %>% evaluate(test_images, test_labels)## 313/313 - 0s - loss: 0.0298 - accuracy: 0.9914 - 310ms/epoch - 991us/step## loss accuracy
## 0.02975595 0.99140000The testing data accuracy is 0.9886, on par with the training data performance, which indicates no evidence of overfitting.
7.5.3 Forecasting
Next, we will generate forecasting using the model on testing data
and evaluate the prediction performance. The preds matrix
has \(28,000\) rows and \(10\) columns, containing the desired
classification probabilities from the output layer of the
neural net. To extract the maximum label for each row, we can use the
max.col:
## 313/313 - 0s - 271ms/epoch - 867us/stepheat <- table(factor(pred.label$numpy()),factor(mnist$test$y))
keys = c(0:9)
plot_ly(x =~keys, y = ~keys, z = ~matrix(heat, 10,10), name="NN Model Performance",
hovertemplate = paste('<i>Matching</i>: %{z:.0f}',
'<br><b>True</b>: %{x}<br>', '<b>Pred</b>: %{y}'),
colors = 'Reds', type = "heatmap") %>%
layout(title="MNIST Predicated Number Classes vs. True Labels",
xaxis=list(title="Actual Class"), yaxis=list(title="Predicted Class"))The predictions are stored in a 1D \(28,000(rows)\) vector, including the predicted classification labels generated by the network output layer.
# For example, the ML-classification labels assigned to the first 7 images (from the 28,000 testing data collection) are:
pred.label <- pred.label$numpy()
head(pred.label, n = 7L)## [1] 7 2 1 0 4 1 4| x |
|---|
| 7 |
| 2 |
| 1 |
| 0 |
| 4 |
| 1 |
| 4 |
label.names <- c("0", "1", "2", "3", "4", "5", "6", "7", "8", "9")
#initialize a list of m=7 images from the N=28,000 available images
m_start <- 4
m_end <- 10
if (m_end <= m_start)
{ m_end = m_start+1 } # check that m_end > m_start
label_Ypositons <- vector() # initialize the array of label positions on the plot
for (i in m_start:m_end) {
if (i==m_start) {
img1 <- as.cimg(test_images[m_start,], 28, 28)
# img1 <- image_2D(img_3D, m_start)
}
else img1 <- imappend(list(img1, as.cimg(test_images[i,], 28, 28)),"y")
# else img1 <- imappend(list(img1, image_2D(img_3D, i)),"y")
label.names[i+1-m_start] <- pred.label[i]
label_Ypositons[i+1-m_start] <- 15 + 28*(i-m_start)
}
plot(img1, axes=FALSE)
text(40, label_Ypositons, labels=label.names[1:(m_end-m_start)], cex= 1.2, col="blue")
mtext(paste((m_end+1-m_start), " Random Images \n Indices (m_start=", m_start, " : m_end=", m_end, ")"), side=2, line=-6, col="black")
mtext("NN Classification Labels", side=4, line=-5, col="blue") 
7.5.4 Examining the Network Structure
There are a variety of network topologies, e.g., two-branch networks, multi-head networks, inception blocks, etc., that encode the a priori hypothesis space of predefined possibilities. Specifying the network topology constrains the space of possibilities to a specific series of tensor operations that map input data onto outputs. Then, the learning only searches for a good set of network parameter values (the weight tensors involved in these tensor operations). Specifying the network architecture in advance is as much an art as it is science.
There are two main strategies to define an a priori network topology
model. Linear stacks of network layers are specified using the
keras::keras_model_sequential() method, whereas functional
API’s provide interfaces for specifying directed acyclic graph (DAG)
layer networks with more flexible architectures. Functional network APIs
facilitate managing the data tensors processed by the model as well as
applying layers to tensors just as though the layers are abstract
functions. In the compilation step below, we configure the learning
process by specifying the model optimizer and loss functions, along with
the metrics for tracking the iterative learning process.
# Linear stacks of network layers
network <- keras_model_sequential() %>%
layer_dense(units = 512, activation = "relu", input_shape = c(28 * 28)) %>%
layer_dense(units = 10, activation = "softmax")
# vs. functional API network (DAG)
input_tensor <- layer_input(shape = c(784))
output_tensor <- input_tensor %>%
layer_dense(units = 32, activation = "relu") %>%
layer_dense(units = 10, activation = "softmax")
model <- keras_model(inputs = input_tensor, outputs = output_tensor)
model %>% compile(
optimizer = optimizer_adam(),
loss = "mse",
metrics = c("accuracy")
)
model %>% fit(train_images, train_labels, epochs = 10, batch_size = 128)## Epoch 1/10
## 329/329 - 1s - loss: 0.0252 - accuracy: 0.8389 - 570ms/epoch - 2ms/step
## Epoch 2/10
## 329/329 - 0s - loss: 0.0124 - accuracy: 0.9220 - 313ms/epoch - 950us/step
## Epoch 3/10
## 329/329 - 0s - loss: 0.0105 - accuracy: 0.9335 - 316ms/epoch - 961us/step
## Epoch 4/10
## 329/329 - 0s - loss: 0.0094 - accuracy: 0.9407 - 324ms/epoch - 985us/step
## Epoch 5/10
## 329/329 - 0s - loss: 0.0085 - accuracy: 0.9471 - 325ms/epoch - 986us/step
## Epoch 6/10
## 329/329 - 0s - loss: 0.0077 - accuracy: 0.9527 - 317ms/epoch - 965us/step
## Epoch 7/10
## 329/329 - 0s - loss: 0.0071 - accuracy: 0.9565 - 312ms/epoch - 950us/step
## Epoch 8/10
## 329/329 - 0s - loss: 0.0066 - accuracy: 0.9603 - 314ms/epoch - 956us/step
## Epoch 9/10
## 329/329 - 0s - loss: 0.0062 - accuracy: 0.9623 - 325ms/epoch - 987us/step
## Epoch 10/10
## 329/329 - 0s - loss: 0.0058 - accuracy: 0.9650 - 316ms/epoch - 961us/step7.5.5 Model Validation
We can use accuracy to track the performance of the NN training during the learning process on new (prospective) data.
val_indices <- sample(1:dim(train_images)[1], size=10000) # randomly choose 10K images
x_val <- train_images[val_indices, ]
y_val <- to_categorical(train.y[val_indices])
partial_x_train <- train_images[-val_indices, ]
partial_y_train <- to_categorical(train.y[-val_indices])
# train the model for 20 iterations over all samples in the x_train and y_train tensors (20 epochs),
# using mini-batches of 512 samples and track the loss and accuracy on the 10,000 validation samples
model %>% compile(optimizer = "rmsprop", loss = "binary_crossentropy", metrics = c("accuracy"))
history <- model %>% fit(partial_x_train, partial_y_train, epochs = 20, batch_size = 512,
validation_data = list(x_val, y_val) )## Epoch 1/20
## 63/63 - 0s - loss: 0.1100 - accuracy: 0.9543 - val_loss: 0.0577 - val_accuracy: 0.9573 - 443ms/epoch - 7ms/step
## Epoch 2/20
## 63/63 - 0s - loss: 0.0508 - accuracy: 0.9591 - val_loss: 0.0485 - val_accuracy: 0.9567 - 120ms/epoch - 2ms/step
## Epoch 3/20
## 63/63 - 0s - loss: 0.0447 - accuracy: 0.9598 - val_loss: 0.0447 - val_accuracy: 0.9574 - 110ms/epoch - 2ms/step
## Epoch 4/20
## 63/63 - 0s - loss: 0.0416 - accuracy: 0.9599 - val_loss: 0.0421 - val_accuracy: 0.9585 - 113ms/epoch - 2ms/step
## Epoch 5/20
## 63/63 - 0s - loss: 0.0394 - accuracy: 0.9614 - val_loss: 0.0407 - val_accuracy: 0.9565 - 116ms/epoch - 2ms/step
## Epoch 6/20
## 63/63 - 0s - loss: 0.0376 - accuracy: 0.9616 - val_loss: 0.0392 - val_accuracy: 0.9576 - 120ms/epoch - 2ms/step
## Epoch 7/20
## 63/63 - 0s - loss: 0.0362 - accuracy: 0.9620 - val_loss: 0.0382 - val_accuracy: 0.9588 - 119ms/epoch - 2ms/step
## Epoch 8/20
## 63/63 - 0s - loss: 0.0351 - accuracy: 0.9623 - val_loss: 0.0371 - val_accuracy: 0.9588 - 120ms/epoch - 2ms/step
## Epoch 9/20
## 63/63 - 0s - loss: 0.0341 - accuracy: 0.9633 - val_loss: 0.0365 - val_accuracy: 0.9589 - 120ms/epoch - 2ms/step
## Epoch 10/20
## 63/63 - 0s - loss: 0.0331 - accuracy: 0.9636 - val_loss: 0.0356 - val_accuracy: 0.9591 - 122ms/epoch - 2ms/step
## Epoch 11/20
## 63/63 - 0s - loss: 0.0323 - accuracy: 0.9644 - val_loss: 0.0350 - val_accuracy: 0.9590 - 122ms/epoch - 2ms/step
## Epoch 12/20
## 63/63 - 0s - loss: 0.0316 - accuracy: 0.9649 - val_loss: 0.0344 - val_accuracy: 0.9593 - 116ms/epoch - 2ms/step
## Epoch 13/20
## 63/63 - 0s - loss: 0.0309 - accuracy: 0.9662 - val_loss: 0.0341 - val_accuracy: 0.9583 - 115ms/epoch - 2ms/step
## Epoch 14/20
## 63/63 - 0s - loss: 0.0303 - accuracy: 0.9659 - val_loss: 0.0338 - val_accuracy: 0.9581 - 116ms/epoch - 2ms/step
## Epoch 15/20
## 63/63 - 0s - loss: 0.0298 - accuracy: 0.9668 - val_loss: 0.0334 - val_accuracy: 0.9600 - 114ms/epoch - 2ms/step
## Epoch 16/20
## 63/63 - 0s - loss: 0.0292 - accuracy: 0.9673 - val_loss: 0.0334 - val_accuracy: 0.9600 - 115ms/epoch - 2ms/step
## Epoch 17/20
## 63/63 - 0s - loss: 0.0287 - accuracy: 0.9679 - val_loss: 0.0326 - val_accuracy: 0.9597 - 112ms/epoch - 2ms/step
## Epoch 18/20
## 63/63 - 0s - loss: 0.0283 - accuracy: 0.9680 - val_loss: 0.0326 - val_accuracy: 0.9599 - 118ms/epoch - 2ms/step
## Epoch 19/20
## 63/63 - 0s - loss: 0.0279 - accuracy: 0.9680 - val_loss: 0.0321 - val_accuracy: 0.9597 - 116ms/epoch - 2ms/step
## Epoch 20/20
## 63/63 - 0s - loss: 0.0275 - accuracy: 0.9690 - val_loss: 0.0320 - val_accuracy: 0.9598 - 116ms/epoch - 2ms/step## [1] "Total Compute Time: 0" "Total Compute Time: 0" "Total Compute Time: 0"
## [4] "Total Compute Time: NA" "Total Compute Time: NA"library(plotly)
epochs <- 20
time <- 1:epochs
hist_df <- data.frame(time=time, loss=history$metrics$loss, acc=history$metrics$accuracy,
valid_loss=history$metrics$val_loss, valid_acc=history$metrics$val_accuracy)
plot_ly(hist_df, x = ~time) %>%
add_trace(y = ~loss, name = 'training loss', mode = 'lines') %>%
add_trace(y = ~acc, name = 'training accuracy', mode = 'lines+markers') %>%
add_trace(y = ~valid_loss, name = 'validation loss',mode = 'lines+markers') %>%
add_trace(y = ~valid_acc, name = 'validation accuracy', mode = 'lines+markers') %>%
layout(title="MNIST Digits NN Model Performance",
legend = list(orientation = 'h'), yaxis=list(title="metric"))# Finally prediction of MNIST testing image classification (auto-labeling):
pred.label <- model %>% predict(t(test))## 875/875 - 1s - 535ms/epoch - 611us/stepfor (i in 1:9) {
print(sprintf("NN predicted Label for image %d is %s", i, which.max(pred.label[i,])-1))
}## [1] "NN predicted Label for image 1 is 2"
## [1] "NN predicted Label for image 2 is 0"
## [1] "NN predicted Label for image 3 is 9"
## [1] "NN predicted Label for image 4 is 4"
## [1] "NN predicted Label for image 5 is 3"
## [1] "NN predicted Label for image 6 is 7"
## [1] "NN predicted Label for image 7 is 0"
## [1] "NN predicted Label for image 8 is 3"
## [1] "NN predicted Label for image 9 is 0"
#initialize a list of m=9 testing images from the N=28,000 available images
m_start <- 1
m_end <- 9
label_Ypositons <- vector() # initialize the array of label positions on the plot
for (i in m_start:m_end) {
if (i==m_start) {
img1 <- as.cimg(array_3D[1,,], nrow = 28, ncol = 28)
}
else img1 <- imappend(list(img1, as.cimg(array_3D[i,,], nrow = 28, ncol = 28)), "y")
label.names[i] <- which.max(pred.label[i,])-1
label_Ypositons[i+1-m_start] <- 15 + 28*(i-m_start)
}
plot(img1, axes=FALSE)
text(40, label_Ypositons, labels=label.names[1:(m_end-m_start+1)], cex= 1.2, col="blue")
mtext(paste((m_end+1-m_start), " Random Images \n Indices (m_start=", m_start, " : m_end=", m_end, ")"), side=2, line=-6, col="black")
mtext("NN Classification Labels", side=4, line=-5, col="blue") 
Note that the keras::predict() method only works with
Sequential network models. However, when using the functional
API network model we need to use the keras::predict()
method to obtain a vector of probabilities and then get the
argmax of this vector to find the most likely class label for
the image.
8 Classifying Real-World Images using Tensorflow and Keras
A real-world example of deep learning is the classification of 2D images (pictures) or 3D volumes (e.g., neuroimages).
We will demonstrate the use of pre-trained network
models (resnet50, vgg16, and vgg19) to predict the
class-labels of real world images. There are dozens of pre-trained models
that are made available to the entire community. These advanced Deep
Network models yield state-of-the-art predictions that accurately label
different types of 2D images. We will use the keras and
tensorflow packages to load the pre-trained network models
and classify the images, along with the imager package to
load and preprocess raw images in R.
8.1 Load the Pre-trained Model
You can download, unzip. and examine this pre-trained model. There are many different types of pre-trained deep neural network models, e.g.,
- Resnet50: Deep Residual Learning for Image Recognition,
- VGG16: Very Deep Convolutional Networks for Large-Scale Image Recognition, by Oxford’s Visual Geometry Group, and
- VGG19: Very Deep Convolutional Networks for Large-Scale Image Recognition.
The VGG’s are deep convolutional networks, trained to classify images, with VGG19 model layers comprised of:
- Conv3x3 (64)
- Conv3x3 (64)
- MaxPool
- Conv3x3 (128)
- Conv3x3 (128)
- MaxPool
- Conv3x3 (256)
- Conv3x3 (256)
- Conv3x3 (256)
- Conv3x3 (256)
- MaxPool
- Conv3x3 (512)
- Conv3x3 (512)
- Conv3x3 (512)
- Conv3x3 (512)
- MaxPool
- Conv3x3 (512)
- Conv3x3 (512)
- Conv3x3 (512)
- Conv3x3 (512)
- MaxPool
- Fully Connected (4096)
- Fully Connected (4096)
- Fully Connected (1000)
- SoftMax
More information about the VGG architecture is available online.
8.2 Load and Preprocess a New Image
To classify a new image, start with selecting and importing the image into R. Below, we show the classifications of several different types of images.
# if (!require("BiocManager", quietly = TRUE))
# install.packages("BiocManager")
# BiocManager::install("EBImage")
# library("imager")
# library("EBImage")
library("keras")
# Check system python config
# reticulate::py_config()
# One should be able to load the image directly from the web (but sometimes there may be problems, in which case, we need to first download the image and then load it in R:
# im <- imager::load.image("https://wiki.socr.umich.edu/images/6/69/DataManagementFig1.png")
# download file to local working directory, use "wb" mode to avoid problems
download.file("https://wiki.socr.umich.edu/images/6/69/DataManagementFig1.png", paste(getwd(),"results/image.png", sep="/"), mode = 'wb')
# report download image path
paste(getwd(),"results/image.png", sep="/")## [1] "D:/IvoD/Desktop/Ivo.dir/Research/UMichigan/Publications_Books/2023/DSPA_Springer_2nd_Edition_2023/Rmd_HTML/results/image.png"img <- image_load(paste(getwd(),"results/image.png", sep="/"), target_size = c(224,224))
# # dim(image_to_array(img)) # [1] 1084 1875 3
# # img <- rgbImage(red=t(image_to_array(img)[,,1]/255),
# # green=t(image_to_array(img)[,,2]/255), blue=t(image_to_array(img)[,,3]/255))
# img <- rgb(red=t(image_to_array(img)[,,1]/255),
# green=t(image_to_array(img)[,,2]/255), blue=t(image_to_array(img)[,,3]/255))
# str(img)
# # display(img)
# img1 = load.image(paste(getwd(),"results/image.png", sep="/"))
# img2 <- rgb(red=t(grayscale(img1[,,1,1]/255)),
# green=t(grayscale(img1[,,1,2]/255)), blue=t(grayscale(img1[,,1,3]/255)))
library(plotly)
# plot_ly(z=(img1[,,1,3]), type="heatmap", transpose=TRUE) %>%
# layout(title=paste0("Original Image, dim=(", dim(img1[,,1,3])[1], ", ",
# dim(img1[,,1,3])[2], ")"),
# xaxis=list(range=c(1, dim(img1[,,1,3])[1])),
# yaxis = list(range=c(1, dim(img1[,,1,3])[2]),
# autorange = "reversed", scaleanchor = "x")) %>%
# hide_colorbar()
# ar <- keras3::image_to_array(img)
ar <- image_to_array(img)
plot_ly(z=ar, type="image") %>%
layout(title=paste0("Original Image, dim=(", dim(ar[,,1])[1], ", ",
dim(ar[,,1])[2], ")"),
xaxis=list(range=c(1, dim(ar[,,1])[1])),
yaxis = list(range=c(1, dim(ar[,,1])[2]),
autorange = "reversed", scaleanchor = "x")) Before feeding the image to the deep learning network for
classification, we may need to do some preprocessing to make it
fit the network input requirements. This image preprocessing (e.g.,
cropping, intensity mean-centralization and scaling, etc.) can be done
manually in R. For example below is an instance of an
image-preprocessing function. In practice, we can also use the function
keras::imagenet_preprocess_input().
# library(imager) # for image resizing
preproc.image <-function(im) {
# # crop the image
# mean.img <- mean(im)
# shape <- dim(im)
# # short.edge <- min(shape[1:2])
# # xx <- floor((shape[1] - short.edge) / 2)
# # yy <- floor((shape[2] - short.edge) / 2)
# # resize to 224 x 224, needed by input of the model.
# #### resized <- resize(im, 224, 224)
#
# # take the first RGB-color channel; transpose to get it anatomically correct Viz
# img4 <- t(apply(im, 2, rev))
# # dim(img1)[1:2] # width and height of the original image
# olddim <- c(dim(img4)[1], dim(img4)[2])
# newdim <- c(224, 224) # new smaller image dimensions
# img5 <- array(img4, dim=c(dim(img4)[1], dim(img4)[2], 1, 1)) # 2D img --> 4D hyper-volume
#
# # resized <- resize(img5, size_x = newdim[1], size_y = newdim[2])
# # plot(resized)
#
# img6 <- resize(img5, size_x = newdim[1], size_y = newdim[2])
# # dim(img1) # [1] 64 64 1 1
# resized <- array(img6, dim=c(dim(img6)[1], dim(img6)[2])) # 4D hyper-volume --> 2D img
#
# plot_ly(z=(resized), type="heatmap", transpose=TRUE) %>%
# layout(title=paste0("Resized Image, dim=(", dim(resized)[1], ", ",
# dim(resized)[2], ")"),
# xaxis=list(range=c(1, dim(resized)[1])),
# yaxis = list(range=c(1, dim(resized)[2]),
# autorange = "reversed", scaleanchor = "x")) %>%
# hide_colorbar()
#
# # Reshape to format (width, height, channel, num)
# dim(resized) <- c(224, 224, 3, 1)
# return(resized)
# crop the image
mean.img <- mean(im)
shape <- dim(im)
resized <- resize(im, 224, 224)
# plot(resized)
# Reshape to format (width, height, channel, num)
dim(resized) <- c(224, 224, 3, 1)
return(resized)
}Here is an example of calling the preprocessing function to obtain a conforming (normalized) image ready for auto-classification.
8.3 Image Classification
Use the predict() function to get the probability
estimates over all (learned) classes and classify the image type.
# get info about local version of Python installation
# reticulate::py_config()
# The first time you run this install Pillow!
# tensorflow::install_tensorflow(extra_packages='pillow')
# Preprocess input image
x <- image_to_array(img)
# ensure we have a 4d tensor with single element in the first (batch) dimension,
# then preprocess the input for prediction using resnet50
x <- array_reshape(x, c(1, dim(x)))
x <- imagenet_preprocess_input(x) # note centralization: display(100*(x[1,,,1]+103))
# Specify and compare Predictions based on different Pre-trained Models
# Model 1: resnet50
model_resnet50 <- application_resnet50(weights = 'imagenet')
# make predictions then decode and print them
preds_resnet50 <- model_resnet50 %>% predict(x)## 1/1 - 1s - 520ms/epoch - 520ms/step## [[1]]
## class_name class_description score
## 1 n12985857 coral_fungus 0.38771829
## 2 n01943899 conch 0.23065260
## 3 n01910747 jellyfish 0.04777786
## 4 n01950731 sea_slug 0.03337501
## 5 n01514668 cock 0.02869991
## 6 n03887697 paper_towel 0.02394876
## 7 n07715103 cauliflower 0.01516685
## 8 n02643566 lionfish 0.01307990
## 9 n07753592 banana 0.01189900
## 10 n02869837 bonnet 0.01145932# Model2: VGG19
model_vgg19 <- application_vgg19(weights = 'imagenet')
preds_vgg19 <- model_vgg19 %>% predict(x)## 1/1 - 0s - 166ms/epoch - 166ms/step## class_name class_description score
## 1 n01943899 conch 0.9467045665
## 2 n04367480 swab 0.0158721227
## 3 n02869837 bonnet 0.0076282197
## 4 n03637318 lampshade 0.0073675090
## 5 n01704323 triceratops 0.0053689047
## 6 n02948072 candle 0.0024380954
## 7 n01910747 jellyfish 0.0024271661
## 8 n03485794 handkerchief 0.0022545208
## 9 n04325704 stole 0.0006817658
## 10 n02892767 brassiere 0.0006760275# Model 3: VGG16
model_vgg16 <- application_vgg16(weights = 'imagenet')
preds_vgg16 <- model_vgg16 %>% predict(x)## 1/1 - 0s - 141ms/epoch - 141ms/step## class_name class_description score
## 1 n02869837 bonnet 0.39209858
## 2 n03485794 handkerchief 0.21003944
## 3 n03637318 lampshade 0.11602377
## 4 n01910747 jellyfish 0.07897840
## 5 n04367480 swab 0.03536400
## 6 n04599235 wool 0.01766104
## 7 n04584207 wig 0.01763154
## 8 n03450230 gown 0.01549992
## 9 n04325704 stole 0.01439300
## 10 n03980874 poncho 0.01259298## [1] 1 1000The prob prediction generates a \(1000 \times 1\) array representing the
(vector) of probabilities reflecting the likelihood that the input image
resembles (is classified as) each of the top 1,000 known image
categories. We can report the indices of the top-10 closest image
classes to the input image.
Clearly, this US weather pattern image is not well classified by either of the three different deep networks. The optimal predictions include television, digital_clock, theater_curtain, etc., however, the prediction confidence is very low, \(Prob< 0.052\). None of the other top-10 class-labels capture the type of this weather-pattern image.
8.4 Additional Image Classification Examples
The machine learning image classification results won’t always be this poor. Let’s try classifying several alternative images.
8.4.1 Lake Mapourika, New Zealand
Let’s try the automated image classification of this lakeside panorama.
# load the image
download.file("https://upload.wikimedia.org/wikipedia/commons/2/23/Lake_mapourika_NZ.jpeg", paste(getwd(),"results/image.png", sep="/"), mode = 'wb')
img <- image_load(paste(getwd(),"results/image.png", sep="/"), target_size = c(224,224))
# imgRGB <- rgbImage(red=t(image_to_array(img)[,,1]/255),
# green=t(image_to_array(img)[,,2]/255), blue=t(image_to_array(img)[,,3]/255))
# display(imgRGB)
# img1 = load.image(paste(getwd(),"results/image.png", sep="/"))
#
# plot_ly(z=(img1[,,1,3]), type="heatmap", transpose=TRUE) %>%
# layout(title=paste0("Original Image, dim=(", dim(img1[,,1,3])[1], ", ",
# dim(img1[,,1,3])[2], ")"),
# xaxis=list(range=c(1, dim(img1[,,1,3])[1])), a
# yaxis = list(range=c(1, dim(img1[,,1,3])[2]),
# autorange = "reversed", scaleanchor = "x")) %>%
# hide_colorbar()
# ar <- keras3::image_to_array(img)
ar <- image_to_array(img)
plot_ly(z=ar, type="image") %>%
layout(title=paste0("Original Image, dim=(", dim(ar[,,1])[1], ", ",
dim(ar[,,1])[2], ")"),
xaxis=list(range=c(1, dim(ar[,,1])[1])),
yaxis = list(range=c(1, dim(ar[,,1])[2]),
autorange = "reversed", scaleanchor = "x")) # Preprocess input image
x <- image_to_array(img)
# ensure we have a 4d tensor with single element in the batch dimension,
# the preprocess the input for prediction using resnet50
x <- array_reshape(x, c(1, dim(x)))
x <- imagenet_preprocess_input(x)
# Specify and compare Predictions based on different Pre-trained Models
# Model 1: resnet50
model_resnet50 <- application_resnet50(weights = 'imagenet')
# make predictions then decode and print them
preds_resnet50 <- model_resnet50 %>% predict(x)## 1/1 - 1s - 517ms/epoch - 517ms/step## [[1]]
## class_name class_description score
## 1 n09332890 lakeside 0.6543879509
## 2 n02859443 boathouse 0.1122934818
## 3 n03216828 dock 0.0768113956
## 4 n02894605 breakwater 0.0713918880
## 5 n02951358 canoe 0.0646000579
## 6 n03873416 paddle 0.0125367241
## 7 n03160309 dam 0.0042035156
## 8 n09421951 sandbar 0.0010209975
## 9 n02980441 castle 0.0004615768
## 10 n03028079 church 0.0003251515# Model2: VGG19
model_vgg19 <- application_vgg19(weights = 'imagenet')
preds_vgg19 <- model_vgg19 %>% predict(x)## 1/1 - 0s - 167ms/epoch - 167ms/step## class_name class_description score
## 1 n09332890 lakeside 0.7257623076
## 2 n02894605 breakwater 0.2156526744
## 3 n02859443 boathouse 0.0240014996
## 4 n03216828 dock 0.0103707537
## 5 n03160309 dam 0.0092136264
## 6 n02951358 canoe 0.0068325307
## 7 n09421951 sandbar 0.0011575023
## 8 n04592741 wing 0.0009790066
## 9 n02814860 beacon 0.0005801014
## 10 n03873416 paddle 0.0004235524# Model 3: VGG16
model_vgg16 <- application_vgg16(weights = 'imagenet')
preds_vgg16 <- model_vgg16 %>% predict(x)## 1/1 - 0s - 143ms/epoch - 143ms/step## class_name class_description score
## 1 n09332890 lakeside 0.656819403
## 2 n02894605 breakwater 0.201263770
## 3 n03216828 dock 0.062172864
## 4 n02951358 canoe 0.021647597
## 5 n02859443 boathouse 0.016535964
## 6 n03160309 dam 0.014571159
## 7 n03873416 paddle 0.002511310
## 8 n04606251 wreck 0.001823977
## 9 n03874293 paddlewheel 0.001813032
## 10 n09421951 sandbar 0.001799422## [1] 1 1000This photo does represent a lakeside, which is reflected by the top three class labels:
- Model 1 (resnet50): lakeside, boathouse, dock, breakwater.
- Model 1 (VGG19): lakeside, breakwater, boathouse, dock.
- Model 1 (VGG16): lakeside, breakwater, dock, canoe.
8.4.2 Beach
Another coastal boundary between water and land is represented in this beach image.
{kind=link}
download.file("https://upload.wikimedia.org/wikipedia/commons/9/90/Holloways_beach_1920x1080.jpg", paste(getwd(),"results/image.png", sep="/"), mode = 'wb')
img <- image_load(paste(getwd(),"results/image.png", sep="/"), target_size = c(224,224))
# imgRGB <- rgbImage(red=t(image_to_array(img)[,,1]/255),
# green=t(image_to_array(img)[,,2]/255), blue=t(image_to_array(img)[,,3]/255))
# display(imgRGB)
# img1 = load.image(paste(getwd(),"results/image.png", sep="/"))
# ar <- keras3::image_to_array(img)
ar <- image_to_array(img)
plot_ly(z=ar, type="image") %>%
layout(title=paste0("Original Image, dim=(", dim(ar[,,1])[1], ", ",
dim(ar[,,1])[2], ")"),
xaxis=list(range=c(1, dim(ar[,,1])[1])),
yaxis = list(range=c(1, dim(ar[,,1])[2]),
autorange = "reversed", scaleanchor = "x")) # Preprocess input image
x <- image_to_array(img)
# ensure we have a 4d tensor with single element in the batch dimension,
# the preprocess the input for prediction using resnet50
x <- array_reshape(x, c(1, dim(x)))
x <- imagenet_preprocess_input(x)
# Specify and compare Predictions based on different Pre-trained Models
# Model 1: resnet50
model_resnet50 <- application_resnet50(weights = 'imagenet')
# make predictions then decode and print them
preds_resnet50 <- model_resnet50 %>% predict(x)## 1/1 - 1s - 515ms/epoch - 515ms/step## [[1]]
## class_name class_description score
## 1 n09421951 sandbar 0.5721773505
## 2 n09332890 lakeside 0.2440151274
## 3 n09428293 seashore 0.1711210161
## 4 n02894605 breakwater 0.0047327532
## 5 n09468604 valley 0.0014315870
## 6 n09399592 promontory 0.0010360115
## 7 n02951358 canoe 0.0010091875
## 8 n09288635 geyser 0.0006011428
## 9 n02859443 boathouse 0.0004151109
## 10 n04606251 wreck 0.0003732510# Model2: VGG19
model_vgg19 <- application_vgg19(weights = 'imagenet')
preds_vgg19 <- model_vgg19 %>% predict(x)## 1/1 - 0s - 162ms/epoch - 162ms/step## class_name class_description score
## 1 n09421951 sandbar 0.359485298
## 2 n09332890 lakeside 0.292689830
## 3 n09428293 seashore 0.286937028
## 4 n02894605 breakwater 0.013221879
## 5 n09468604 valley 0.011473650
## 6 n09399592 promontory 0.008166393
## 7 n09246464 cliff 0.002509698
## 8 n02951358 canoe 0.001916546
## 9 n09472597 volcano 0.001737528
## 10 n09288635 geyser 0.001652396# Model 3: VGG16
model_vgg16 <- application_vgg16(weights = 'imagenet')
preds_vgg16 <- model_vgg16 %>% predict(x)## 1/1 - 0s - 148ms/epoch - 148ms/step## class_name class_description score
## 1 n09421951 sandbar 0.508114815
## 2 n09332890 lakeside 0.275203556
## 3 n09428293 seashore 0.182308123
## 4 n02894605 breakwater 0.012498508
## 5 n09468604 valley 0.005356515
## 6 n09288635 geyser 0.002575647
## 7 n09399592 promontory 0.002403854
## 8 n09246464 cliff 0.001260779
## 9 n02951358 canoe 0.001242768
## 10 n09472597 volcano 0.001169216This photo was classified appropriately and with high-confidence as:
- sandbar.
- lakeside.
- seashore.
8.4.3 Volcano
Here is another natural image representing the Mount St. Helens Vocano.
{kind=link}
download.file("https://upload.wikimedia.org/wikipedia/commons/d/dc/MSH82_st_helens_plume_from_harrys_ridge_05-19-82.jpg", paste(getwd(),"results/image.png", sep="/"), mode = 'wb')
img <- image_load(paste(getwd(),"results/image.png", sep="/"), target_size = c(224,224))
# imgRGB <- rgbImage(red=t(image_to_array(img)[,,1]/255),
# green=t(image_to_array(img)[,,2]/255), blue=t(image_to_array(img)[,,3]/255))
# display(imgRGB)
# ar <- keras3::image_to_array(img)
ar <- image_to_array(img)
plot_ly(z=ar, type="image") %>%
layout(title=paste0("Original Image, dim=(", dim(ar[,,1])[1], ", ",
dim(ar[,,1])[2], ")"),
xaxis=list(range=c(1, dim(ar[,,1])[1])),
yaxis = list(range=c(1, dim(ar[,,1])[2]),
autorange = "reversed", scaleanchor = "x")) # Preprocess input image
x <- image_to_array(img)
# ensure we have a 4d tensor with single element in the batch dimension,
# the preprocess the input for prediction using resnet50
x <- array_reshape(x, c(1, dim(x)))
x <- imagenet_preprocess_input(x)
# Specify and compare Predictions based on different Pre-trained Models
# Model 1: resnet50
model_resnet50 <- application_resnet50(weights = 'imagenet')
# make predictions then decode and print them
preds_resnet50 <- model_resnet50 %>% predict(x)## 1/1 - 1s - 518ms/epoch - 518ms/step## [[1]]
## class_name class_description score
## 1 n09472597 volcano 9.999790e-01
## 2 n09193705 alp 1.989061e-05
## 3 n03792972 mountain_tent 6.250306e-07
## 4 n09288635 geyser 1.223144e-07
## 5 n02793495 barn 4.575289e-08
## 6 n04346328 stupa 4.022803e-08
## 7 n09468604 valley 2.443013e-08
## 8 n04228054 ski 2.035549e-08
## 9 n03773504 missile 1.580589e-08
## 10 n02361337 marmot 1.522739e-08# Model2: VGG19
model_vgg19 <- application_vgg19(weights = 'imagenet')
preds_vgg19 <- model_vgg19 %>% predict(x)## 1/1 - 0s - 165ms/epoch - 165ms/step## class_name class_description score
## 1 n09472597 volcano 9.997013e-01
## 2 n09193705 alp 2.804571e-04
## 3 n03792972 mountain_tent 1.027847e-05
## 4 n09288635 geyser 2.835764e-06
## 5 n04613696 yurt 1.629761e-06
## 6 n09468604 valley 7.795681e-07
## 7 n02793495 barn 5.885914e-07
## 8 n09246464 cliff 3.378958e-07
## 9 n04485082 tripod 3.340930e-07
## 10 n09332890 lakeside 2.207146e-07# Model 3: VGG16
model_vgg16 <- application_vgg16(weights = 'imagenet')
preds_vgg16 <- model_vgg16 %>% predict(x)## 1/1 - 0s - 145ms/epoch - 145ms/step## class_name class_description score
## 1 n09472597 volcano 9.999493e-01
## 2 n09193705 alp 4.656418e-05
## 3 n09288635 geyser 2.340611e-06
## 4 n03792972 mountain_tent 5.895651e-07
## 5 n09468604 valley 3.270904e-07
## 6 n02793495 barn 2.074526e-07
## 7 n04613696 yurt 1.601849e-07
## 8 n04592741 wing 1.294494e-07
## 9 n09332890 lakeside 6.953531e-08
## 10 n09246464 cliff 3.600639e-08The predicted top class labels for this image are perfect:
- volcano, alps.
- mountain_tent.
- geyser.
8.4.4 Brain Surface
The next image represents a 2D snapshot of 3D shape reconstruction of a brain cortical surface. This image is particularly difficult to automatically classify because (1) few people have ever seen a real brain, (2) the mathematical and computational models used to obtain the 2D manifold representing the brain surface do vary, and (3) the patterns of sulcal folds and gyral crests are quite inconsistent between people.
download.file("https://wiki.socr.umich.edu/images/e/ea/BrainCortex2.png", paste(getwd(),"results/image.png", sep="/"), mode = 'wb')
im <- load.image(paste(getwd(),"results/image.png", sep="/"))
download.file("https://wiki.socr.umich.edu/images/e/ea/BrainCortex2.png", paste(getwd(),"results/image.png", sep="/"), mode = 'wb')
img <- image_load(paste(getwd(),"results/image.png", sep="/"), target_size = c(224,224))
# imgRGB <- rgbImage(red=t(image_to_array(img)[,,1]/255),
# green=t(image_to_array(img)[,,2]/255), blue=t(image_to_array(img)[,,3]/255))
# display(imgRGB)
# ar <- keras3::image_to_array(img)
ar <- image_to_array(img)
plot_ly(z=ar, type="image") %>%
layout(title=paste0("Original Image, dim=(", dim(ar[,,1])[1], ", ",
dim(ar[,,1])[2], ")"),
xaxis=list(range=c(1, dim(ar[,,1])[1])),
yaxis = list(range=c(1, dim(ar[,,1])[2]),
autorange = "reversed", scaleanchor = "x")) # Preprocess input image
x <- image_to_array(img)
# ensure we have a 4d tensor with single element in the batch dimension,
# the preprocess the input for prediction using resnet50
x <- array_reshape(x, c(1, dim(x)))
x <- imagenet_preprocess_input(x)
# Specify and compare Predictions based on different Pre-trained Models
# Model 1: resnet50
model_resnet50 <- application_resnet50(weights = 'imagenet')
# make predictions then decode and print them
preds_resnet50 <- model_resnet50 %>% predict(x)## 1/1 - 1s - 539ms/epoch - 539ms/step## [[1]]
## class_name class_description score
## 1 n01917289 brain_coral 0.49230063
## 2 n03724870 mask 0.05837020
## 3 n03627232 knot 0.05785385
## 4 n07860988 dough 0.02824225
## 5 n02999410 chain 0.02761282
## 6 n13133613 ear 0.02136230
## 7 n01930112 nematode 0.01726645
## 8 n01955084 chiton 0.01705411
## 9 n04522168 vase 0.01611292
## 10 n03598930 jigsaw_puzzle 0.01429052# Model2: VGG19
model_vgg19 <- application_vgg19(weights = 'imagenet')
preds_vgg19 <- model_vgg19 %>% predict(x)## 1/1 - 0s - 164ms/epoch - 164ms/step## class_name class_description score
## 1 n01917289 brain_coral 0.48069364
## 2 n12267677 acorn 0.09673855
## 3 n07715103 cauliflower 0.07138763
## 4 n07760859 custard_apple 0.06029309
## 5 n03065424 coil 0.04491358
## 6 n03627232 knot 0.02875025
## 7 n01968897 chambered_nautilus 0.02850047
## 8 n03724870 mask 0.02178382
## 9 n01955084 chiton 0.01997963
## 10 n01943899 conch 0.01397448# Model 3: VGG16
model_vgg16 <- application_vgg16(weights = 'imagenet')
preds_vgg16 <- model_vgg16 %>% predict(x)## 1/1 - 0s - 141ms/epoch - 141ms/step## class_name class_description score
## 1 n01917289 brain_coral 0.878695130
## 2 n12267677 acorn 0.029935222
## 3 n13037406 gyromitra 0.019160040
## 4 n01968897 chambered_nautilus 0.011345789
## 5 n09256479 coral_reef 0.009584988
## 6 n07715103 cauliflower 0.009116886
## 7 n12985857 coral_fungus 0.008644850
## 8 n13052670 hen-of-the-woods 0.008409897
## 9 n07734744 mushroom 0.003213969
## 10 n01910747 jellyfish 0.003211512The top class labels for the brain image are:
- brain, coral.
- mask, knot.
- cauliflower.
- acorn.
Imagine if we can train a brain image classifier that labels individuals (volunteers or patients) solely based on their brain scans into different classes reflecting their development, clinical phenotypes, disease states, or aging profiles. This will require a substantial amount of expert-labeled brain scans, model training and extensive validation. However any progress in this direction will lead to effective computational clinical decision support systems that can assist physicians with diagnosis, tracking, and prognostication of brain growth and aging in health and disease.
8.5 Face mask: synthetic face image
We can also try the deep learning methods to see if they can uncover (recover) the core deterministic model or structure used to generate designed, synthetic, or simulated images.
This example is a synthetic computer-generated image representing a cartoon face or a mask.
download.file("https://wiki.socr.umich.edu/images/f/fb/FaceMask1.png", paste(getwd(),"results/image.png", sep="/"), mode = 'wb')
img <- image_load(paste(getwd(),"results/image.png", sep="/"), target_size = c(224,224))
# imgRGB <- rgbImage(red=t(image_to_array(img)[,,1]/255),
# green=t(image_to_array(img)[,,2]/255), blue=t(image_to_array(img)[,,3]/255))
# display(imgRGB)
# ar <- keras3::image_to_array(img)
ar <- image_to_array(img)
plot_ly(z=ar, type="image") %>%
layout(title=paste0("Original Image, dim=(", dim(ar[,,1])[1], ", ",
dim(ar[,,1])[2], ")"),
xaxis=list(range=c(1, dim(ar[,,1])[1])),
yaxis = list(range=c(1, dim(ar[,,1])[2]),
autorange = "reversed", scaleanchor = "x")) # Preprocess input image
x <- image_to_array(img)
# ensure we have a 4d tensor with single element in the batch dimension,
# the preprocess the input for prediction using resnet50
x <- array_reshape(x, c(1, dim(x)))
x <- imagenet_preprocess_input(x)
# Specify and compare Predictions based on different Pre-trained Models
# Model 1: resnet50
model_resnet50 <- application_resnet50(weights = 'imagenet')
# make predictions then decode and print them
preds_resnet50 <- model_resnet50 %>% predict(x)## 1/1 - 1s - 516ms/epoch - 516ms/step## [[1]]
## class_name class_description score
## 1 n06596364 comic_book 0.16772324
## 2 n02667093 abaya 0.11260407
## 3 n07248320 book_jacket 0.08875389
## 4 n02708093 analog_clock 0.08181556
## 5 n03724870 mask 0.07464802
## 6 n03314780 face_powder 0.06444784
## 7 n03590841 jack-o'-lantern 0.05559430
## 8 n03595614 jersey 0.04196474
## 9 n02992529 cellular_telephone 0.03123102
## 10 n03916031 perfume 0.02765943# Model2: VGG19
model_vgg19 <- application_vgg19(weights = 'imagenet')
preds_vgg19 <- model_vgg19 %>% predict(x)## 1/1 - 0s - 168ms/epoch - 168ms/step## class_name class_description score
## 1 n02708093 analog_clock 0.23986690
## 2 n03916031 perfume 0.10508911
## 3 n04548280 wall_clock 0.10344782
## 4 n04192698 shield 0.04367407
## 5 n03187595 dial_telephone 0.03604278
## 6 n04019541 puck 0.03236983
## 7 n03724870 mask 0.03026914
## 8 n02992529 cellular_telephone 0.01977265
## 9 n03314780 face_powder 0.01872789
## 10 n02865351 bolo_tie 0.01694269# Model 3: VGG16
model_vgg16 <- application_vgg16(weights = 'imagenet')
preds_vgg16 <- model_vgg16 %>% predict(x)## 1/1 - 0s - 142ms/epoch - 142ms/step## class_name class_description score
## 1 n02667093 abaya 0.404464394
## 2 n03724870 mask 0.182569608
## 3 n02708093 analog_clock 0.096874744
## 4 n04548280 wall_clock 0.062003084
## 5 n03045698 cloak 0.017887931
## 6 n03595614 jersey 0.014748766
## 7 n04370456 sweatshirt 0.010493519
## 8 n03584829 iron 0.009811899
## 9 n04286575 spotlight 0.008702856
## 10 n04584207 wig 0.008511132The top class labels for the face mask are:
- comic_book, mask.
- analog_clock.
- shield, abaya.
You can easily test the same image classifier on your own images and identify classes of pictures that are either well or poorly classified by the deep learning based machine learning model.
9 Data Generation: simulating synthetic data
9.1 Fractal shapes
One way to design fractal shapes is using iterated function systems (IFS). each IFS is represented by finite set of contraction mappings acting on complete metric spaces:
\[\{f_i : X \rightarrow X ∣ i=1,2,... , N\} , N \in \mathbb {N}.\] In the case of 2D sets and images, linear and contracting IFS’s can be represented as linear operators: \[f(x,y) = A \begin{bmatrix} x \\ y \end{bmatrix} + \begin{bmatrix} e \\ f \end{bmatrix} = \begin{bmatrix} a & b \\ c & d \end{bmatrix} \begin{bmatrix} x \\ y \end{bmatrix} + \begin{bmatrix} e \\ f \end{bmatrix}.\]
Computationally, these linear IFS contraction maps can be expressed as \(N\times 7\) matrices, where \(N\) is the number of maps and \(7\) is the number of parameters needed to describe an affine transformation in \(R^2\).
| map | \(A_{1,1}\) | \(A_{1,2}\) | \(A_{2,1}\) | \(A_{2,2}\) | \(B_{1}\) | \(B_{2}\) | probability |
|---|---|---|---|---|---|---|---|
| w | a | b | c | d | e | f | p |
Let’s take as an example Barnsley’s fern, which is designed to model real lady ferns (athyrium filix-femina). It can be defined by a set of \(N=4\) IFS contraction maps:
| map | \(A_{1,1}\) | \(A_{1,2}\) | \(A_{2,1}\) | \(A_{2,2}\) | \(B_{1}\) | \(B_{2}\) | probability | Fern Portion |
|---|---|---|---|---|---|---|---|---|
| \(f_1\) | 0 | 0 | 0 | 0.16 | 0 | 0 | 0.01 | Stem |
| \(f_2\) | 0.85 | 0.02 | −0.02 | 0.85 | 0 | 1.60 | 0.85 | Successively smaller leaflets |
| \(f_3\) | 0.20 | −0.26 | 0.23 | 0.22 | 0 | 1.60 | 0.1 | Largest left-hand leaflet |
| \(f_4\) | −0.15 | 0.28 | 0.26 | 0.24 | 0 | 0.44 | 0.05 | Largest right-hand leaflet |
Here is how the Barnsley Fern can be generated in R.
# Barnsley's Fern
# (1) create the 4-IFS functions of the probability and the current point
fractal_BarnsleyFern <- function(x, p){
if (p <= 0.01) {
A <- matrix(c(0, 0, 0, 0.16), 2, 2)
B <- c(0, 0)
} else if (p <= 0.86) {
A <- matrix(c(.85, -.02, .02, .85), 2, 2)
B <- c(0, 1.6)
} else if (p <= 0.95) {
A <- matrix(c(.2, .23, -.26, .22), 2, 2)
B <- c(0, 1.6)
} else {
A <- matrix(c(-.15, .26, .28, .24), 2, 2)
B <- c(0, .44)
}
return(A %*% x + B)
}
# Fern Resolution depends on the number of iterative applications of the IFS system
reps <- 100000
# create a vector with probability values, and a matrix to store coordinates
p <- runif(reps)
# initialize a point at the origin
init_coords <- c(0, 0)
# compute the list of reps fractal coordinates: (X,Y) pairs
A <- Reduce(fractal_BarnsleyFern, p, accumulate = T, init = init_coords)
A <- t(do.call(cbind, A)) # unwind the list of (X,Y) pairs as (reps * 2) array
# Plot
# plot(A, type = "p", cex = 0.1, col = "darkgreen",
# xlim = c(-3, 3), ylim = c(0, 15),
# xlab = NA, ylab = NA, axes = FALSE)
plot_ly(x=~A[,1], y=~A[,2], type="scatter", mode="markers", name="Barnsley's Fern",
marker = list(color = 'rgb(157, 255, 157)', size = 1))
# export Fern as JPG image
jpeg(paste(getwd(), sep="/", "results/FernPlot.jpg"))
plot(A, type = "p", cex = 0.1, col = "darkgreen", xlim = c(-3, 3), ylim = c(0, 15),
xlab = NA, ylab = NA, axes = FALSE)
dev.off()
# Load the image back in and test the DNN classification
img <- image_load(paste(getwd(),"results/FernPlot.jpg", sep="/"), target_size = c(224,224))
# Plot Fern
# Preprocess the Fern image and predict its class (label)
# imgRGB <- rgbImage(red=t(image_to_array(img)[,,1]/255),
# green=t(image_to_array(img)[,,2]/255), blue=t(image_to_array(img)[,,3]/255))
# display(imgRGB)
# ar <- keras3::image_to_array(img)
ar <- image_to_array(img)
plot_ly(z=ar, type="image") %>%
layout(title=paste0("Original Image, dim=(", dim(ar[,,1])[1], ", ",
dim(ar[,,1])[2], ")"),
xaxis=list(range=c(1, dim(ar[,,1])[1])),
yaxis = list(range=c(1, dim(ar[,,1])[2]),
autorange = "reversed", scaleanchor = "x"))
# Preprocess input image
x <- image_to_array(img)
# ensure we have a 4d tensor with single element in the batch dimension,
# the preprocess the input for prediction using resnet50
x <- array_reshape(x, c(1, dim(x)))
x <- imagenet_preprocess_input(x)
# Specify and compare Predictions based on different Pre-trained Models
# Model 1: resnet50
model_resnet50 <- application_resnet50(weights = 'imagenet')
# make predictions then decode and print them
preds_resnet50 <- model_resnet50 %>% predict(x)
imagenet_decode_predictions(preds_resnet50, top = 10)
# Model2: VGG19
model_vgg19 <- application_vgg19(weights = 'imagenet')
preds_vgg19 <- model_vgg19 %>% predict(x)
imagenet_decode_predictions(preds_vgg19, top = 10)[[1]]
# Model 3: VGG16
model_vgg16 <- application_vgg16(weights = 'imagenet')
preds_vgg16 <- model_vgg16 %>% predict(x)
imagenet_decode_predictions(preds_vgg16, top = 10)[[1]]9.2 Fake images
You can also try to use TensorFlow and
Keras to generate some “fake” synthetic images
that can be then classified. This can be accomplished by using a Generative
Adversarial network (GAN) to synthetically sample from a collection
of images like the MNIST image sets, e.g.,
keras::dataset_fashion_mnist, keras::cifar10,
and keras::dataset_mnist. See tutorial
1, tutorial
2, and this
R code for examples.
library(keras)
latent_dim <- 32
height <- 32
width <- 32
channels <- 3
generator_input <- layer_input(shape = c(latent_dim))
generator_output <- generator_input %>%
layer_dense(units = 128 * 16 * 16) %>%
layer_activation_leaky_relu() %>%
layer_reshape(target_shape = c(16, 16, 128)) %>%
layer_conv_2d(filters = 256, kernel_size = 5,
padding = "same") %>%
layer_activation_leaky_relu() %>%
layer_conv_2d_transpose(filters = 256, kernel_size = 4,
strides = 2, padding = "same") %>%
layer_activation_leaky_relu() %>%
layer_conv_2d(filters = 256, kernel_size = 5,
padding = "same") %>%
layer_activation_leaky_relu() %>%
layer_conv_2d(filters = 256, kernel_size = 5,
padding = "same") %>%
layer_activation_leaky_relu() %>%
layer_conv_2d(filters = channels, kernel_size = 7,
activation = "tanh", padding = "same")
generator <- keras_model(generator_input, generator_output)
discriminator_input <- layer_input(shape = c(height, width, channels))
discriminator_output <- discriminator_input %>%
layer_conv_2d(filters = 128, kernel_size = 3) %>%
layer_activation_leaky_relu() %>%
layer_conv_2d(filters = 128, kernel_size = 4, strides = 2) %>%
layer_activation_leaky_relu() %>%
layer_conv_2d(filters = 128, kernel_size = 4, strides = 2) %>%
layer_activation_leaky_relu() %>%
layer_conv_2d(filters = 128, kernel_size = 4, strides = 2) %>%
layer_activation_leaky_relu() %>%
layer_flatten() %>%
layer_dropout(rate = 0.4) %>%
layer_dense(units = 1, activation = "sigmoid")
discriminator <- keras_model(discriminator_input, discriminator_output)
discriminator_optimizer <- optimizer_rmsprop(
learning_rate = 0.0008,
clipvalue = 1.0,
# decay = 1e-8
momentum = 1 - 1e-8
)
discriminator %>% compile(
optimizer = discriminator_optimizer,
loss = "binary_crossentropy"
)
# freeze_weights(discriminator) 1
gan_input <- layer_input(shape = c(latent_dim))
gan_output <- discriminator(generator(gan_input))
gan <- keras_model(gan_input, gan_output)
gan_optimizer <- optimizer_rmsprop(
learning_rate = 0.0004,
clipvalue = 1.0,
# decay = 1e-8
momentum = 1 - 1e-8
)
gan %>% compile(
optimizer = gan_optimizer,
loss = "binary_crossentropy"
)
# mnist_fashion <- keras::dataset_fashion_mnist() # shape (num_samples, 28, 28)
cifar10 <- dataset_cifar10() # shape (num_samples, 3, 32, 32)
c(c(x_train, y_train), c(x_test, y_test)) %<-% cifar10
x_train <- x_train[as.integer(y_train) == 6,,,]
x_train <- x_train / 255
iterations <- 100
batch_size <- 20
save_dir <- getwd()
start <- 1
for (step in 1:iterations) {
random_latent_vectors <- matrix(rnorm(batch_size * latent_dim),
nrow = batch_size, ncol = latent_dim)
generated_images <- generator %>% predict(random_latent_vectors)
stop <- start + batch_size - 1
real_images <- x_train[start:stop,,,]
rows <- nrow(real_images)
combined_images <- array(0, dim = c(rows * 2, dim(real_images)[-1]))
combined_images[1:rows,,,] <- generated_images
combined_images[(rows+1):(rows*2),,,] <- real_images
labels <- rbind(matrix(1, nrow = batch_size, ncol = 1),
matrix(0, nrow = batch_size, ncol = 1))
labels <- labels + (0.5 * array(runif(prod(dim(labels))),
dim = dim(labels)))
d_loss <- discriminator %>% train_on_batch(combined_images, labels)
random_latent_vectors <- matrix(rnorm(batch_size * latent_dim),
nrow = batch_size, ncol = latent_dim)
misleading_targets <- array(0, dim = c(batch_size, 1))
a_loss <- gan %>% train_on_batch(
random_latent_vectors,
misleading_targets
)
start <- start + batch_size
if (start > (nrow(x_train) - batch_size))
start <- 1
if (step %% 10 == 0) {
# save_model_weights_hdf5(gan, "gan.h5")
# Status Reporting
cat("Completion Status: ", round((100*step)/iterations,0), "% \n")
cat("\t discriminator loss:", d_loss, "\n")
cat("\t adversarial loss:", a_loss, "\n")
# Optionally save the real/generated images
# image_array_save(generated_images[1,,,]*255,path=file.path(save_dir,paste0("generated_img",step,".png")))
# image_array_save(real_images[1,,,]*255,path = file.path(save_dir, paste0("real_img", step, ".png")))
}
}## 1/1 - 0s - 249ms/epoch - 249ms/step
## 1/1 - 0s - 209ms/epoch - 209ms/step
## 1/1 - 0s - 209ms/epoch - 209ms/step
## 1/1 - 0s - 203ms/epoch - 203ms/step
## 1/1 - 0s - 215ms/epoch - 215ms/step
## 1/1 - 0s - 196ms/epoch - 196ms/step
## 1/1 - 0s - 210ms/epoch - 210ms/step
## 1/1 - 0s - 215ms/epoch - 215ms/step
## 1/1 - 0s - 213ms/epoch - 213ms/step
## 1/1 - 0s - 213ms/epoch - 213ms/step
## Completion Status: 10 %
## discriminator loss: 143.0138
## adversarial loss: 198.4732
## 1/1 - 0s - 218ms/epoch - 218ms/step
## 1/1 - 0s - 211ms/epoch - 211ms/step
## 1/1 - 0s - 203ms/epoch - 203ms/step
## 1/1 - 0s - 205ms/epoch - 205ms/step
## 1/1 - 0s - 209ms/epoch - 209ms/step
## 1/1 - 0s - 207ms/epoch - 207ms/step
## 1/1 - 0s - 211ms/epoch - 211ms/step
## 1/1 - 0s - 207ms/epoch - 207ms/step
## 1/1 - 0s - 211ms/epoch - 211ms/step
## 1/1 - 0s - 208ms/epoch - 208ms/step
## Completion Status: 20 %
## discriminator loss: -54421.02
## adversarial loss: 1600006
## 1/1 - 0s - 208ms/epoch - 208ms/step
## 1/1 - 0s - 227ms/epoch - 227ms/step
## 1/1 - 0s - 213ms/epoch - 213ms/step
## 1/1 - 0s - 214ms/epoch - 214ms/step
## 1/1 - 0s - 220ms/epoch - 220ms/step
## 1/1 - 0s - 232ms/epoch - 232ms/step
## 1/1 - 0s - 233ms/epoch - 233ms/step
## 1/1 - 0s - 241ms/epoch - 241ms/step
## 1/1 - 0s - 247ms/epoch - 247ms/step
## 1/1 - 0s - 241ms/epoch - 241ms/step
## Completion Status: 30 %
## discriminator loss: -29509242
## adversarial loss: 497251584
## 1/1 - 0s - 237ms/epoch - 237ms/step
## 1/1 - 0s - 235ms/epoch - 235ms/step
## 1/1 - 0s - 232ms/epoch - 232ms/step
## 1/1 - 0s - 242ms/epoch - 242ms/step
## 1/1 - 0s - 231ms/epoch - 231ms/step
## 1/1 - 0s - 234ms/epoch - 234ms/step
## 1/1 - 0s - 240ms/epoch - 240ms/step
## 1/1 - 0s - 244ms/epoch - 244ms/step
## 1/1 - 0s - 247ms/epoch - 247ms/step
## 1/1 - 0s - 278ms/epoch - 278ms/step
## Completion Status: 40 %
## discriminator loss: -1283247872
## adversarial loss: 16928659456
## 1/1 - 0s - 237ms/epoch - 237ms/step
## 1/1 - 0s - 241ms/epoch - 241ms/step
## 1/1 - 0s - 251ms/epoch - 251ms/step
## 1/1 - 0s - 235ms/epoch - 235ms/step
## 1/1 - 0s - 242ms/epoch - 242ms/step
## 1/1 - 0s - 231ms/epoch - 231ms/step
## 1/1 - 0s - 242ms/epoch - 242ms/step
## 1/1 - 0s - 231ms/epoch - 231ms/step
## 1/1 - 0s - 233ms/epoch - 233ms/step
## 1/1 - 0s - 232ms/epoch - 232ms/step
## Completion Status: 50 %
## discriminator loss: -19234422784
## adversarial loss: 225663418368
## 1/1 - 0s - 218ms/epoch - 218ms/step
## 1/1 - 0s - 248ms/epoch - 248ms/step
## 1/1 - 0s - 245ms/epoch - 245ms/step
## 1/1 - 0s - 252ms/epoch - 252ms/step
## 1/1 - 0s - 232ms/epoch - 232ms/step
## 1/1 - 0s - 228ms/epoch - 228ms/step
## 1/1 - 0s - 241ms/epoch - 241ms/step
## 1/1 - 0s - 229ms/epoch - 229ms/step
## 1/1 - 0s - 238ms/epoch - 238ms/step
## 1/1 - 0s - 243ms/epoch - 243ms/step
## Completion Status: 60 %
## discriminator loss: -138249093120
## adversarial loss: 1.73687e+12
## 1/1 - 0s - 237ms/epoch - 237ms/step
## 1/1 - 0s - 236ms/epoch - 236ms/step
## 1/1 - 0s - 241ms/epoch - 241ms/step
## 1/1 - 0s - 227ms/epoch - 227ms/step
## 1/1 - 0s - 231ms/epoch - 231ms/step
## 1/1 - 0s - 234ms/epoch - 234ms/step
## 1/1 - 0s - 238ms/epoch - 238ms/step
## 1/1 - 0s - 231ms/epoch - 231ms/step
## 1/1 - 0s - 244ms/epoch - 244ms/step
## 1/1 - 0s - 227ms/epoch - 227ms/step
## Completion Status: 70 %
## discriminator loss: -879387344896
## adversarial loss: 9.267908e+12
## 1/1 - 0s - 220ms/epoch - 220ms/step
## 1/1 - 0s - 232ms/epoch - 232ms/step
## 1/1 - 0s - 232ms/epoch - 232ms/step
## 1/1 - 0s - 240ms/epoch - 240ms/step
## 1/1 - 0s - 241ms/epoch - 241ms/step
## 1/1 - 0s - 241ms/epoch - 241ms/step
## 1/1 - 0s - 251ms/epoch - 251ms/step
## 1/1 - 0s - 239ms/epoch - 239ms/step
## 1/1 - 0s - 231ms/epoch - 231ms/step
## 1/1 - 0s - 233ms/epoch - 233ms/step
## Completion Status: 80 %
## discriminator loss: -4.433029e+12
## adversarial loss: 3.898234e+13
## 1/1 - 0s - 238ms/epoch - 238ms/step
## 1/1 - 0s - 236ms/epoch - 236ms/step
## 1/1 - 0s - 243ms/epoch - 243ms/step
## 1/1 - 0s - 229ms/epoch - 229ms/step
## 1/1 - 0s - 243ms/epoch - 243ms/step
## 1/1 - 0s - 227ms/epoch - 227ms/step
## 1/1 - 0s - 245ms/epoch - 245ms/step
## 1/1 - 0s - 225ms/epoch - 225ms/step
## 1/1 - 0s - 243ms/epoch - 243ms/step
## 1/1 - 0s - 228ms/epoch - 228ms/step
## Completion Status: 90 %
## discriminator loss: -1.191096e+13
## adversarial loss: 1.353555e+14
## 1/1 - 0s - 236ms/epoch - 236ms/step
## 1/1 - 0s - 251ms/epoch - 251ms/step
## 1/1 - 0s - 242ms/epoch - 242ms/step
## 1/1 - 0s - 236ms/epoch - 236ms/step
## 1/1 - 0s - 229ms/epoch - 229ms/step
## 1/1 - 0s - 245ms/epoch - 245ms/step
## 1/1 - 0s - 228ms/epoch - 228ms/step
## 1/1 - 0s - 240ms/epoch - 240ms/step
## 1/1 - 0s - 227ms/epoch - 227ms/step
## 1/1 - 0s - 230ms/epoch - 230ms/step
## Completion Status: 100 %
## discriminator loss: -3.786194e+13
## adversarial loss: 4.084476e+14# Generated images are: generated_images[batch_size=20, x=32, y=32, channels=3]
# Upscale the last generated image 32*32 -> 128*128*
#### normed <- EBImage::resize(generated_images[10,,,2]*255, w = 224, h = 224)
library(imager) # for image resizing
# take the first RGB-color channel; transpose to get it anatomically correct Viz
img1 <- t(apply(generated_images[10,,,2]*255, 2, rev))
# dim(img1)[1:2] # width and height of the original image
olddim <- c(dim(img1)[1], dim(img1)[2])
newdim <- c(224, 224) # new smaller image dimensions
img2 <- array(img1, dim=c(dim(img1)[1], dim(img1)[2], 1, 1)) # 2D img --> 4D hyper-volume
normed <- resize(img2, size_x = newdim[1], size_y = newdim[2])
# image(normed, asp = 1, xaxt='n', yaxt='n', ann=FALSE, frame.plot=F)
# title(main = "Synthetic Image", font.main = 10)
plot_ly(z=~generated_images[15,,,1], type="contour", showscale=F)# plot_ly(z=~generated_images[10,,,2], type="image")
#convert the image to 4D
normed4D <- rbind (normed, normed, normed)
dim(normed4D) <- c(224, 224, 3, 1)
# predict class label of synth image (normed4D)
x <- image_to_array(img)
# ensure we have a 4d tensor with single element in the batch dimension,
# the preprocess the input for prediction using resnet50
x <- array_reshape(x, c(1, dim(x)))
x <- imagenet_preprocess_input(x)
# Specify and compare Predictions based on different Pre-trained Models
# Model 1: resnet50
model_resnet50 <- application_resnet50(weights = 'imagenet')
# make predictions then decode and print them
preds_resnet50 <- model_resnet50 %>% predict(x)## 1/1 - 1s - 531ms/epoch - 531ms/step## [[1]]
## class_name class_description score
## 1 n06596364 comic_book 0.16772324
## 2 n02667093 abaya 0.11260407
## 3 n07248320 book_jacket 0.08875389
## 4 n02708093 analog_clock 0.08181556
## 5 n03724870 mask 0.07464802
## 6 n03314780 face_powder 0.06444784
## 7 n03590841 jack-o'-lantern 0.05559430
## 8 n03595614 jersey 0.04196474
## 9 n02992529 cellular_telephone 0.03123102
## 10 n03916031 perfume 0.02765943Clearly this is a very simple image and the DNN classification is not expected to be very informative. The results reported above will vary with the draw of the randomly generated synthetic image.
10 Generative Adversarial Networks (GANs)
The articles Generating Sequences With Recurrent Neural Networks, by Alex Graves and Generative Adversarial Nets, by Goodfellow and colleagues, introduced a novel strategy to use recurrent neural networks to generate realistic signals, including audio generation (music, speech, dialogue), image generation, text-synthesis, and molecule design, etc. GANs represent an alternative strategy to variational auto-encoders (VAE) to generate synthetic data.
GAN frameworks estimate generative models using an adversarial process that simultaneously trains a pair of network models - a generative model \(G\) that captures the data distribution, and a separate discriminative model \(D\) that estimates the probability that a previously generated (synthetic) sample was real, i.e., came from the training data, rather than a synthetic \(G\) output.
For a binary classification, the \(G\) training maximizes the probability of \(D\) making a mistake (adversity), which corresponds to a mini-max optimization of a two-player game. The state space of all potential \(G\) and \(D\) permits a unique solution where \(G\) recovers the training data distribution and \(D=\frac{1}{2}\) is a constant, which corresponds to 50-50 change (largest entropy). Often, the \(G\) and \(D\) networks are defined as multilayer perceptrons (MLP) that can be jointly fit using backpropagation.
GAN learning requires iterative estimation of the generator’s distribution \(p_g\) using the training data \(x\), subject to some prior on noisy input latent variables \(Z\sim p_Z(z)\). Denote a generator mapping to the data space as \(G(z; \theta_g)\) where \(G\) is a differentiable function representing a multilayer perceptron network with parameters \(\theta_g\), and let the second multilayer perceptron network \(D(x; \theta_g)\) represents the output scalar probability that the input \(x\) came from the training data rather than from generator’s distribution \(p_g\).
The iterative NN modeling fitting (learning) involves:
- \(D\) maximization of the probability of assigning the correct labels (true=real or false=synthetic) to both types of inputs \(x\), either from training examples of synthetic samples from \(G\), and
- Simultaneous training \(G\) to minimize \(\log(1 −D(G(z)))\).
This dual optimization process for \(D\) and \(G\) corresponds to a two-player mini-max game with an objective value function \(V (G,D)\):
\[\min_G \max_D V (D,G) = \mathbb{E}_{x∼p_{data}(x)} [\log D(x)] + \mathbb{E}_{x∼p_{Z}(z)} [\log(1 −D(G(z)))]. \]
This training approach enables recovering the data generating distribution using numerical iterative approaches. Note that for finite datasets, a perfect optimization of \(D\) in the inner loop of training is computationally impractical and in general may result in overfitting. Therefore, the algorithm alternates the estimation process by performing \(k\) steps of optimizing \(D\) followed by \(1\) step of optimizing \(G\). When \(G\) updates change slowly, repeating this process yields \(D\) estimation near its optimal solution. In practice, direct gradient optimization of the objective value function \(V (G,D)\) may be insufficient to learn/estimate \(G\). Therefore, early in the learning process when \(G\) may be poorly estimated, \(D\) can reject samples with higher confidence because these early generations are expected to be obviously simple and fake, i.e., different from the training data and unrealistic, as for the early initial iterations, \(\log(1 −D(G(z)))\) may saturate. Therefore, in the early training process, rather than training \(G\) to minimize \(\log(1 −D(G(z)))\), the \(G\) training may focus on maximizing \(\log D(G(z))\). Eventually, we transition to minimizing the correct cost \(\log(1 −D(G(z)))\) and the final result of this dynamic optimization still has the same fixed point for \(G\) and \(D\), but provides stronger gradients early in the learning process.
10.1 CIFAR10 Archive
We show GAN training using CIFAR10 images, dataset of
50K \(32\times 32\) RGB images,
representing 10 classes (5K images per class). Let’s focus on
birds (label=2). All (low-resolution) images are of
dimension \(\left (\underbrace{32,
32}_{pixels}, \underbrace{3}_{RGB\ colors} \right )\). Note the
3-channel RGB intensities. Below is a \(10\times 10\) collage of the first 100 bird
images in the CIFAR10 archive.
library(keras)
library(tensorflow)
# install_tensorflow(version = "gpu")
# install_keras(tensorflow = "gpu")
# library(EBImage)
# CIFAR10 original labels: https://www.cs.toronto.edu/~kriz/cifar.html
# The label data is just a list of 10,000 numbers ranging from 0 to 9, which corresponds to each of the 10 classes in CIFAR-10.
# airplane : 0
# automobile : 1
# bird : 2
# cat : 3
# deer : 4
# dog : 5
# frog : 6
# horse : 7
# ship : 8
# truck : 9
# Focus on CIFAR10 BIRD images(label 2)!
# Loads CIFAR10 data
cifar10 <- dataset_cifar10()
c(c(x_train, y_train), c(x_test, y_test)) %<-% cifar10
# Selects bird images (class 2)
x_train <- x_train[as.integer(y_train) == 2,,,]
# Normalizes image intensities (bytes [0,255] --> [0,1])
x_train <- x_train / 255
# Display a grid of 10*10 Bird images
# img_real <- list()
# bird_images <- x_train[1:(10*10),,,]
# for (i in 1:10) {
# for (j in 1:10) {
# img_real[[i+ (j-1)*10]] <- rotate(rgbImage( # normalize the RGB values to [0,1] to use EBImage::display()
# normalize(bird_images[i+ (j-1)*10,,,1]), normalize(bird_images[i+ (j-1)*10,,,2]),
# normalize(bird_images[i+ (j-1)*10,,,3])), 90)
# }
# }
# img_comb = EBImage::combine(img_real)
# # Display the Bird images
# EBImage::display(img_comb, method="raster", all = TRUE)
#
# plt_list <- list()
# N=100
# for (i in 1:10) {
# for (j in 1:10) {
# plt_list[[i+(j-1)*10]] <-
# plot_ly(z=bird_images[i+ (j-1)*10,,,1], type="heatmap", showscale=FALSE) %>%
# layout(showlegend=FALSE, # hovermode = "y unified",
# xaxis=list(zeroline=F, showline=F, showticklabels=F, showgrid=F),
# yaxis=list(autorange = "reversed", zeroline=F,showline=F,showticklabels=F,showgrid=F)) #,
# # yaxis = list(scaleratio = 1, scaleanchor = 'x'))
# }
# }
#
# # plt_list[[2]]
# plt_list %>%
# subplot(nrows = 10, margin = 0.001, which_layout=1) %>%
# layout(title="CIFAR-10 - a collage of random birds")
bird_images <- x_train[1:(10*10),,,]
plt_list <- list()
N=100
for (i in 1:10) {
for (j in 1:10) {
plt_list[[i+(j-1)*10]] <-
plot_ly(z=255*bird_images[i+ (j-1)*10,,,], type="image", showscale=FALSE) %>%
layout(showlegend=FALSE, # hovermode = "y unified",
xaxis=list(zeroline=F, showline=F, showticklabels=F, showgrid=F),
yaxis=list(zeroline=F,showline=F,showticklabels=F,showgrid=F)) #,
# yaxis = list(scaleratio = 1, scaleanchor = 'x'))
}
}
# plt_list[[2]]
plt_list %>%
subplot(nrows = 10, margin = 0.0001, which_layout=1) %>%
layout(title="CIFAR-10 - a collage of random birds")10.2 Generator (\(G\))
Recall that the GAN represents a forger (adversarial) network \(G\) and an expert network \(D\) duking it out for superiority. Let’s first examine \(G\) and experiment with a generator network which takes a random vector input (a stochastic point in the latent space) and outputs a decoded synthetic image that is sent to the expert (discriminator) for auto-labeling.
We will demonstrate a keras implementation of GAN modeling using deep convolutional GAN (DCGAN). Both the generator \(G\) and discriminator \(D\) will be deep convnets.
The method layer_conv_2d_transpose() is used for image
upsampling in the generator. GAN model includes:
- A generator network \(G\) mapping vectors of shape (latent_dim) to (fake) RGB images of dimension \(\left (\underbrace{32, 32}_{pixels}, \underbrace{3}_{RGB\ colors} \right )\).
- A discriminator network \(D\) mapping images of the same dimension to a binary score estimating the probability that the image is real.
- A GAN network concatenating the generator and the discriminator
together:
gan(x) <- discriminator(generator(x))to map latent space vectors \(x\) to the discriminator decoding real/fake and an assessment of the realism of generator output images. - \(D\) is trained using examples of real and synthetic \(G\)-output images along with their corresponding “real”/”synth” labels.
- \(G\) training using the gradients of the generator’s weights reflecting the loss of the GAN objective function. At each iteration, these \(G\) weights are updated to optimize the cost function in a direction to improve \(D\) performance to correctly ID “real” and “synth” images supplied by the generator.
- To avoid getting the generator stuck with generating purely noisy images, we use dropout on both the discriminator and the generator.
10.3 Discriminator
The expert (Discriminator) network takes as input a real or synthetic image and outputs a label (or probability prediction) about the chance that the image came from the real training set or was synthetically created by the generator network (\(G\)).
\(G\) is trained to confuse the discriminator network \(D\) and evolve toward generating increasingly more realistic output images. As the number of training epochs increases, the artificially created images become similar to the real training data images.
Thus, \(D\) continuously adapts its neural network to increase the probability of catching fake images. However, this process also gradually improves the \(G\) capability to generate highly realistic output images. As the dual optimization process stabilizes and the training terminates, the generator is producing realistic images from random points in the state space, and the discriminator improves with detection of fakes.
Below is an implementation of a discriminator model taking a real or synthetic candidate image as input and outputting a classification label “generated (synth) image” or “real image from the training set”.
10.4 The adversarial network
10.5 Training the DCGAN
Just like most other deep learning processes, the deep convolutional GAN (GCGAN) design, training, and tuning involve significant scientific rigorous and artistry. The theoretical foundations are intertwined with heuristic approaches translating some intuition and human-intelligence into computational modeling. Some of the exemplary heuristics involved in DCGAN modeling and the implementation of the GAN generator and discriminator include:
- Using the \(\tanh()\) function in
the last activation of the generator, as opposed to the more standard
sigmoidfunction commonly employed in other types of DL models. - Random sampling points from the latent space rely on Gaussian (normal) distribution, rather than a high-entropy uniform distribution. This randomness and stochasticity during training yields more reliability and robustness in the final models.
- DCGAN training aims to achieve a dynamic equilibrium (tug-of-war between \(G\) and \(D\) nets). To ensure the GAN models avoid local minima (sub-optimal solutions), ), randomness is embedded in the training process. Stochasticity is introduced by using dropout in the discriminator (omitting or dropping out the feedback of each discriminator in the framework with some probability at the end of each batch) and by adding random noise to the labels for the discriminator.
- Sparse gradients can negatively impact the GAN training process.
Sparsity is often a desirable property in DL as it makes many
theoretically intractable computational problems solvable in practice.
Gradient sparsity in DCGANs is the result of (1) max-pooling
operations for calculating the largest value in each patch of each
feature map, i.e., down sampling or pooled feature maps to highlight the
most salient feature in the patch (instead of averaging the signal as is
the case of average pooling); or (2) ReLU activations
(rectified linear activation function, ReLU, is a piecewise linear
function that will output the input directly if it is positive,
otherwise, it will output zero).
Max-poolingcan be swapped with strided convolutions for downsampling. WhereasReLUactivation can be replaced bylayer_activation_leaky_relu, which is similar to ReLU, but it relaxes sparsity constraints by allowing small negative activation values. - The \(G\) generated output images
may exhibit checkerboard artifacts caused by unequal coverage of the
pixel space in the generator. This problem may be addressed by employing
a kernel of size divisible by the image stride size whenever we use a
strided
layer_conv_2d_transposeorlayer_conv_2din both the generator and the discriminator. The stride, or pitch, is the number of bytes from one row of pixels in memory to the next row of pixels in memory; the presence of padding bytes widens the stride relative to the width of the image.
Recall that stochastic gradient descent optimization facilitates iterative learning using a training dataset to update the learnt model at each iteration:
- The batch size is a hyperparameter of gradient descent that controls the number of training samples to work through before the model’s internal parameters are updated.
- The number of epochs is a hyperparameter of gradient descent that controls the number of complete passes through the training dataset.
Let’s demonstrate the synthetic image generation using the CIFAR10 imaging data archive of 10K images labeled in 10 different categories (e.g., airplanes, horses).
The example below just does 2 epochs. Increasing the iterations parameter (\(k\times 100\)) would generate more, and increasingly accurate synthetic images (in this case we are focusing on birds, label 2).
10.6 Elements of the DCGAN Training
The DCGAN training involves looping (iterating over each epoch) the following steps:
- Randomly traverse the latent space (introduce random noise by random sampling).
- Use \(G\) to generate images based on the random noise in the previous step.
- Mix the synth-generated images with real real-images (from training data).
- Train \(D\) to discriminate (label) these mixed images, outputting “real” or “fake” class labels.
- Again, randomly traverse the latent space drawing new random points (in the latent space).
- Train the DCGAN model using these random vectors, with a fixed target label=“real” for all images. This process updates only the network weights of the generator! The discriminator is static inside the GAN. Hence, these updates force the discriminator to predict “real images” for synthetically-generated images. This is the adversarial phase, as it trains the generator to fool the (frozen) discriminator.
- In the experiment below, we use a low number of
iterations <- 200. To generate more realistic results, this number needs to be much higher (e.g., \(10,000\)).
GPU computing Note: these DCGAN models are very computationally intensive. The performance is enhanced by installing CUDA Toolkit and NVIDIA cuDNN, which allow you to run the calculations on the GPU, instead of the default, CPU.
iterations <- 200 # 10000 increase to get better results (improved synthetic images)
# build the layout matrix with additional separating cells
nx <- 10 # number of images in a row
ny <- 10 # number of images in a column
batch_size <- 20
start <- 1
# List of nx*ny synthetic and real images (as matrices)
img_gan <- list()
#img_gan[[1]] <- x_train[1,,,1]; image(img_gan[[1]])
img_real <- list()
plt_list <- list()
for (step in 1:iterations) {
# First-tier sampling of random points in the latent space
random_latent_vectors <- matrix(rnorm(batch_size*latent_dim), nrow=batch_size, ncol=latent_dim)
# str(generated_images) (Batch-size, 2D-grid, RGB-colors)
# Array[1:20, 1:32, 1:32, 1:3]
# decode/generate and save synth-generated images
generated_images <- generator %>% predict(random_latent_vectors)
# Combine synth and real images
stop <- start + batch_size - 1
real_images <- x_train[start:stop,,,]
rows <- nrow(real_images)
combined_images <- array(0, dim = c(rows * 2, dim(real_images)[-1]))
combined_images[1:rows,,,] <- generated_images
combined_images[(rows+1):(rows*2),,,] <- real_images
# Assemble the labels discriminating synth from real images
labels <- rbind(matrix(1, nrow = batch_size, ncol = 1),
matrix(0, nrow = batch_size, ncol = 1))
# Add random noise to the image-labels to avoid trapping in local minima
labels <- labels + (0.5 * array(runif(prod(dim(labels))),
dim = dim(labels)))
# First, train the discriminator, $D$
d_loss <- discriminator %>% train_on_batch(combined_images, labels)
# Second-tier sampling of random points in the latent space
random_latent_vectors <- matrix(rnorm(batch_size*latent_dim), nrow = batch_size, ncol = latent_dim)
# Assemble labels = "real images” (fake incorrect labels)
misleading_targets <- array(0, dim = c(batch_size, 1))
# Second, train the generator $G$ using the GAN model. Note that the discriminator weights are fixed (static) during this optimization
a_loss <- gan %>% train_on_batch(
random_latent_vectors,
misleading_targets
)
start <- start + batch_size
if (start > (nrow(x_train) - batch_size)) start <- 1
# Display some of the generated images for visual inspection (number = iterations/(nx*ny))
if (step %% (nx*ny) == 0) {
# Save the GAN model weights in h5 format
save_model_weights_hdf5(gan, "gan.h5")
# Report metrics
cat("Step=", step, "; discriminator loss=", d_loss, "\n")
cat("Step=", step, "; adversarial loss=", a_loss, "\n")
# # Save one synth-generated image, Need to normalize the RGB values to [0,1]
# img_gan[[step/(nx*ny)]] <- rotate(rgbImage(generated_images[1,,,1],
# generated_images[1,,,2], generated_images[1,,,3]), 90) # Save one real (bird) image
# img_real[[step/(nx*ny)]] <- rotate(rgbImage(real_images[1,,,1],
# real_images[1,,,2], real_images[1,,,3]), 90)
# plot_ly rendering
pl1 <- plot_ly(z=255*real_images[step/(nx*ny), , , ], type="image") %>%
layout(showlegend=FALSE, # hovermode = "y unified",
xaxis=list(zeroline=F, showline=F, showticklabels=F, showgrid=F),
yaxis=list(zeroline=F,showline=F,showticklabels=F,showgrid=F))
pl2 <- plot_ly(z=255*generated_images[step/(nx*ny), , , ], type="image") %>%
layout(showlegend=FALSE, # hovermode = "y unified",
xaxis=list(zeroline=F, showline=F, showticklabels=F, showgrid=F),
yaxis=list(zeroline=F,showline=F,showticklabels=F,showgrid=F))
plt_list[[step/(nx*ny)]] <- subplot(pl1, pl2, nrows = 1, margin = 0.0001, which_layout=1)
}
}## 1/1 - 0s - 230ms/epoch - 230ms/step
## 1/1 - 0s - 199ms/epoch - 199ms/step
## 1/1 - 0s - 208ms/epoch - 208ms/step
## 1/1 - 0s - 217ms/epoch - 217ms/step
## 1/1 - 0s - 211ms/epoch - 211ms/step
## 1/1 - 0s - 202ms/epoch - 202ms/step
## 1/1 - 0s - 245ms/epoch - 245ms/step
## 1/1 - 0s - 234ms/epoch - 234ms/step
## 1/1 - 0s - 235ms/epoch - 235ms/step
## 1/1 - 0s - 248ms/epoch - 248ms/step
## 1/1 - 0s - 276ms/epoch - 276ms/step
## 1/1 - 0s - 250ms/epoch - 250ms/step
## 1/1 - 0s - 234ms/epoch - 234ms/step
## 1/1 - 0s - 242ms/epoch - 242ms/step
## 1/1 - 0s - 234ms/epoch - 234ms/step
## 1/1 - 0s - 238ms/epoch - 238ms/step
## 1/1 - 0s - 237ms/epoch - 237ms/step
## 1/1 - 0s - 225ms/epoch - 225ms/step
## 1/1 - 0s - 235ms/epoch - 235ms/step
## 1/1 - 0s - 247ms/epoch - 247ms/step
## 1/1 - 0s - 237ms/epoch - 237ms/step
## 1/1 - 0s - 236ms/epoch - 236ms/step
## 1/1 - 0s - 235ms/epoch - 235ms/step
## 1/1 - 0s - 234ms/epoch - 234ms/step
## 1/1 - 0s - 250ms/epoch - 250ms/step
## 1/1 - 0s - 249ms/epoch - 249ms/step
## 1/1 - 0s - 232ms/epoch - 232ms/step
## 1/1 - 0s - 239ms/epoch - 239ms/step
## 1/1 - 0s - 231ms/epoch - 231ms/step
## 1/1 - 0s - 234ms/epoch - 234ms/step
## 1/1 - 0s - 237ms/epoch - 237ms/step
## 1/1 - 0s - 235ms/epoch - 235ms/step
## 1/1 - 0s - 234ms/epoch - 234ms/step
## 1/1 - 0s - 224ms/epoch - 224ms/step
## 1/1 - 0s - 245ms/epoch - 245ms/step
## 1/1 - 0s - 246ms/epoch - 246ms/step
## 1/1 - 0s - 229ms/epoch - 229ms/step
## 1/1 - 0s - 228ms/epoch - 228ms/step
## 1/1 - 0s - 237ms/epoch - 237ms/step
## 1/1 - 0s - 251ms/epoch - 251ms/step
## 1/1 - 0s - 257ms/epoch - 257ms/step
## 1/1 - 0s - 268ms/epoch - 268ms/step
## 1/1 - 0s - 238ms/epoch - 238ms/step
## 1/1 - 0s - 255ms/epoch - 255ms/step
## 1/1 - 0s - 254ms/epoch - 254ms/step
## 1/1 - 0s - 251ms/epoch - 251ms/step
## 1/1 - 0s - 247ms/epoch - 247ms/step
## 1/1 - 0s - 258ms/epoch - 258ms/step
## 1/1 - 0s - 250ms/epoch - 250ms/step
## 1/1 - 0s - 275ms/epoch - 275ms/step
## 1/1 - 0s - 260ms/epoch - 260ms/step
## 1/1 - 0s - 266ms/epoch - 266ms/step
## 1/1 - 0s - 309ms/epoch - 309ms/step
## 1/1 - 0s - 256ms/epoch - 256ms/step
## 1/1 - 0s - 288ms/epoch - 288ms/step
## 1/1 - 0s - 306ms/epoch - 306ms/step
## 1/1 - 0s - 287ms/epoch - 287ms/step
## 1/1 - 0s - 315ms/epoch - 315ms/step
## 1/1 - 0s - 281ms/epoch - 281ms/step
## 1/1 - 0s - 246ms/epoch - 246ms/step
## 1/1 - 0s - 291ms/epoch - 291ms/step
## 1/1 - 0s - 268ms/epoch - 268ms/step
## 1/1 - 0s - 278ms/epoch - 278ms/step
## 1/1 - 0s - 255ms/epoch - 255ms/step
## 1/1 - 0s - 287ms/epoch - 287ms/step
## 1/1 - 0s - 256ms/epoch - 256ms/step
## 1/1 - 0s - 250ms/epoch - 250ms/step
## 1/1 - 0s - 252ms/epoch - 252ms/step
## 1/1 - 0s - 255ms/epoch - 255ms/step
## 1/1 - 0s - 255ms/epoch - 255ms/step
## 1/1 - 0s - 294ms/epoch - 294ms/step
## 1/1 - 0s - 280ms/epoch - 280ms/step
## 1/1 - 0s - 258ms/epoch - 258ms/step
## 1/1 - 0s - 262ms/epoch - 262ms/step
## 1/1 - 0s - 256ms/epoch - 256ms/step
## 1/1 - 0s - 311ms/epoch - 311ms/step
## 1/1 - 0s - 262ms/epoch - 262ms/step
## 1/1 - 0s - 265ms/epoch - 265ms/step
## 1/1 - 0s - 251ms/epoch - 251ms/step
## 1/1 - 0s - 247ms/epoch - 247ms/step
## 1/1 - 0s - 248ms/epoch - 248ms/step
## 1/1 - 0s - 257ms/epoch - 257ms/step
## 1/1 - 0s - 303ms/epoch - 303ms/step
## 1/1 - 0s - 250ms/epoch - 250ms/step
## 1/1 - 0s - 291ms/epoch - 291ms/step
## 1/1 - 0s - 259ms/epoch - 259ms/step
## 1/1 - 0s - 248ms/epoch - 248ms/step
## 1/1 - 0s - 255ms/epoch - 255ms/step
## 1/1 - 0s - 264ms/epoch - 264ms/step
## 1/1 - 0s - 257ms/epoch - 257ms/step
## 1/1 - 0s - 278ms/epoch - 278ms/step
## 1/1 - 0s - 278ms/epoch - 278ms/step
## 1/1 - 0s - 251ms/epoch - 251ms/step
## 1/1 - 0s - 247ms/epoch - 247ms/step
## 1/1 - 0s - 253ms/epoch - 253ms/step
## 1/1 - 0s - 257ms/epoch - 257ms/step
## 1/1 - 0s - 256ms/epoch - 256ms/step
## 1/1 - 0s - 269ms/epoch - 269ms/step
## 1/1 - 0s - 286ms/epoch - 286ms/step
## 1/1 - 0s - 277ms/epoch - 277ms/step
## Step= 100 ; discriminator loss= -1.48684e+14
## Step= 100 ; adversarial loss= 1.205321e+15
## 1/1 - 0s - 253ms/epoch - 253ms/step
## 1/1 - 0s - 249ms/epoch - 249ms/step
## 1/1 - 0s - 265ms/epoch - 265ms/step
## 1/1 - 0s - 259ms/epoch - 259ms/step
## 1/1 - 0s - 263ms/epoch - 263ms/step
## 1/1 - 0s - 258ms/epoch - 258ms/step
## 1/1 - 0s - 267ms/epoch - 267ms/step
## 1/1 - 0s - 263ms/epoch - 263ms/step
## 1/1 - 0s - 288ms/epoch - 288ms/step
## 1/1 - 0s - 256ms/epoch - 256ms/step
## 1/1 - 0s - 262ms/epoch - 262ms/step
## 1/1 - 0s - 257ms/epoch - 257ms/step
## 1/1 - 0s - 238ms/epoch - 238ms/step
## 1/1 - 0s - 243ms/epoch - 243ms/step
## 1/1 - 0s - 254ms/epoch - 254ms/step
## 1/1 - 0s - 242ms/epoch - 242ms/step
## 1/1 - 0s - 276ms/epoch - 276ms/step
## 1/1 - 0s - 253ms/epoch - 253ms/step
## 1/1 - 0s - 270ms/epoch - 270ms/step
## 1/1 - 0s - 248ms/epoch - 248ms/step
## 1/1 - 0s - 269ms/epoch - 269ms/step
## 1/1 - 0s - 268ms/epoch - 268ms/step
## 1/1 - 0s - 258ms/epoch - 258ms/step
## 1/1 - 0s - 236ms/epoch - 236ms/step
## 1/1 - 0s - 243ms/epoch - 243ms/step
## 1/1 - 0s - 240ms/epoch - 240ms/step
## 1/1 - 0s - 231ms/epoch - 231ms/step
## 1/1 - 0s - 240ms/epoch - 240ms/step
## 1/1 - 0s - 234ms/epoch - 234ms/step
## 1/1 - 0s - 237ms/epoch - 237ms/step
## 1/1 - 0s - 243ms/epoch - 243ms/step
## 1/1 - 0s - 235ms/epoch - 235ms/step
## 1/1 - 0s - 252ms/epoch - 252ms/step
## 1/1 - 0s - 232ms/epoch - 232ms/step
## 1/1 - 0s - 235ms/epoch - 235ms/step
## 1/1 - 0s - 236ms/epoch - 236ms/step
## 1/1 - 0s - 234ms/epoch - 234ms/step
## 1/1 - 0s - 240ms/epoch - 240ms/step
## 1/1 - 0s - 244ms/epoch - 244ms/step
## 1/1 - 0s - 234ms/epoch - 234ms/step
## 1/1 - 0s - 228ms/epoch - 228ms/step
## 1/1 - 0s - 232ms/epoch - 232ms/step
## 1/1 - 0s - 254ms/epoch - 254ms/step
## 1/1 - 0s - 244ms/epoch - 244ms/step
## 1/1 - 0s - 233ms/epoch - 233ms/step
## 1/1 - 0s - 239ms/epoch - 239ms/step
## 1/1 - 0s - 235ms/epoch - 235ms/step
## 1/1 - 0s - 229ms/epoch - 229ms/step
## 1/1 - 0s - 236ms/epoch - 236ms/step
## 1/1 - 0s - 234ms/epoch - 234ms/step
## 1/1 - 0s - 230ms/epoch - 230ms/step
## 1/1 - 0s - 225ms/epoch - 225ms/step
## 1/1 - 0s - 228ms/epoch - 228ms/step
## 1/1 - 0s - 227ms/epoch - 227ms/step
## 1/1 - 0s - 244ms/epoch - 244ms/step
## 1/1 - 0s - 234ms/epoch - 234ms/step
## 1/1 - 0s - 241ms/epoch - 241ms/step
## 1/1 - 0s - 234ms/epoch - 234ms/step
## 1/1 - 0s - 239ms/epoch - 239ms/step
## 1/1 - 0s - 240ms/epoch - 240ms/step
## 1/1 - 0s - 248ms/epoch - 248ms/step
## 1/1 - 0s - 248ms/epoch - 248ms/step
## 1/1 - 0s - 240ms/epoch - 240ms/step
## 1/1 - 0s - 234ms/epoch - 234ms/step
## 1/1 - 0s - 229ms/epoch - 229ms/step
## 1/1 - 0s - 230ms/epoch - 230ms/step
## 1/1 - 0s - 251ms/epoch - 251ms/step
## 1/1 - 0s - 221ms/epoch - 221ms/step
## 1/1 - 0s - 237ms/epoch - 237ms/step
## 1/1 - 0s - 245ms/epoch - 245ms/step
## 1/1 - 0s - 224ms/epoch - 224ms/step
## 1/1 - 0s - 234ms/epoch - 234ms/step
## 1/1 - 0s - 240ms/epoch - 240ms/step
## 1/1 - 0s - 236ms/epoch - 236ms/step
## 1/1 - 0s - 239ms/epoch - 239ms/step
## 1/1 - 0s - 240ms/epoch - 240ms/step
## 1/1 - 0s - 239ms/epoch - 239ms/step
## 1/1 - 0s - 245ms/epoch - 245ms/step
## 1/1 - 0s - 232ms/epoch - 232ms/step
## 1/1 - 0s - 234ms/epoch - 234ms/step
## 1/1 - 0s - 249ms/epoch - 249ms/step
## 1/1 - 0s - 305ms/epoch - 305ms/step
## 1/1 - 0s - 263ms/epoch - 263ms/step
## 1/1 - 0s - 249ms/epoch - 249ms/step
## 1/1 - 0s - 265ms/epoch - 265ms/step
## 1/1 - 0s - 264ms/epoch - 264ms/step
## 1/1 - 0s - 266ms/epoch - 266ms/step
## 1/1 - 0s - 260ms/epoch - 260ms/step
## 1/1 - 0s - 247ms/epoch - 247ms/step
## 1/1 - 0s - 261ms/epoch - 261ms/step
## 1/1 - 0s - 252ms/epoch - 252ms/step
## 1/1 - 0s - 267ms/epoch - 267ms/step
## 1/1 - 0s - 246ms/epoch - 246ms/step
## 1/1 - 0s - 242ms/epoch - 242ms/step
## 1/1 - 0s - 249ms/epoch - 249ms/step
## 1/1 - 0s - 242ms/epoch - 242ms/step
## 1/1 - 0s - 243ms/epoch - 243ms/step
## 1/1 - 0s - 252ms/epoch - 252ms/step
## 1/1 - 0s - 234ms/epoch - 234ms/step
## 1/1 - 0s - 245ms/epoch - 245ms/step
## Step= 200 ; discriminator loss= -3.940127e+17
## Step= 200 ; adversarial loss= 2.000919e+18# img_comb = EBImage::combine(c(img_real, img_gan))
# # Display the Bird images
# EBImage::display(img_comb, method="raster", all = TRUE)
# plt_list[[2]]
plt_list %>%
subplot(nrows = 2, margin = 0.0001, which_layout=1) %>%
layout(title="Observed (left) and Synthetic (right) Bird Images")The generator transforms random latent vectors into images. The discriminator attempts to correctly identify the real and synthetically-generated images. The generator is trained to fool the discriminator.
Iterative Protocol:
- Inputs: Random vector from the latent space
(
random_latent_vectors <- matrix(rnorm(batch_size * latent_dim), nrow = batch_size, ncol = latent_dim)) and Real Images (real_images[1,,,] * 255); - Generator (decoder) - receives Inputs and training feedback from Discriminator including real and synth images and their discriminated labels (real or synthetic);
- Generator outputs new synth (decoded) image that is sent along with another real image as input to the Discriminator below for another real vs. synth labeling
- Discriminator receives a pair of (real and synth) images as inputs, and outputs labels (real or synth) to them and forwards the results to generator
- This iterative process continues until a certain stopping criterion is reached.
The GAN (generator network) is iteratively trained and tuned to fool the discriminator network (i.e., pass synth images as real). This training cycle continues and the neural network evolves toward generating increasingly realistic images. Simulated artificial images begin to look indistinguishable from their real counterparts. The discriminator network becomes less effective in telling the two types of images apart. In this iterative process, the discriminator is constantly adapting to the gradually improving capabilities of the generator. This constant reinforcement yields realistic versions of synthetic computer-generated images. At the end of the training process, which is highly non-linear and discontinuous, the generator churns out input latent space points into realistic-looking images.
This DSPA2 module represents Part 1 of the DSPA2 Chapter 14 (Deep Learning, Neural Networks). Learners that complete this first part are encouraged to proceed to Part 2 of the DSPA2 Chapter 14 (Deep Learning, Neural Networks).
11 References
- Chollet and Allaire’s Deep Learning with R textbook (ISBN 9781617295546) and the corresponding code notebook
- Deep Neural Networks
- Google’s TensorFlow API
- Olaf Ronneberger, Philipp Fischer, Thomas Brox (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation, Medical Image Computing and Computer-Assisted Intervention (MICCAI), Springer, LNCS, Vol.9351: 234–241, 2015, arXiv:1505.04597.
This DSPA2 module represents Part 1 of the DSPA2 Chapter 14 (Deep Learning, Neural Networks). Learners that complete this first part are encouraged to proceed to Part 2 of the DSPA2 Chapter 14 (Deep Learning, Neural Networks), which starts with transfer learning, and then continue with Part 3 of the DSPA2 Chapter 14 (Deep Learning, Neural Networks) and Part 4 of the DSPA2 Chapter 14 (Deep Learning, Neural Networks).